|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Опубликован: 09.11.2009 | Доступ: свободный | Студентов: 4113 / 1048 | Оценка: 4.66 / 4.45 | Длительность: 54:13:00
Темы: Математика, Экономика
Специальности: Экономист
Лекция 6:
Оценивание
Аннотация: В лекции рассматриваются различные методы оценивания параметров, в том числе метод моментов, максимального правдоподобия, одношаговые оценки, а также задача параметрической регрессии. Затрагиваются вопросы робастности статистических процедур.
Ключевые слова: размерность, пространство, евклидово пространство, значение, множитель, функция, ПО, статистика, выборка, доказательство, параметр, коэффициент вариации, вектор, математическим ожиданием, случайная величина, линеаризация, место, бесконечно малая величина, робастность, равенство, оценивание, выборочной средней, дисперсия, сочетания, статистическая гипотеза, доверительная вероятность, оценка максимального правдоподобия, выражение, класс, определение, биномиальное распределение, Произведение, логарифмическая функция правдоподобия, сходимость, локальный максимум, итерационный алгоритм, точность, группа, евклидово расстояние, метод Ньютона, матрица, нормальный закон, Единичная матрица, итерация, оценка векторов, эквивалентность, уравнение правдоподобия, системы нелинейных уравнений, координаты, отношение, коэффициент асимметрии, метод статистических испытаний, программное обеспечение, доказательство теорем, задачу аппроксимации, натуральное число, метода наименьших квадратов, минимум, очередь, мера, интеграл, числитель, компонент, минимизация, вычисление, предел, анализ данных, отрезок, прямой, грани, коэффициент корреляции, коэффициенты, целый, интервал, погрешность
6.1. Методы оценивания параметров
В прикладной статистике используются разнообразные параметрические модели. Термин "параметрический" означает, что вероятностно-статистическая модель полностью описывается конечномерным вектором фиксированной размерности. Причем эта размерность не зависит от объема выборки.
Рассмотрим выборку 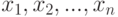 из распределения с плотностью
из распределения с плотностью 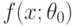 , где - элемент параметрического семейства плотностей распределения вероятностей
, где - элемент параметрического семейства плотностей распределения вероятностей  . Здесь
. Здесь  - заранее известное
- заранее известное  -мерное пространство параметров, являющееся подмножеством евклидова пространства
-мерное пространство параметров, являющееся подмножеством евклидова пространства 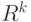 , а конкретное значение параметра
, а конкретное значение параметра 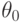 статистику неизвестно. Обычно в прикладной статистике применяются параметрические семейства с
статистику неизвестно. Обычно в прикладной статистике применяются параметрические семейства с  (см.
"Основы вероятностно-статистических методов описания неопределенностей"
). В статистике нечисловых данных вместо плотности часто рассматриваются вероятности попадания в точки. Напомним, что в параметрических задачах оценивания принимают вероятностную модель, согласно которой результаты наблюдений рассматривают как реализации n независимых случайных величин.
(см.
"Основы вероятностно-статистических методов описания неопределенностей"
). В статистике нечисловых данных вместо плотности часто рассматриваются вероятности попадания в точки. Напомним, что в параметрических задачах оценивания принимают вероятностную модель, согласно которой результаты наблюдений рассматривают как реализации n независимых случайных величин.
Задача оценивания состоит в том, чтобы оценить неизвестное статистику значение параметра наилучшим (в каком-либо смысле) образом.
Пример 1. В статистических задачах стандартизации и управления качеством используют семейство гамма-распределений. Плотность гамма-распределения имеет вид
![f(x; a,b,c)=
\left\{
\begin{gathered}
\frac{1}{\Gamma(a)}(x-c)^{a-1}b^{-a}\exp\left[-\frac{x-c}{b}\right],x\ge c, \\
0,\quad x< c.
