|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Опубликован: 09.11.2009 | Доступ: свободный | Студентов: 4094 / 1040 | Оценка: 4.66 / 4.45 | Длительность: 54:13:00
Темы: Математика, Экономика
Специальности: Экономист
Теги:
Лекция 5:
Описание данных
Бинарные отношения. Теорию ранговой корреляции (см.
"Многомерный статистический анализ"
) можно рассматривать как теорию статистического анализа случайных ранжировок, равномерно распределенных на множестве всех ранжировок. Так, при обработке данных классического психофизического эксперимента по упорядочению кубиков соответственно их весу, подробно описанного в работе [
[
5.27
]
], оказалась адекватной следующая так называемая 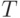 -модель ранжирования.
-модель ранжирования.
Пусть имеется 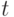 объектов
объектов 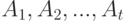 причем каждому объекту
причем каждому объекту  соответствует число
соответствует число  , описывающее его положение на шкале изучаемого признака. Испытуемый упорядочивает объекты так, как если бы оценивал соответствующие им значения с ошибками, т.е. находил
, описывающее его положение на шкале изучаемого признака. Испытуемый упорядочивает объекты так, как если бы оценивал соответствующие им значения с ошибками, т.е. находил 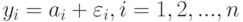 , где
, где 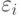 - ошибка при рассмотрении
- ошибка при рассмотрении  -го объекта, а затем располагал бы объекты в том порядке, в каком располагаются
-го объекта, а затем располагал бы объекты в том порядке, в каком располагаются 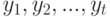 .
В этом случае вероятность появления упорядочения
.
В этом случае вероятность появления упорядочения 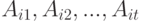 есть
есть 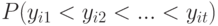 , а ранги
, а ранги 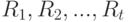 объектов являются рангами случайных величин , полученными при их упорядочении в порядке возрастания. Кроме того, для простоты расчетов в модели предполагается, что ошибки испытуемого
объектов являются рангами случайных величин , полученными при их упорядочении в порядке возрастания. Кроме того, для простоты расчетов в модели предполагается, что ошибки испытуемого 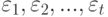 независимы и имеют нормальное распределение с математическим ожиданием 0 и дисперсией
независимы и имеют нормальное распределение с математическим ожиданием 0 и дисперсией 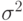 .
.
Как уже отмечалось в
"Различные виды статистических данных"
, бинарное отношение на множестве из элементов полностью описывается матрицей из 0 и 1 порядка  . Поэтому задать распределение случайного бинарного отношения - это то же самое, что задать распределение вероятностей на множестве всех матриц описанного вида, состоящем из
. Поэтому задать распределение случайного бинарного отношения - это то же самое, что задать распределение вероятностей на множестве всех матриц описанного вида, состоящем из 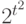 элементов. Пространства ранжировок, разбиений, толерантностей зачастую удобно считать подпространствами пространства всех бинарных отношений, тогда распределения вероятностей на них - частные случаи описанного выше распределения, выделенные тем, что вероятности принадлежности соответствующим подпространствам равны 1. Распределение произвольного бинарного отношения описывается
элементов. Пространства ранжировок, разбиений, толерантностей зачастую удобно считать подпространствами пространства всех бинарных отношений, тогда распределения вероятностей на них - частные случаи описанного выше распределения, выделенные тем, что вероятности принадлежности соответствующим подпространствам равны 1. Распределение произвольного бинарного отношения описывается 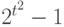 параметрами, распределение случайной ранжировки (без связей) -
параметрами, распределение случайной ранжировки (без связей) -  параметрами, а описанная выше -модель ранжирования -
параметрами, а описанная выше -модель ранжирования - 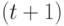 параметром.
При
параметром.
При 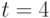 эти числа равны соответственно 65535, 23 и 5. Первое из этих чисел показывает практическую невозможность использования в вероятностно-статистических моделях произвольных бинарных отношений, поскольку по имеющимся данным невозможно оценить столь большое число параметров. Приходится ограничиваться теми или иными семействами бинарных отношений - ранжировками, разбиениями, толерантностями и др. Модель произвольной случайной ранжировки при
эти числа равны соответственно 65535, 23 и 5. Первое из этих чисел показывает практическую невозможность использования в вероятностно-статистических моделях произвольных бинарных отношений, поскольку по имеющимся данным невозможно оценить столь большое число параметров. Приходится ограничиваться теми или иными семействами бинарных отношений - ранжировками, разбиениями, толерантностями и др. Модель произвольной случайной ранжировки при 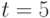 описывается 119 параметрами, при
описывается 119 параметрами, при 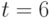 - уже 719 параметрами, при
- уже 719 параметрами, при 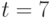 число параметров достигает 5049, что уже явно находится за пределами возможности оценивания. В то же время -модель ранжирования при описывается всего 8-ю параметрами, а потому может быть кандидатом для практического использования.
