|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Опубликован: 09.11.2009 | Доступ: свободный | Студентов: 4094 / 1041 | Оценка: 4.66 / 4.45 | Длительность: 54:13:00
Темы: Математика, Экономика
Специальности: Экономист
Лекция 5:
Описание данных
О формулировках законов больших чисел. Пусть 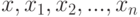 - независимые одинаково распределенные случайные элементы со значениями в
- независимые одинаково распределенные случайные элементы со значениями в  . Закон больших чисел - это утверждение о сходимости эмпирических средних к теоретическому среднему (математическому ожиданию) при росте объема выборки
. Закон больших чисел - это утверждение о сходимости эмпирических средних к теоретическому среднему (математическому ожиданию) при росте объема выборки  , т.е. утверждение о том, что
, т.е. утверждение о том, что
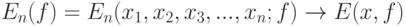 |
( 19) |
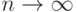 . Однако и слева, и справа в формуле (19) стоят, вообще говоря, множества. Поэтому понятие сходимости в (19) требует обсуждения и определения.
. Однако и слева, и справа в формуле (19) стоят, вообще говоря, множества. Поэтому понятие сходимости в (19) требует обсуждения и определения.В силу классического закона больших чисел при
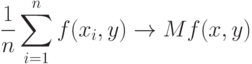 |
( 20) |
Если пространство состоит из конечного числа элементов, то из соотношения (20) легко вытекает (см., например, [
[
1.15
]
, с.192-193]), что
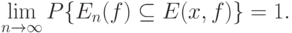 |
( 21) |
Другими словами, 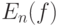 является состоятельной оценкой
является состоятельной оценкой  .
.
Если состоит из одного элемента, 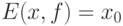 , то соотношение (21) переходит в следующее:
, то соотношение (21) переходит в следующее:
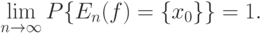 |
( 22) |
Однако с прикладной точки зрения доказательство соотношений (21) - (22) не дает достаточной уверенности в возможности использования в качестве оценки 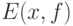 . Причина в том, что в процессе доказательства объем выборки предполагается настолько большим, что при всех
. Причина в том, что в процессе доказательства объем выборки предполагается настолько большим, что при всех 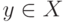 одновременно левые части соотношений (20) сосредотачиваются в непересекающихся окрестностях правых частей.
одновременно левые части соотношений (20) сосредотачиваются в непересекающихся окрестностях правых частей.
Замечание. Если в соотношении (20) рассмотреть сходимость с вероятностью 1, то аналогично (21) получим так называемый усиленный закон больших чисел [
[
1.15
]
, с.193-194]. Согласно этой теореме с вероятностью 1 эмпирическое среднее входит в теоретическое среднее , начиная с некоторого объема выборки , вообще говоря, случайного, 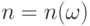 . Мы не будем останавливаться на сходимости с вероятностью 1, поскольку в соответствующих постановках, подробно разобранных в монографии [
[
1.15
]
], нет принципиальных отличий от случая сходимости по вероятности.
. Мы не будем останавливаться на сходимости с вероятностью 1, поскольку в соответствующих постановках, подробно разобранных в монографии [
[
1.15
]
], нет принципиальных отличий от случая сходимости по вероятности.
Если не является конечным, например,  то соотношения (21) и (22) неверны. Поэтому необходимо искать иные формулировки закона больших чисел. В классическом случае сходимости выборочного среднего арифметического к математическому ожиданию, т.е.
то соотношения (21) и (22) неверны. Поэтому необходимо искать иные формулировки закона больших чисел. В классическом случае сходимости выборочного среднего арифметического к математическому ожиданию, т.е.  , можно записать закон больших чисел так: для любого
, можно записать закон больших чисел так: для любого 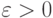 справедливо предельное соотношение
справедливо предельное соотношение
 |
( 23) |
В этом соотношении в отличие от (21) речь идет о попадании эмпирического среднего 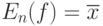 не непосредственно внутрь теоретического среднего , а в некоторую окрестность теоретического среднего.
