|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Опубликован: 09.11.2009 | Доступ: свободный | Студентов: 4079 / 1033 | Оценка: 4.66 / 4.45 | Длительность: 54:13:00
Темы: Математика, Экономика
Специальности: Экономист
Теги:
Лекция 2:
Основы вероятностно-статистических методов описания неопределенностей
Дисперсия случайной величины. Математическое ожидание показывает, вокруг какой точки группируются значения случайной величины. Необходимо также уметь измерить изменчивость случайной величины относительно математического ожидания. Выше показано, что ![M[(X-a)^2]](/sites/default/files/tex_cache/c61414c4de506ffc32393024c2ab41f2.png) достигает минимума по
достигает минимума по  при
при 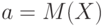 . Поэтому за показатель изменчивости случайной величины естественно взять именно
. Поэтому за показатель изменчивости случайной величины естественно взять именно ![M[(X-M(X))^2]](/sites/default/files/tex_cache/f62aa927df1c371217012201b279139c.png) .
.
Определение 5. Дисперсией случайной величины  называется число
называется число ![\sigma^2=D(X)=M\left[(X-M(X))^2\right]](/sites/default/files/tex_cache/30199ee3c0cc9c99054585ee5b7a4403.png) .
.
Установим ряд свойств дисперсии случайной величины, постоянно используемых в вероятностно-статистических методах принятия решений.
Утверждение 8. Пусть - случайная величина, и  - некоторые числа,
- некоторые числа, 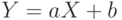 . Тогда
. Тогда  .
.
Как следует из утверждений 3 и 5,  . Следовательно,
. Следовательно, ![D(Y)=M[(Y-M(Y))^2] = M[(aX + b - aM(X) - b)^2] = M[a^2(X - M(X))^2]](/sites/default/files/tex_cache/84627e288e9c6c649e8f5e5835932fe7.png) . Поскольку постоянный множитель можно выносить за знак суммы, то
. Поскольку постоянный множитель можно выносить за знак суммы, то ![M[a^2(X - M(X))^2] = a^2 M[(X - M(X))^2] = a^2 D(X)](/sites/default/files/tex_cache/ea196e572d8f2394a01b59d8ce00a5f8.png) .
.
Утверждение 8 показывает, в частности, как меняется дисперсия результата наблюдений при изменении начала отсчета и единицы измерения. Оно дает правило преобразования расчетных формул при переходе к другим значениям параметров сдвига и масштаба.
Утверждение 9. Если случайные величины и  независимы, то дисперсия их суммы
независимы, то дисперсия их суммы  равна сумме дисперсий:
равна сумме дисперсий: 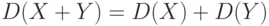 .
.
Для доказательства воспользуемся тождеством

которое вытекает из известной формулы элементарной алгебры 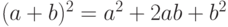 при подстановке
при подстановке  и
и  . Из утверждений 3 и 5 и определения дисперсии следует, что
. Из утверждений 3 и 5 и определения дисперсии следует, что

Согласно утверждению 6 из независимости и вытекает независимость 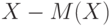 и
и 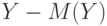 . Из утверждения 7 следует, что
. Из утверждения 7 следует, что
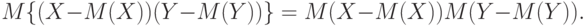
Поскольку 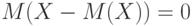 (см. утверждение 3), то правая часть последнего равенства равна 0, откуда с учетом двух предыдущих равенств и следует заключение утверждения 9.
(см. утверждение 3), то правая часть последнего равенства равна 0, откуда с учетом двух предыдущих равенств и следует заключение утверждения 9.
Утверждение 10. Пусть  - попарно независимые случайные величины (т.е.
- попарно независимые случайные величины (т.е.  и
и 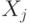 независимы, если
независимы, если 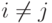 ). Пусть
). Пусть 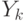 - их сумма,
- их сумма, 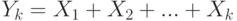 . Тогда математическое ожидание суммы равно сумме математических ожиданий слагаемых -
. Тогда математическое ожидание суммы равно сумме математических ожиданий слагаемых - 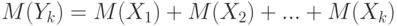 . Дисперсия суммы равна сумме дисперсий слагаемых,
. Дисперсия суммы равна сумме дисперсий слагаемых, 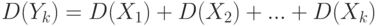 .
.
Соотношения, сформулированные в утверждении 10, являются основными при изучении выборочных характеристик, поскольку результаты наблюдений или измерений, включенные в выборку, обычно рассматриваются в математической статистике, теории принятия решений и эконометрике как реализации независимых случайных величин.