число параметров достигает 5049, что уже явно находится за пределами возможности оценивания. В то же время -модель ранжирования при описывается всего 8-ю параметрами, а потому может быть кандидатом для практического использования.
Что естественно предположить относительно распределения случайного элемента со значениями в том или ином пространстве бинарных отношений? Зачастую целесообразно считать, что распределение имеет некий центр, попадание в который наиболее вероятно, а по мере удаления от центра вероятности убывают. Это соответствует естественной модели измерения с ошибкой; в классическом одномерном случае результат подобного измерения обычно описывается унимодальной симметричной плотностью, монотонно возрастающей слева от модального значения, в котором плотность максимальна, и монотонно убывающей справа от него. Чтобы ввести понятие монотонного распределения в пространстве бинарных отношений, будем исходить из метрики в этом пространстве.
Воспользовавшись тем, что бинарные отношения 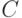 и
и 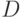 однозначно описываются матрицами
однозначно описываются матрицами 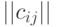 и
и 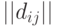 порядка соответственно, рассмотрим расстояние (в несколько другой терминологии - метрику) в пространстве бинарных отношений
порядка соответственно, рассмотрим расстояние (в несколько другой терминологии - метрику) в пространстве бинарных отношений
 |
( 4) |
Метрика (4) в различных пространствах бинарных отношений - ранжировок, разбиений, толерантностей - может быть введена с помощью соответствующих систем аксиом (см. "Различные виды статистических данных" ). В настоящее время метрику (4) обычно называют расстоянием Кемени в честь американского исследователя Джона Кемени, впервые получившего эту метрику исходя из предложенной им системы аксиом для расстояния между упорядочениями (ранжировками).
В статистике нечисловых данных используются и иные метрики, отличающиеся от расстояния Кемени. Более того, для использования понятия монотонного распределения, о котором сейчас идет речь, нет необходимости требовать выполнения неравенства треугольника, а достаточно, чтобы 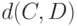 можно было рассматривать как показатель различия. Под показателем различия понимаем такую функцию двух бинарных отношений и , что
можно было рассматривать как показатель различия. Под показателем различия понимаем такую функцию двух бинарных отношений и , что 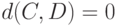 при
при 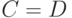 и увеличение интерпретируется как возрастание различия между и .
и увеличение интерпретируется как возрастание различия между и .
Определение 1. Распределение бинарного отношения  называется монотонным с центром в
называется монотонным с центром в  относительно расстояния (показателя различия)
относительно расстояния (показателя различия)  , если из
, если из 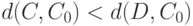 следует, что
следует, что  .
.
Это определение впервые введено в монографии [
[
1.15
]
, c.196]. Оно может использоваться в любых пространствах бинарных отношений и, более того, в любых пространствах из конечного числа элементов, лишь бы в них была введена функция - показатель различия элементов и этого пространства. Монотонное распределение унимодально, мода находится в .
Определение 2. Распределение бинарного отношения называется симметричным относительно расстояния с центром в , если существует такая функция ![f:R_+^1\rightarrow[0,1]](/sites/default/files/tex_cache/442d0b04fed065b26e6309ccc6bc518c.png) что
что
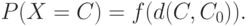 |
( 5) |
Если распределение монотонно и таково, что из 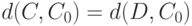 следует
следует  , то оно симметрично. Если функция
, то оно симметрично. Если функция  в формуле (5) монотонно строго убывает, то соответствующее распределение монотонно в смысле определения 1.
в формуле (5) монотонно строго убывает, то соответствующее распределение монотонно в смысле определения 1.