не непосредственно внутрь теоретического среднего , а в некоторую окрестность теоретического среднего.
Обобщим эту формулировку. Как задать окрестность теоретического среднего в пространстве произвольной природы? Естественно взять его окрестность, определенную с помощью какой-либо метрики. Однако полезно обеспечить на ее дополнении до отделенность множества значений  как функции
как функции  от минимума этой функции на всем .
от минимума этой функции на всем .
Поэтому мы сочли целесообразным определить такую окрестность с помощью самой функции .
Определение 3. Для любого назовем 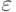 -пяткой функции
-пяткой функции 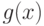 множество
множество
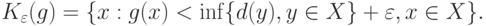
Таким образом, в -пятку входят все те  , для которых значение либо минимально, либо отличается от минимального (или от инфимума - точной нижней грани) не более чем на . Так, для
, для которых значение либо минимально, либо отличается от минимального (или от инфимума - точной нижней грани) не более чем на . Так, для  и функции
и функции 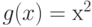 минимум равен 0, а -пятка имеет вид интервала
минимум равен 0, а -пятка имеет вид интервала  . В формулировке (23) классического закона больших чисел утверждается, что при любом вероятность попадания среднего арифметического в
. В формулировке (23) классического закона больших чисел утверждается, что при любом вероятность попадания среднего арифметического в 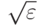 -пятку математического ожидания стремится к 1. Поскольку произвольно, то вместо -пятки можно говорить о -пятке, т.е. перейти от (23) к эквивалентной записи
-пятку математического ожидания стремится к 1. Поскольку произвольно, то вместо -пятки можно говорить о -пятке, т.е. перейти от (23) к эквивалентной записи
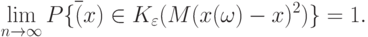 |
( 24) |
Соотношение (24) допускает непосредственное обобщение на общий случай пространств произвольной природы.
Схема закона больших чисел. Пусть 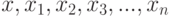 - независимые одинаково распределенные случайные элементы со значениями в пространстве произвольной природы с показателем различия
- независимые одинаково распределенные случайные элементы со значениями в пространстве произвольной природы с показателем различия 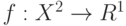 . Пусть выполнены некоторые математические условия регулярности. Тогда для любого справедливо предельное соотношение
. Пусть выполнены некоторые математические условия регулярности. Тогда для любого справедливо предельное соотношение
 |
( 25) |
Аналогичным образом может быть сформулирована и общая идея усиленного закона больших чисел. Ниже приведены две конкретные формулировки "условий регулярности".
Законы больших чисел. Начнем с рассмотрения естественного обобщения конечного множества - бикомпактного пространства .
Теорема 3. В условиях теоремы 1 справедливо соотношение (25).
Доказательство. Воспользуемся построенным при доказательстве теоремы 1 конечным открытым покрытием 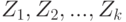 пространства таким, что для него выполнено соотношение (3). Построим на его основе разбиение на непересекающиеся множества
пространства таким, что для него выполнено соотношение (3). Построим на его основе разбиение на непересекающиеся множества 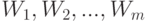 (объединение элементов разбиения составляет ). Это можно сделать итеративно. На первом шаге из
(объединение элементов разбиения составляет ). Это можно сделать итеративно. На первом шаге из 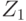 следует вычесть
следует вычесть 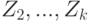 - это и будет
- это и будет 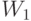 . Затем в качестве нового пространства надо рассмотреть разность и , а покрытием его будет
. Затем в качестве нового пространства надо рассмотреть разность и , а покрытием его будет 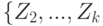 . И так до
. И так до  -го шага, когда последнее из рассмотренных покрытий будет состоять из единственного открытого множества
-го шага, когда последнее из рассмотренных покрытий будет состоять из единственного открытого множества 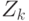 .
Остается из построенной последовательности
.
Остается из построенной последовательности 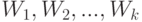 вычеркнуть пустые множества, которые могли быть получены при осуществлении описанной процедуры (поэтому, вообще говоря,
вычеркнуть пустые множества, которые могли быть получены при осуществлении описанной процедуры (поэтому, вообще говоря,  может быть меньше ).