Для любого набора числовых случайных величин (не только независимых) математическое ожидание их суммы равно сумме их математических ожиданий. Это утверждение является обобщением утверждения 5. Строгое доказательство легко проводится методом математической индукции.
При выводе формулы для дисперсии  воспользуемся следующим свойством символа суммирования:
воспользуемся следующим свойством символа суммирования:
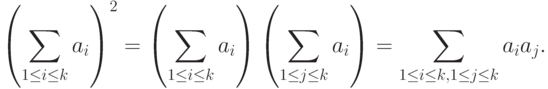
Положим 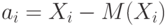 , получим
, получим
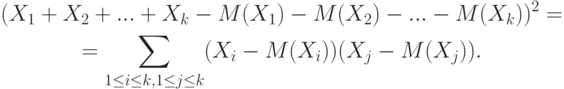
Воспользуемся теперь тем, что математическое ожидание суммы равно сумме математических ожиданий:
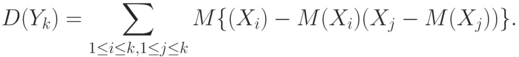 |
( 8) |
Как показано при доказательстве утверждения 9, из попарной независимости рассматриваемых случайных величин следует, что 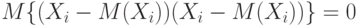 при . Следовательно, в сумме (8) остаются только члены с
при . Следовательно, в сумме (8) остаются только члены с 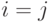 , а они равны как раз
, а они равны как раз 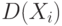 .
.
Полученные в утверждениях 8-10 фундаментальные свойства таких характеристик случайных величин, как математическое ожидание и дисперсия, постоянно используются практически во всех вероятностно-статистических моделях реальных явлений и процессов.
Пример 9. Рассмотрим событие  и случайную величину такую, что
и случайную величину такую, что 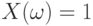 , если
, если 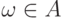 , и
, и  в противном случае, т.е. если
в противном случае, т.е. если  . Покажем, что
. Покажем, что 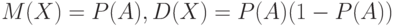 .
.
Воспользуемся формулой (5) для математического ожидания. Случайная величина принимает два значения - 0 и 1, значение 1 с вероятностью 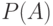 и значение 0 с вероятностью
и значение 0 с вероятностью  , а потому
, а потому 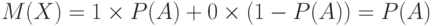 . Аналогично
. Аналогично 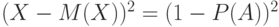 с вероятностью и
с вероятностью и 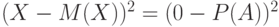 с вероятностью
с вероятностью 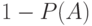 , а потому
, а потому 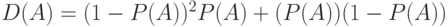 . Вынося общий множитель, получаем, что
. Вынося общий множитель, получаем, что 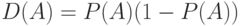 .
.
Пример 10. Рассмотрим  независимых испытаний, в каждом из которых некоторое событие может наступить, а может и не наступить. Введем случайные величины
независимых испытаний, в каждом из которых некоторое событие может наступить, а может и не наступить. Введем случайные величины 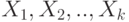 следующим образом:
следующим образом: 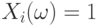 , если в
, если в  -ом испытании событие наступило, и
-ом испытании событие наступило, и 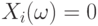 - в противном случае. Тогда случайные величины
- в противном случае. Тогда случайные величины 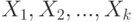 попарно независимы (см. пример 7). Как показано в примере 9,
попарно независимы (см. пример 7). Как показано в примере 9, 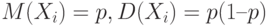 , где
, где 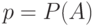 . Иногда
. Иногда  называют "вероятностью успеха" - в случае, если наступление события рассматривается как "успех".
называют "вероятностью успеха" - в случае, если наступление события рассматривается как "успех".
Случайная величина 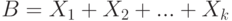 называется биномиальной. Ясно, что
называется биномиальной. Ясно, что 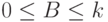 при всех возможных исходах опытов. Чтобы найти распределение
при всех возможных исходах опытов. Чтобы найти распределение 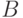 , т.е. вероятности
, т.е. вероятности 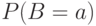 при
при 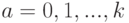 , достаточно знать - вероятность наступления рассматриваемого события в каждом из опытов. Действительно, случайное событие
, достаточно знать - вероятность наступления рассматриваемого события в каждом из опытов. Действительно, случайное событие 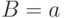 осуществляется тогда и только тогда, когда событие наступает ровно при испытаниях. Если известны номера всех этих испытаний (т.е. номера в последовательности испытаний), то вероятность одновременного осуществления в опытах события и в
осуществляется тогда и только тогда, когда событие наступает ровно при испытаниях. Если известны номера всех этих испытаний (т.е. номера в последовательности испытаний), то вероятность одновременного осуществления в опытах события и в 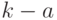 опытах противоположного ему - это вероятность произведения независимых событий.