Поскольку толерантность на множестве из элементов задается 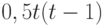 элементами
элементами 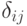 матрицы из 0 и 1 порядка , лежащими выше главной диагонали, то распределение на множестве толерантностей задается в общем случае
матрицы из 0 и 1 порядка , лежащими выше главной диагонали, то распределение на множестве толерантностей задается в общем случае 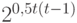 параметрами. Естественно выделить семейство распределений, соответствующее независимым элементам матрицы. Оно задается бернуллиевским вектором (люсианом) с параметрами (выше бернуллиевские вектора рассмотрены подробнее). Математическая техника, необходимая для изучения толерантностей с независимыми элементами, существенно проще, чем в случае ранжировок и разбиений. Здесь легко отказаться от условия равномерности распределения.
Этому условию соответствует
параметрами. Естественно выделить семейство распределений, соответствующее независимым элементам матрицы. Оно задается бернуллиевским вектором (люсианом) с параметрами (выше бернуллиевские вектора рассмотрены подробнее). Математическая техника, необходимая для изучения толерантностей с независимыми элементами, существенно проще, чем в случае ранжировок и разбиений. Здесь легко отказаться от условия равномерности распределения.
Этому условию соответствует 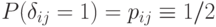 , в то время как статистические методы анализа люсианов, развитые в статистике нечисловых данных (см., например, работы [
, в то время как статистические методы анализа люсианов, развитые в статистике нечисловых данных (см., например, работы [ 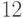 ,
, 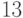 ,
, 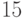 ]) не налагают никаких существенных ограничений на
]) не налагают никаких существенных ограничений на 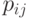 .
.
Как уже отмечалось, при обработке мнений экспертов сначала проверяют согласованность. В частности, если мнения экспертов описываются монотонными распределениями, то для согласованности необходимо совпадение центров этих распределений. К сожалению, классические методы проверки согласованности для ранжировок, основанные на коэффициентах ранговой корреляции и конкордации, позволяют лишь отвергнуть гипотезу о равнораспределенности. Но не установить, можно ли считать, что центры соответствующих экспертам распределений совпадают или же, например, существует две группы экспертов, каждая со своим центром. Теория случайных толерантностей лишена этого недостатка. Отсюда вытекают следующие практические рекомендации.
Пусть цель обработки экспертных данных состоит в получении ранжировки, отражающей групповое мнение. Однако согласно рекомендуемой процедуре экспертного опроса пусть эксперты не упорядочивают объекты, а проводят парные сравнения каждого из рассматриваемых объектов со всеми остальными, причем ровно один раз. Тогда ответ эксперта - толерантность, но, вообще говоря, не ранжировка, поскольку в ответах эксперта может нарушаться транзитивность.
Возможны два пути обработки данных. Первый - превратить ответ эксперта в ранжировку (тем или иным способом "спроектировав" его на пространство ранжировок), а затем проверять согласованность ранжировок с помощью известных критериев. При этом от толерантности перейти к ранжировке можно, например, так. Будем выбирать ближайшую (в смысле применяемого расстояния) матрицу к матрице ответов эксперта из всех, соответствующих ранжировкам без связей.
Второй путь - проверить согласованность случайных толерантностей, а групповое мнение искать с помощью медианы Кемени (подробнее см. "Статистика нечисловых данных" ) непосредственно по исходным данным, т.е. по толерантностям. Групповое мнение при этом может быть найдено в пространстве ранжировок. Второй путь мы считаем более предпочтительным, поскольку при этом обеспечивается более адекватная проверка согласованности и исключается процедура укладывания мнения эксперта в "прокрустово ложе" ранжировки (эта процедура может приводить как к потере информации, так и к принципиально неверным выводам, вызванным искажениями мнений экспертов).
Области применения статистики бинарных отношений многообразны: ранговая корреляция - оценка величины связи между переменными, измеренными в порядковой шкале; анализ экспертных или экспериментальных упорядочений; анализ разбиений технико-экономических показателей на группы сходных между собой; обработка данных о сходстве (взаимозаменяемости); статистический анализ классификаций; математические вопросы теории менеджмента и др.