может быть меньше ).
В каждом из элементов разбиения выберем по одной точке, которые назовем центрами разбиения и соответственно обозначим  . Это и есть то конечное множество, которым можно аппроксимировать бикомпактное пространство . Пусть входит в
. Это и есть то конечное множество, которым можно аппроксимировать бикомпактное пространство . Пусть входит в 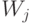 . Тогда из соотношения (3) вытекает, что
. Тогда из соотношения (3) вытекает, что
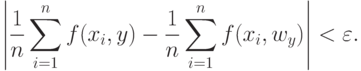 |
( 26) |
Перейдем к доказательству соотношения (25). Возьмем произвольное 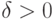 . Рассмотрим некоторую точку
. Рассмотрим некоторую точку  из . Доказательство будет основано на том, что с вероятностью, стремящейся к 1, для любого вне
из . Доказательство будет основано на том, что с вероятностью, стремящейся к 1, для любого вне  выполнено неравенство
выполнено неравенство
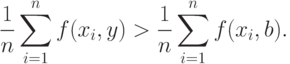 |
( 27) |
Для обоснования этого неравенства рассмотрим все элементы разбиения , имеющие непустое пересечение с внешностью 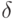 -пятки . Из неравенства (26) следует, что для любого вне левая часть неравенства (27) не меньше
-пятки . Из неравенства (26) следует, что для любого вне левая часть неравенства (27) не меньше
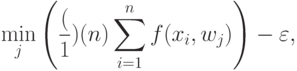 |
( 28) |
где минимум берется по центрам всех элементов разбиения, имеющим непустое пересечение с внешностью -пятки. Возьмем теперь в каждом таком разбиении точку 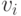 , лежащую вне -пятки . Тогда из неравенств (3) и (28) следует, что левая часть неравенства (27) не меньше
, лежащую вне -пятки . Тогда из неравенств (3) и (28) следует, что левая часть неравенства (27) не меньше
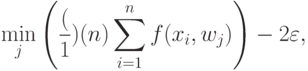 |
( 29) |
В силу закона больших чисел для действительнозначных случайных величин каждая из участвующих в соотношениях (27) и (29) средних арифметических имеет своими пределами соответствующие математические ожидания, причем в соотношении (29) эти пределы не менее
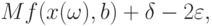 лежат вне -пятки . Следовательно, при
лежат вне -пятки . Следовательно, при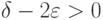
и достаточно большом , обеспечивающем необходимую близость рассматриваемого конечного числа средних арифметических к их математическим ожиданиям, справедливо неравенство (27).
Из неравенства (27) следует, что пересечение с внешностью пусто. При этом точка может входить в , а может и не входить. Во втором случае состоит из иных точек, входящих в . Теорема 3 доказана.
Если не является бикомпактным пространством, то необходимо суметь оценить рассматриваемые суммы "на периферии", вне бикомпактного ядра, которое обычно выделяется естественным путем. Один из возможных комплексов условий сформулирован выше в теореме 2.
Теорема 4. В условиях теоремы 2 справедлив закон больших чисел, т.е. соотношение (25).