Вероятность произведения равна произведению вероятностей, т.е.
опытах противоположного ему - это вероятность произведения независимых событий.
Вероятность произведения равна произведению вероятностей, т.е. 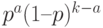 . Сколькими способами можно задать номера испытаний из ? Это
. Сколькими способами можно задать номера испытаний из ? Это 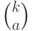 - число сочетаний из элементов по , рассматриваемое в комбинаторике. Как известно,
- число сочетаний из элементов по , рассматриваемое в комбинаторике. Как известно,
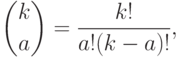
где символом ! обозначено произведение всех натуральных чисел от 1 до ,
т.е. 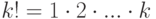 (дополнительно принимают, что 0! = 1). Из сказанного следует, что биномиальное распределение, т.е. распределение биномиальной случайной величины, имеет вид
(дополнительно принимают, что 0! = 1). Из сказанного следует, что биномиальное распределение, т.е. распределение биномиальной случайной величины, имеет вид
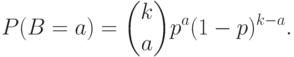
Название "биномиальное распределение" основано на том, что является членом с номером 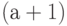 в разложении по биному Ньютона
в разложении по биному Ньютона

если положить 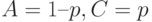 . Тогда при
. Тогда при 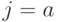 получим
получим
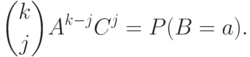
Для числа сочетаний из элементов по , кроме 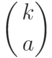 , используют обозначение
, используют обозначение 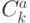 .
.
Из утверждения 10 и расчетов примера 9 следует, что для случайной величины , имеющей биномиальное распределение, математическое ожидание и дисперсия выражаются формулами
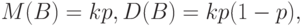
поскольку является суммой независимых случайных величин с одинаковыми математическими ожиданиями и дисперсиями, найденными в примере 9.
Неравенства Чебышева. Выше обсуждалась задача проверки того, что доля дефектной продукции в партии равна определенному числу. Для демонстрации вероятностно-статистического подхода к проверке подобных утверждений являются полезными неравенства, впервые примененные в теории вероятностей великим русским математиком Пафнутием Львовичем Чебышевым (1821–1894) и потому носящие его имя. Эти неравенства широко используются в теории математической статистики, а также непосредственно применяются в ряде практических задач принятия решений. Например, в задачах статистического анализа технологических процессов и качества продукции в случаях, когда явный вид функции распределения результатов наблюдений неизвестен (см. ниже, где, в частности, они применяются в задаче исключения резко отклоняющихся результатов наблюдений).
Первое неравенство Чебышева. Пусть - неотрицательная случайная величина (т.е.  для любого
для любого 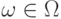 ). Тогда для любого положительного числа справедливо неравенство
). Тогда для любого положительного числа справедливо неравенство
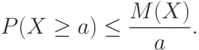
Доказательство. Все слагаемые в правой части формулы (4), определяющей математическое ожидание, в рассматриваемом случае неотрицательны. Поэтому при отбрасывании некоторых слагаемых сумма не увеличивается. Оставим в сумме только те члены, для которых 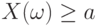 . Получим, что
. Получим, что
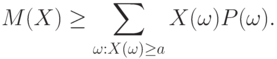 |
( 9) |
Для всех слагаемых в правой части (9) – , поэтому
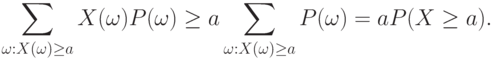 |
( 10) |
Из (9) и (10) следует требуемое.
Второе неравенство Чебышева. Пусть – случайная величина. Для любого положительного числа справедливо неравенство
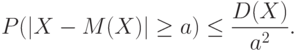
Это неравенство содержалось в работе П.Л.Чебышева "О средних величинах", доложенной Российской академии наук 17 декабря 1866 г. и опубликованной в следующем году.