\end{gathered}
\right.](/sites/default/files/tex_cache/7a9423952c89048d85deac8ed1c34f87.png) |
( 1) |
Плотность вероятности в формуле (1) определяется тремя параметрами 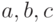 , где
, где 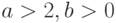 . При этом
. При этом  является параметром формы,
является параметром формы,  - параметром масштаба и
- параметром масштаба и  - параметром сдвига. Множитель
- параметром сдвига. Множитель 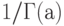 является нормировочным, он введен, чтобы
является нормировочным, он введен, чтобы

Здесь 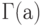 - одна из используемых в математике специальных функций, так называемая "гамма-функция", по которой названо и распределение, задаваемое формулой (1),
- одна из используемых в математике специальных функций, так называемая "гамма-функция", по которой названо и распределение, задаваемое формулой (1),
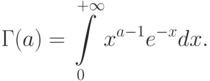
Подробные решения задач оценивания параметров для гамма-распределения содержатся в разработанном нами государственном стандарте ГОСТ 11.011-83 "Прикладная статистика. Правила определения оценок и доверительных границ для параметров гамма-распределения" [ [ 6.6 ] ]. В настоящее время эта публикация используется в качестве методического материала для инженерно-технических работников промышленных предприятий и прикладных научно-исследовательских институтов.
Поскольку гамма-распределение зависит от трех параметров, то имеется 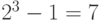 вариантов постановок задач оценивания. Они описаны в табл.6.1.
вариантов постановок задач оценивания. Они описаны в табл.6.1.
| № п/п | Параметр формы | Параметр масштаба | Параметр сдвига |
|---|---|---|---|
| 1 | Известен | Оценивается | Известен |
| 2 | Оценивается | Известен | Известен |
| 3 | Известен | Известен | Оценивается |
| 4 | Оценивается | Оценивается | Известен |
| 5 | Известен | Оценивается | Оценивается |
| 6 | Оценивается | Известен | Оценивается |
| 7 | Оценивается | Оценивается | Оценивается |
В табл.6.2 приведены реальные данные о наработке резцов до предельного состояния, в часах. Упорядоченная выборка (вариационный ряд) объема  взята из государственного стандарта [
[
6.6
]
]. Проверка согласия данных о наработке резцов с семейством гамма-распределений проведена в
"Проверка гипотез"
. Именно эти данные будут служить исходным материалом для демонстрации тех или иных методов оценивания параметров.
взята из государственного стандарта [
[
6.6
]
]. Проверка согласия данных о наработке резцов с семейством гамма-распределений проведена в
"Проверка гипотез"
. Именно эти данные будут служить исходным материалом для демонстрации тех или иных методов оценивания параметров.
| № п/п | Наработка | № п/п | Наработка | № п/п | Наработка |
|---|---|---|---|---|---|
| 1 | 9 | 18 | 47,5 | 35 | 63 |
| 2 | 17,5 | 19 | 48 | 36 | 64,5 |
| 3 | 21 | 20 | 50 | 37 | 65 |
| 4 | 26,5 | 21 | 51 | 38 | 67,5 |
| 5 | 27,5 | 22 | 53,5 | 39 | 68,5 |
| 6 | 31 | 23 | 55 | 40 | 70 |
| 7 | 32,5 | 24 | 56 | 41 | 72,5 |
| 8 | 34 | 25 | 56 | 42 | 77,5 |
| 9 | 36 | 26 | 56,5 | 43 | 81 |
| 10 | 36,5 | 27 | 57,5 | 44 | 82,5 |
| 11 | 39 | 28 | 58 | 45 | 90 |
| 12 | 40 | 29 | 59 | 46 | 96 |
| 13 | 41 | 30 | 59 | 47 | 101,5 |
| 14 | 42,5 | 31 | 60 | 48 | 117,5 |
| 15 | 43 | 32 | 61 | 49 | 127,5 |
| 16 | 45 | 33 | 61,5 | 50 | 130 |
| 17 | 46 | 34 | 62 |
Выбор "наилучших" оценок в определенной параметрической модели прикладной статистики - научно-исследовательская работа, растянутая во времени. Выделим два этапа. Этап асимптотики: оценки строятся и сравниваются по их свойствам при безграничном росте объема выборки. На этом этапе рассматривают такие характеристики оценок, как состоятельность, асимптотическая эффективность и др. Этап конечных объемов выборки: оценки сравниваются, скажем, при 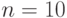 . Ясно, что исследование начинается с этапа асимптотики: чтобы сравнивать оценки, надо сначала их построить и быть уверенными, что они не являются абсурдными (такую уверенность дает доказательство состоятельности).