Доказательство. Будем использовать обозначения, введенные в теореме 2 и при ее доказательстве. Пусть 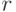 и
и 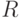 ,
, 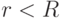 - положительные числа. Рассмотрим точку в шаре
- положительные числа. Рассмотрим точку в шаре  и точку вне шара
и точку вне шара 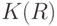 . Поскольку
. Поскольку
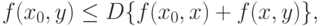
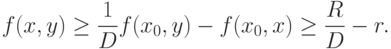 |
( 30) |
Положим
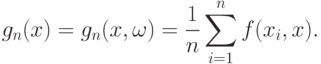
Сравним 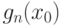 и
и 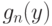 . Выборку
. Выборку  разобьем на две части. В первую часть включим те элементы выборки, которые входят в , во вторую - все остальные (т.е. лежащие вне ). Множество индексов элементов первой части обозначим
разобьем на две части. В первую часть включим те элементы выборки, которые входят в , во вторую - все остальные (т.е. лежащие вне ). Множество индексов элементов первой части обозначим 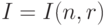 . Тогда в силу неотрицательности
. Тогда в силу неотрицательности  имеем
имеем
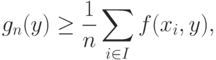
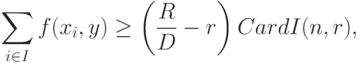
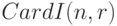 - число элементов в множестве индексов
- число элементов в множестве индексов 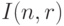 . Следовательно,
. Следовательно,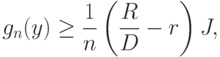 |
( 31) |
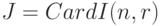 - биномиальная случайная величина
- биномиальная случайная величина 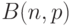 с вероятностью успеха
с вероятностью успеха  . По теореме Хинчина для справедлив классический закон больших чисел. Пусть . Выберем
. По теореме Хинчина для справедлив классический закон больших чисел. Пусть . Выберем 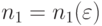 так, чтобы при
так, чтобы при 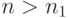 было выполнено сооxтношение
было выполнено сооxтношение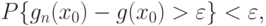 |
( 32) |
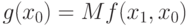 . Выберем так, чтобы вероятность успеха
. Выберем так, чтобы вероятность успеха 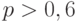 . По теореме Бернулли можно выбрать
. По теореме Бернулли можно выбрать 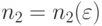 так, чтобы при
так, чтобы при 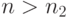
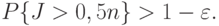 |
( 33) |
Выберем так, чтобы
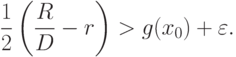
Тогда
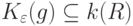 |
( 34) |
 с вероятностью не менее
с вероятностью не менее 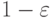 имеем
имеем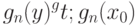 |
( 35) |
вне . Из (34) следует, что минимизировать 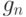 достаточно внутри бикомпактного шара , при этом не пусто и
достаточно внутри бикомпактного шара , при этом не пусто и |
( 36) |
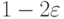 .
.Пусть 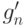 и
и 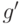 - сужения и
- сужения и 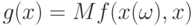 соответственно на как функций от . В силу (34) справедливо равенство
соответственно на как функций от . В силу (34) справедливо равенство  . Согласно доказанной выше теореме 3 найдется
. Согласно доказанной выше теореме 3 найдется 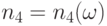 такое, что
такое, что
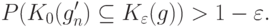
Согласно (36) с вероятностью не менее
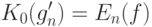
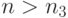 . Следовательно, при
. Следовательно, при 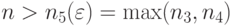 имеем
имеем
Справедливы и иные варианты законов больших чисел, полученные, в частности, в статье [ [ 1.17 ] ].
Медиана Кемени и экспертные оценки. Рассмотрим на основе развитой выше теории частный случай пространств нечисловой природы - пространство бинарных отношений на конечном множестве 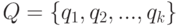 и его подпространства. Как известно, каждое бинарное отношение
и его подпространства. Как известно, каждое бинарное отношение  можно описать матрицей
можно описать матрицей 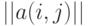 из 0 и 1, причем
из 0 и 1, причем  тогда и только тогда
тогда и только тогда  и
и 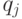 находятся в отношении , и
находятся в отношении , и 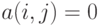 в противном случае.
в противном случае.
Определение 4. Расстоянием Кемени между бинарными отношениями и 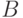 , описываемыми матрицами и
, описываемыми матрицами и 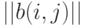 соответственно, называется
соответственно, называется

Замечание. Иногда в определение расстояния Кемени вводят множитель, зависящий от .
Определение 5. Медианой Кемени для выборки, состоящей из бинарных отношений, называется эмпирическое среднее, построенное с помощью расстояния Кемени.
Поскольку число бинарных отношений на конечном множестве конечно, то эмпирические и теоретические средние для произвольных показателей различия существуют и справедливы законы больших чисел, описанные формулами (21) и (22) выше.