Для доказательства второго неравенства Чебышева рассмотрим случайную величину 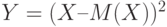 . Она неотрицательна, и потому для любого положительного числа , как следует из первого неравенства Чебышева, справедливо неравенство
. Она неотрицательна, и потому для любого положительного числа , как следует из первого неравенства Чебышева, справедливо неравенство
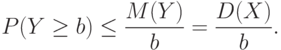
Положим 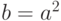 . Событие
. Событие 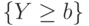 совпадает с событием
совпадает с событием 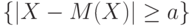 , а потому
, а потому
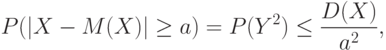
что и требовалось доказать.
Пример 11. Можно указать неотрицательную случайную величину и положительное число такие, что первое неравенство Чебышева обращается в равенство.
Достаточно рассмотреть 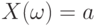 . Тогда
. Тогда 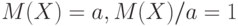 и
и  , т.е.
, т.е. 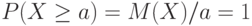 .
.
Следовательно, первое неравенство Чебышева в его общей формулировке не может быть усилено. Однако для подавляющего большинства случайных величин, используемых при вероятностно-статистическом моделировании процессов принятия решений, левые части неравенств Чебышева много меньше соответствующих правых частей.
Пример 12. Может ли первое неравенство Чебышева обращаться в равенство при всех ? Оказывается, нет. Покажем, что для любой неотрицательной случайной величины с ненулевым математическим ожиданием можно найти такое положительное число , что первое неравенство Чебышева является строгим.
Действительно, математическое ожидание неотрицательной случайной величины либо положительно, либо равно 0. В первом случае возьмем положительное , меньшее положительного числа 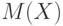 , например, положим
, например, положим 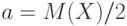 . Тогда
. Тогда  больше 1, в то время как вероятность события не может превышать 1, а потому первое неравенство Чебышева является для этого строгим. Второй случай исключается условиями примера 11.
больше 1, в то время как вероятность события не может превышать 1, а потому первое неравенство Чебышева является для этого строгим. Второй случай исключается условиями примера 11.
Отметим, что во втором случае равенство 0 математического ожидания влечет тождественное равенство 0 случайной величины. А для такой случайной величины при любом положительном и левая и правая части первого неравенства Чебышева равны 0.
Можно ли в формулировке первого неравенства Чебышева отбросить требование неотрицательности случайной величины ? А требование положительности ? Легко видеть, что ни одно из двух требований не может быть отброшено, поскольку иначе правая часть первого неравенства Чебышева может стать отрицательной.
Закон больших чисел. Неравенство Чебышева позволяет доказать замечательный результат, лежащий в основе математической статистики – закон больших чисел. Из него вытекает, что выборочные характеристики при возрастании числа опытов приближаются к теоретическим, а это дает возможность оценивать параметры вероятностных моделей по опытным данным. Без закона больших чисел не было бы большей части прикладной математической статистики.
Теорема Чебышева. Пусть случайные величины попарно независимы и существует число 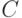 такое, что
такое, что 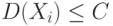 при всех
при всех 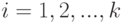 . Тогда для любого положительного
. Тогда для любого положительного 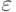 выполнено неравенство
выполнено неравенство
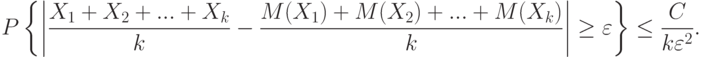 |
( 11) |
Доказательство. Рассмотрим случайные величины 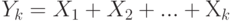 и
и  . Тогда согласно утверждению 10
. Тогда согласно утверждению 10
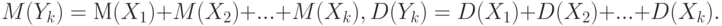
Из свойств математического ожидания следует, что 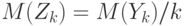 , а из свойств дисперсии –
, а из свойств дисперсии – 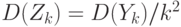 . Таким образом,
. Таким образом,
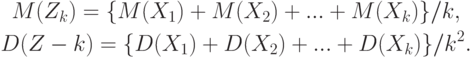
Из условия теоремы Чебышева следует, что

Применим к 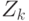 второе неравенство Чебышева. Получим для стоящей в левой части неравенства (11) вероятности оценку
второе неравенство Чебышева. Получим для стоящей в левой части неравенства (11) вероятности оценку
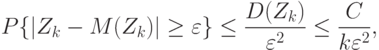
что и требовалось доказать.
Эта теорема была получена П.Л.Чебышевым в той же работе 1867 г. "О средних величинах", что и неравенства Чебышева.
Пример 13. Пусть 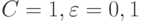 . При каких правая часть неравенства (11) не превосходит 0,1? 0,05? 0,00001?