. Ясно, что исследование начинается с этапа асимптотики: чтобы сравнивать оценки, надо сначала их построить и быть уверенными, что они не являются абсурдными (такую уверенность дает доказательство состоятельности).
С какой оценки начинать? Одним из наиболее известных и простых в употреблении методов является метод моментов. Название связано с тем, что этот метод опирается на использование выборочных моментов
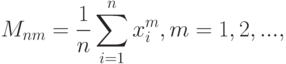
где 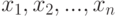 - выборка, т.е. набор независимых одинаково распределенных случайных величин с числовыми значениями.
- выборка, т.е. набор независимых одинаково распределенных случайных величин с числовыми значениями.
В прикладной статистике метод анализа данных называется методом моментов, если он использует статистику
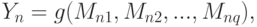 |
( 2) |
где 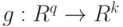 - некоторая функция (здесь - число неизвестных числовых параметров). Чаще всего термин "метод моментов" используют, когда речь идет об оценивании параметров. В этом случае обычно предполагают, что плотность вероятности распределения элементов выборки
- некоторая функция (здесь - число неизвестных числовых параметров). Чаще всего термин "метод моментов" используют, когда речь идет об оценивании параметров. В этом случае обычно предполагают, что плотность вероятности распределения элементов выборки 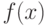 входит в заранее известное статистику параметрическое семейство
входит в заранее известное статистику параметрическое семейство 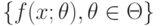 , т.е.
, т.е.  при некотором . Здесь - заранее заданное -мерное пространство параметров, являющееся подмножеством евклидова пространства , а конкретное значение параметра статистику неизвестно, его и следует оценить. Известно также, что неизвестный параметр определяется с помощью известной статистику функции через начальные моменты элементов выборки:
при некотором . Здесь - заранее заданное -мерное пространство параметров, являющееся подмножеством евклидова пространства , а конкретное значение параметра статистику неизвестно, его и следует оценить. Известно также, что неизвестный параметр определяется с помощью известной статистику функции через начальные моменты элементов выборки:
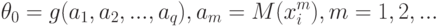 |
( 3) |
В методе моментов в качестве оценки используют статистику 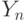 вида (2), которая отличается от формулы (2) тем, что теоретические моменты заменены выборочными.
вида (2), которая отличается от формулы (2) тем, что теоретические моменты заменены выборочными.
Статистики вида (2) применяются не только для оценивания параметров, но и для непараметрического оценивания характеристик случайной величины, таких, как коэффициент вариации, и для проверки гипотез. Во всех случаях применения статистики вида (2) говорят о методе моментов.
Распределение вектора во всех практически важных случаях является асимптотически нормальным. Это утверждение опирается на следующий общий факт.
Пусть случайный вектор 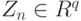 асимптотически нормален с математическим ожиданием
асимптотически нормален с математическим ожиданием 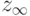 и ковариационной матрицей
и ковариационной матрицей 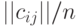 , а функция
, а функция 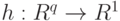 достаточно гладкая. Тогда случайная величина
достаточно гладкая. Тогда случайная величина  асимптотически нормальна с математическим ожиданием
асимптотически нормальна с математическим ожиданием 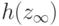 и дисперсией
и дисперсией
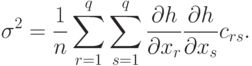 |
( 4) |
Этот способ нахождения предельного распределения известен как 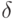 -метод Рао [
[
4.23
]
], метод линеаризации [
[
4.3
]
]. Последний термин и будем использовать. Условия регулярности, накладываемые на распределение случайной величины
-метод Рао [
[
4.23
]
], метод линеаризации [
[
4.3
]
]. Последний термин и будем использовать. Условия регулярности, накладываемые на распределение случайной величины 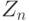 и функцию
и функцию  , при которых метод линеаризации обоснован, хорошо известны (см. [
, при которых метод линеаризации обоснован, хорошо известны (см. [  ], [
[
6.2
]
, с.337-339], а также
"Теоретическая база прикладной статистики"
настоящего курса).
], [
[
6.2
]
, с.337-339], а также
"Теоретическая база прикладной статистики"
настоящего курса).
Анастасия Маркова