Бинарные отношения (в частности, упорядочения) часто используются для описания мнений экспертов. Тогда расстояние Кемени измеряет близость мнений экспертов, а медиана Кемени позволяет находить итоговое усредненное мнение комиссии экспертов. Расчет медианы Кемени обычно включают в информационное обеспечение систем принятия решений с использованием оценок экспертов. Речь идет, например, о математическом обеспечении автоматизированного рабочего места "Математика в экспертизе" (АРМ "МАТЭК"), предназначенного, в частности, для использования при проведении экспертиз в задачах экологического страхования. Поэтому представляет большой практический интерес численное изучение свойств медианы Кемени при конечном объеме выборки. Такое изучение дополняет описанную выше асимптотическую теорию, в которой объем выборки предполагается безгранично возрастающим 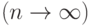 .
.
Компьютерное изучение свойств медианы Кемени при конечных объемах выборок. С помощью специально разработанной программной системы В.Н. Жихаревым был проведен ряд серий численных экспериментов по изучению свойств выборочных медиан Кемени. Полученные результаты приводится в табл.5, взятой из статьи [ [ 5.5 ] ]. В каждой серии методом статистических испытаний определенное число раз моделировался случайный и независимый выбор экспертных ранжировок, а затем находились все медианы Кемени для смоделированного набора мнений экспертов. При этом в сериях 1-5 распределение ответа эксперта предполагалось равномерным на множестве всех ранжировок. В серии 6 это распределение являлось монотонным относительно расстояния Кемени с некоторым центром (о понятии монотонности см. выше), т.е. вероятность выбора определенной ранжировки убывала с увеличением расстояния Кемени этой ранжировки от центра. Таким образом, серии 1-5 соответствуют ситуации, когда у экспертов нет почвы для согласия, нет группировки их мнений относительно некоторого единого среднего группового мнения, в то время как в серии 6 есть единое мнение - описанный выше центр, к которому тяготеют ответы экспертов.
Результаты, приведенные в табл.5.5, можно комментировать разными способами. Неожиданным явилось большое число элементов в выборочной медиане Кемени - как среднее, так и особенно максимальное. Одновременно обращает на себя внимание убывание этих чисел при росте числа экспертов и особенно при переходе к ситуации реального существования группового мнения (серия 6). Достаточно часто один из ответов экспертов входит в медиану Кемени (т.е. пересечение множества ответов экспертов и медианы Кемени непусто), а диаметр медианы как множества в пространстве ранжировок заметно меньше диаметра множества ответов экспертов. По этим показателям - наилучшее положение в серии 6. Грубо говоря, всяческие "патологии" в поведении медианы Кемени наиболее резко проявляются в ситуации, когда ее применение не имеет содержательного обоснования, т.е. когда у экспертов нет основы для согласия, их ответы равномерно распределены на множестве ранжировок.
Увеличение числа испытаний в 10 раз при переходе от серии 1 к серии 5 не очень сильно повлияло на приведенные в таблице характеристики, поэтому представляется, что суть дела выявляется при числе испытаний (в методе Монте-Карло), равном 100 или даже 50. Увеличение числа объектов или экспертов увеличивает число элементов в рассматриваемом пространстве ранжировок, а потому уменьшается частота попадания какого-либо из мнений экспертов внутрь медианы Кемени, а также отношение диаметра медианы к диаметру множества экспертов и число элементов медианы Кемени (среднее и максимальное). Можно сказать, что увеличение числа объектов или экспертов уменьшает степень дискретности задачи, приближает ее к непрерывному случаю, а потому уменьшает выраженность различных "патологий".
Есть много интересных результатов, которые здесь не рассматриваются. Они связаны, в частности, со сравнением медианы Кемени с другими методами усреднения мнений экспертов, например, с нахождением итогового упорядочения по методу средних рангов [ [ 2.15 ] ], а также с использованием малых окрестностей ответов экспертов для поиска входящих в медиану ранжировок, с теоретической и численной оценкой скорости сходимости в законах больших чисел.
Анастасия Маркова