. При каких правая часть неравенства (11) не превосходит 0,1? 0,05? 0,00001?
В рассматриваемом случае правая часть неравенства (11) равна 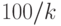 . Она не превосходит 0,1, если не меньше 1000, не превосходит 0,05, если не меньше 2000, не превосходит 0,00001, если не меньше 10 000 000.
. Она не превосходит 0,1, если не меньше 1000, не превосходит 0,05, если не меньше 2000, не превосходит 0,00001, если не меньше 10 000 000.
Правая часть неравенства (11), а вместе с ней и левая, при возрастании и фиксированных и убывает, приближаясь к 0. Следовательно, вероятность того, что среднее арифметическое независимых случайных величин отличается от своего математического ожидания менее чем на , приближается к 1 при возрастании числа случайных величин, причем при любом . Это утверждение называют ЗАКОНОМ БОЛЬШИХ ЧИСЕЛ.
Наиболее важен для вероятностно-статистических методов принятия решений (и для математической статистики в целом) случай, когда все  ., имеют одно и то же математическое ожидание
., имеют одно и то же математическое ожидание 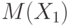 и одну и ту же дисперсию
и одну и ту же дисперсию 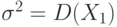 . В качестве замены (оценки) неизвестного исследователю математического ожидания используют выборочное среднее арифметическое
. В качестве замены (оценки) неизвестного исследователю математического ожидания используют выборочное среднее арифметическое
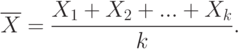
Из закона больших чисел следует, что  при увеличении числа опытов (испытаний, измерений) сколь угодно близко приближается к , что записывают так:
при увеличении числа опытов (испытаний, измерений) сколь угодно близко приближается к , что записывают так:
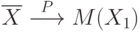
Здесь знак 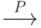 означает "сходимость по вероятности". Обратим внимание, что понятие "сходимость по вероятности" отличается от понятия "переход к пределу" в математическом анализе. Напомним, что последовательность
означает "сходимость по вероятности". Обратим внимание, что понятие "сходимость по вероятности" отличается от понятия "переход к пределу" в математическом анализе. Напомним, что последовательность 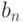 имеет предел при
имеет предел при 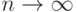 , если для любого сколь угодно малого
, если для любого сколь угодно малого 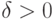 существует число
существует число 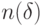 такое, что при любом
такое, что при любом 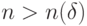 справедливо утверждение:
справедливо утверждение: 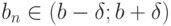 . При использовании понятия "сходимость по вероятности" элементы последовательности предполагаются случайными, вводится еще одно сколь угодно малое число
. При использовании понятия "сходимость по вероятности" элементы последовательности предполагаются случайными, вводится еще одно сколь угодно малое число 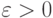 и утверждение предполагается выполненным не наверняка, а с вероятностью не менее
и утверждение предполагается выполненным не наверняка, а с вероятностью не менее 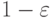 .
.
В начале лекции отмечалось, что с точки зрения ряда естествоиспытателей вероятность события – это число, к которому приближается отношение количества осуществлений события к количеству всех опытов при безграничном увеличении числа опытов. Известный математик Якоб Бернулли (1654–1705), живший в городе Базель в Швейцарии, в самом конце XVII века доказал это утверждение в рамках математической модели (опубликовано доказательство было лишь после его смерти в 1713 году). Современная формулировка теоремы Бернулли такова.
Теорема Бернулли. Пусть  – число наступлений события в независимых (попарно) испытаниях и есть вероятность наступления события в каждом из испытаний. Тогда при любом справедливо неравенство
– число наступлений события в независимых (попарно) испытаниях и есть вероятность наступления события в каждом из испытаний. Тогда при любом справедливо неравенство
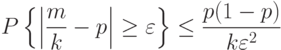 |
( 12) |
Доказательство. Как показано в примере 10, случайная величина имеет биномиальное распределение с вероятностью успеха и является суммой независимых случайных величин 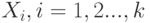 , каждое из которых равно 1 с вероятностью и 0 с вероятностью
, каждое из которых равно 1 с вероятностью и 0 с вероятностью 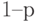 , т.е.
, т.е. 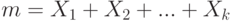 . Применим к
. Применим к 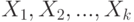 теорему Чебышева с
теорему Чебышева с 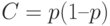 и получим требуемое неравенство (12).
и получим требуемое неравенство (12).
Теорема Бернулли дает возможность связать математическое определение вероятности (по А.Н. Колмогорову) с определением ряда естествоиспытателей (по Р. Мизесу (1883–1953), согласно которому вероятность есть предел частоты в бесконечной последовательности испытаний). Продемонстрируем эту связь. Для этого сначала отметим, что
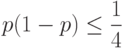
при всех . Действительно,
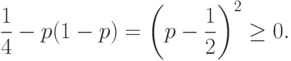
Следовательно, в теореме Чебышева можно использовать 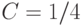 . Тогда при любом и фиксированном правая часть неравенства (12) при возрастании приближается к 0, что и доказывает согласие математического определения в рамках вероятностной модели с мнением естествоиспытателей.
. Тогда при любом и фиксированном правая часть неравенства (12) при возрастании приближается к 0, что и доказывает согласие математического определения в рамках вероятностной модели с мнением естествоиспытателей.
Есть и прямые экспериментальные подтверждения того, что частота осуществления определенных событий близка к вероятности, определенной из теоретических соображений. Рассмотрим бросания монеты. Поскольку и герб, и решетка имеют одинаковые шансы оказаться сверху, то вероятность выпадения герба равна 1/2 из соображений равновозможности. Французский естествоиспытатель XVIII века Бюффон бросил монету 4040 раз, герб выпал при этом 2048 раз. Частота появления герба в опыте Бюффона равна 0,507. Английский статистик К. Пирсон бросил монету 12000 раз и при этом наблюдал 6019 выпадений герба – частота 0,5016. В другой раз он бросил монету 24000 раз, герб выпал 12012 раз – частота 0,5005. Как видим, во всех этих случаях частоты лишь незначительно отличаются от теоретической вероятности 0,5 [ [ 2.3 ] , с.148].
О проверке статистических гипотез. С помощью неравенства (12) можно кое-что сказать по поводу проверки соответствия качества продукции заданным требованиям.
Пусть из 100000 единиц продукции 30000 оказались дефектными. Согласуется ли это с гипотезой о том, что вероятность дефектности равна 0,23? Прежде всего, какую вероятностную модель целесообразно использовать? Принимаем, что проводится сложный опыт, состоящий из 100000 испытаний 100000 единиц продукции на годность. Считаем, что испытания (попарно) независимы и что в каждом испытании вероятность того, что единица продукции является дефектной, равна . В реальном опыте получено, что событие "единица продукции не является годной" осуществилось 30000 раз при 100000 испытаниях. Согласуется ли это с гипотезой о том, что вероятность дефектности =0,23?
Для проверки гипотезы воспользуемся неравенством (12). В рассматриваемом случае 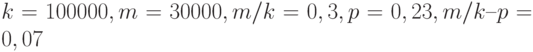 . Для проверки гипотезы поступим так. Оценим вероятность того, что
. Для проверки гипотезы поступим так. Оценим вероятность того, что 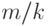 отличается от так же, как в рассматриваемом случае, или больше, т.е. оценим вероятность выполнения неравенства
отличается от так же, как в рассматриваемом случае, или больше, т.е. оценим вероятность выполнения неравенства  . Положим в неравенстве (12)
. Положим в неравенстве (12) 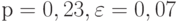 . Тогда
. Тогда
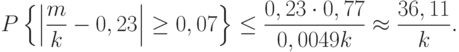 |
( 13) |
При = 100000 правая часть (13) меньше 1/2500. Значит, вероятность того, что отклонение будет не меньше наблюдаемого, весьма мала. Следовательно, если исходная гипотеза верна, то в рассматриваемом опыте осуществилось событие, вероятность которого меньше 1/2500. Поскольку 1/2500 – очень маленькое число, то исходную гипотезу надо отвергнуть.
Подробнее методы проверки статистических гипотез будут рассмотрены ниже. Здесь отметим, что одна из основных характеристик метода проверки гипотезы – уровень значимости, т.е. вероятность отвергнуть проверяемую гипотезу (ее в математической статистике называют нулевой и обозначают 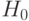 ), когда она верна. Для проверки статистической гипотезы часто поступают так. Выбирают уровень значимости – малое число
), когда она верна. Для проверки статистической гипотезы часто поступают так. Выбирают уровень значимости – малое число  . Если описанная в предыдущем абзаце вероятность меньше , то гипотезу отвергают, как говорят, на уровне значимости . Если эта вероятность больше или равна , то гипотезу принимают.
Обычно в вероятностно-статистических методах принятия решений выбирают =0,05, значительно реже =0,01 или =0,1, в зависимости от конкретной практической ситуации. В рассматриваемом случае , напомним, та доля опытов (т.е. проверок партий по 100000 единиц продукции), в которой мы отвергаем гипотезу
. Если описанная в предыдущем абзаце вероятность меньше , то гипотезу отвергают, как говорят, на уровне значимости . Если эта вероятность больше или равна , то гипотезу принимают.
Обычно в вероятностно-статистических методах принятия решений выбирают =0,05, значительно реже =0,01 или =0,1, в зависимости от конкретной практической ситуации. В рассматриваемом случае , напомним, та доля опытов (т.е. проверок партий по 100000 единиц продукции), в которой мы отвергаем гипотезу 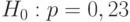 , хотя она верна.
, хотя она верна.
Насколько результат проверки гипотезы зависит от числа испытаний ? Пусть при 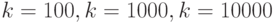 оказалось, что
оказалось, что  соответственно, так что во всех случаях
соответственно, так что во всех случаях 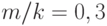 . Какие значения принимает вероятность
. Какие значения принимает вероятность
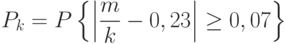
и ее оценка – правая часть формулы (13)?
При = 100 правая часть (13) равна приблизительно 0,36, что не дает оснований отвергнуть гипотезу. При = 1000 правая часть (13) равна примерно 0,036. Гипотеза отвергается на уровне значимости = 0,05 (и = 0,1), но на основе оценки вероятности с помощью правой части формулы (13) не удается отвергнуть гипотезу на уровне значимости = 0,01. При = 10000 правая часть (13) меньше 1/250, и гипотеза отвергается на всех обычно используемых уровнях значимости.
Более точные расчеты, основанные на применении центральной предельной теоремы теории вероятностей (см. ниже), дают 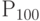 = 0,095,
= 0,095,  = 0,0000005, так что оценка (13) является в рассматриваемом случае весьма завышенной. Причина в том, что получена она из наиболее общих соображений, применительно ко всем возможным случайным величинам улучшить ее нельзя (см. пример 11 выше), но применительно к биномиальному распределению – можно.
= 0,0000005, так что оценка (13) является в рассматриваемом случае весьма завышенной. Причина в том, что получена она из наиболее общих соображений, применительно ко всем возможным случайным величинам улучшить ее нельзя (см. пример 11 выше), но применительно к биномиальному распределению – можно.
Ясно, что без введения уровня значимости не обойтись, ибо даже очень большие отклонения от  имеют положительную вероятность осуществления. Так, при справедливости гипотезы событие "все 100000 единиц продукции являются дефектными" отнюдь не является невозможным с математической точки зрения, оно имеет положительную вероятность осуществления, равную 0,23100000, хотя эта вероятность и невообразимо мала.
имеют положительную вероятность осуществления. Так, при справедливости гипотезы событие "все 100000 единиц продукции являются дефектными" отнюдь не является невозможным с математической точки зрения, оно имеет положительную вероятность осуществления, равную 0,23100000, хотя эта вероятность и невообразимо мала.
Аналогично разберем проверку гипотезы о симметричности монеты.
Пример 14. Если монета симметрична, то = 1/2, где – вероятность выпадения герба. Согласуется ли с этой гипотезой результат эксперимента, в котором при 10000 бросаниях выпало 4000 гербов?
В рассматриваемом случае 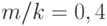 . Положим в неравенстве (12)
. Положим в неравенстве (12) 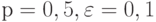 :
:
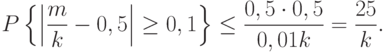
При = 10000 правая часть последнего неравенства равна 1/400. Значит, если исходная гипотеза верна, то в нашем единственном эксперименте осуществилось событие, вероятность которого весьма мала – меньше 1/400. Поэтому исходную гипотезу необходимо отвергнуть.
Если из 1000 бросаний монеты гербы выпали в 400 случаях, то правая часть выписанного выше неравенства равна 1/40. Гипотеза симметричности отклоняется на уровне значимости 0,05 (и 0,1), но рассматриваемые методы не дают возможности отвергнуть ее на уровне значимости 0,01.
Если = 100, а = 40, то правая часть неравенства равна 1/4. Оснований для отклонения гипотезы нет. С помощью более тонких методов, основанных на центральной предельной теореме теории вероятностей, можно показать, что левая часть неравенства равна приблизительно 0,05. Это показывает, как важно правильно выбрать метод проверки гипотезы или оценивания параметров. Следовательно, целесообразна стандартизация подобных методов, позволяющая сэкономить усилия, необходимые для сравнения и выбора наилучшего метода, а также избежать устаревших, неверных или неэффективных методов.
Ясно, что даже по нескольким сотням опытов нельзя достоверно отличить абсолютно симметричную монету ( = 1/2) от несколько несимметричной (для которой, скажем, = 0,49). Более того, любая реальная монета несколько несимметрична, так что монета с = 1/2 - математическая абстракция. Между тем в ряде управленческих и производственных ситуаций необходимо осуществить справедливую жеребьевку, а для этого требуется абсолютно симметричная монета. Например, речь может идти об очередности рассмотрения инвестиционных проектов комиссией экспертов, о порядке вызова для собеседования кандидатов на должность, об отборе единиц продукции из партии в выборку для контроля и т.п.
Пример 15. Можно ли с помощью несимметричной монеты получить последовательность испытаний с двумя исходами, каждый из которых имеет вероятность 1/2?
Ответ: да, можно. Приведем способ, предложенный видным польским математиком Гуго Штейнгаузом (1887–1972).
Будем бросать монету два раза подряд и записывать исходы бросаний так (Г – герб, Р – решетка, на первом месте стоит результат первого бросания, на втором – второго): ГР запишем как Г, в то время РГ запишем как Р, а ГГ и РР вообще не станем записывать. Например, если исходы бросаний окажутся такими –
ГР, РГ, ГР, РР, ГР, РГ, ГГ, РГ, РР, РГ,
то запишем их в виде:
Г, Р, Г, Г, Р, Р, Р.
Сконструированная таким образом последовательность обладает теми же свойствами, что и полученная при бросании идеально симметричной монеты, поскольку даже у несимметричной монеты последовательность ГР встречается столь же часто, как и последовательность РГ.
Применим теорему Бернулли и неравенство (12) к обработке реальных данных.
Пример 16. С 1871 г. по 1900 г. в Швейцарии родились 1359671 мальчиков и 1285086 девочек. Совместимы ли эти данные с предположением о том, что вероятность рождения мальчика равна 0,5? А с предположением, что она равна 0,515? Другими словами, требуется проверить нулевые гипотезы 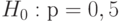 и
и  с помощью неравенства (12).
с помощью неравенства (12).
Число испытаний равно общему числу рождений, т.е. 1359671 + 1285086 = 2644757. Есть все основания считать испытания независимыми. Число рождений мальчиков составляет приблизительно 0,514 всех рождений. В случае  имеем
имеем 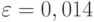 , и правая часть неравенства (12) имеет вид
, и правая часть неравенства (12) имеет вид
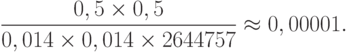
Таким образом, гипотезу 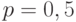 следует считать несовместимой с приведенными в условии данными. В случае
следует считать несовместимой с приведенными в условии данными. В случае 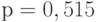 имеем
имеем 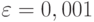 , и правая часть (12) равна приблизительно 0,1, так что с помощью неравенства (12) отклонить гипотезу
, и правая часть (12) равна приблизительно 0,1, так что с помощью неравенства (12) отклонить гипотезу  нельзя.
нельзя.
Итак, здесь на основе элементарной теории вероятностей (с конечным пространством элементарных событий) мы сумели построить вероятностные модели для описания проверки качества деталей (единиц продукции) и бросания монет и предложить методы проверки гипотез, относящихся к этим явлениям. В математической статистике есть более тонкие и сложные методы проверки описанных выше гипотез, которыми и пользуются в практических расчетах.
Можно спросить: "В рассмотренных выше моделях вероятности были известны заранее – со слов Струкова или же из-за того, что мы предположили симметричность монеты. А как строить модели, если вероятности неизвестны? Как оценить неизвестные вероятности?" Теорема Бернулли – результат, с помощью которого дается ответ на этот вопрос. Именно, оценкой неизвестной вероятности является число , поскольку доказано, что при возрастании вероятность того, что отличается от более чем на какое-либо фиксированное число, приближается к 0. Оценка будет тем точнее, чем больше . Более того, можно доказать, что с некоторой точки зрения (см. далее) оценка для вероятности является наилучшей из возможных (в терминах математической статистики – состоятельной, несмещенной и эффективной).
Анастасия Маркова