Случайные множества. Будем рассматривать случайные подмножества некоторого множества 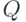 . Если состоит из конечного числа элементов, то считаем, что случайное подмножество
. Если состоит из конечного числа элементов, то считаем, что случайное подмножество  - это случайный элемент со значениями в
- это случайный элемент со значениями в 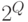 - множестве всех подмножеств множества , состоящем из
- множестве всех подмножеств множества , состоящем из  элементов. Чтобы удовлетворить математиков, считаем, что все подмножества измеримы. Тогда распределение случайного подмножества
элементов. Чтобы удовлетворить математиков, считаем, что все подмножества измеримы. Тогда распределение случайного подмножества 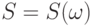 множества - это
множества - это
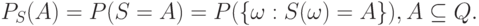 |
( 6) |
В формуле (6) предполагается, что 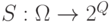 где
где 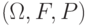 - вероятностное пространство (здесь
- вероятностное пространство (здесь  - пространство элементарных событий,
- пространство элементарных событий, 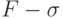 - алгебра случайных событий,
- алгебра случайных событий, 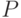 - вероятностная мера на
- вероятностная мера на 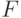 ), на котором определен случайный элемент
), на котором определен случайный элемент 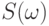 . Через распределение
. Через распределение  выражаются вероятности различных событий, связанных с . Так, чтобы найти вероятность накрытия фиксированного элемента
выражаются вероятности различных событий, связанных с . Так, чтобы найти вероятность накрытия фиксированного элемента 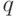 случайным множеством , достаточно вычислить
случайным множеством , достаточно вычислить
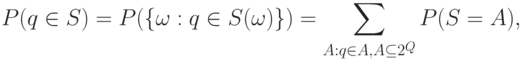
 множества , содержащим . Пусть
множества , содержащим . Пусть 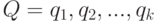 . Рассмотрим случайные величины, определяемые по случайному множеству следующим образом
. Рассмотрим случайные величины, определяемые по случайному множеству следующим образом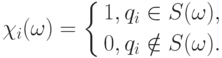
Определение 3. Случайное множество называется случайным множеством с независимыми элементами, если случайные величины 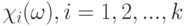 , независимы (в совокупности).
, независимы (в совокупности).
Последовательность случайных величин 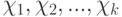 - бернуллиевский вектор с
- бернуллиевский вектор с 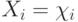 и
и 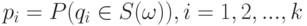 . Из сказанного выше следует, что распределение случайного множества с независимыми элементами задается формулой
. Из сказанного выше следует, что распределение случайного множества с независимыми элементами задается формулой

 - мерное параметрическое семейство, входящее в
- мерное параметрическое семейство, входящее в  - мерное семейство всех распределений случайных подмножеств множества .
- мерное семейство всех распределений случайных подмножеств множества .При исследовании случайных подмножеств произвольного множества будем рассматривать их как случайные величины со значениями в некотором пространстве подмножеств множества , например, в пространстве замкнутых подмножеств множества .
Представляющими интерес лишь для математиков способами введения измеримой структуры в интересоваться не будем. Отсутствие специального интереса к проблеме измеримости связано с тем, что при вероятностно-статистическом моделировании и обработке на ЭВМ все случайные подмножества рассматриваются как конечные (т.е. подмножества конечного множества).
Случайные множества находят разнообразные применения в многообразных проблемах эконометрики и математической экономики, в том числе в задачах управлении запасами и ресурсами (см. об этом главу 5 в монографии [ ]), в задачах менеджмента и, в частности, маркетинга, в экспертных оценках, например, при анализе мнений голосующих или опрашиваемых, каждый из которых отмечает несколько пунктов из списка и т.д. Кроме того, случайные множества применяются в гранулометрии, при изучении пористых сред и объектов сложной природы в таких областях, как металлография, петрография, биология, в частности, математическая морфология, в изучении структуры веществ и материалов, в исследовании процессов распространения, в том числе просачивания, распространения пожаров, экологических загрязнений, при районировании, в изучении областей поражения, например, поражения металла коррозией и сердечной мышцы при инфаркте миокарда, и т.д., и т.п.
Можно вспомнить о компьютерной томографии, о наглядном представлении сложной информации на экране компьютера, об изучении распространения рекламной информации, о картах Кохонена (популярный метод представления информации при применении нейросетей) и т.д.
Ранговые методы. В
"Различные виды статистических данных"
установлено, что любой адекватный алгоритм в порядковой шкале является функцией от некоторой матрицы . Пусть никакие два из результатов наблюдений  не совпадают, а
не совпадают, а 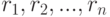 - их ранги. Тогда элементы матрицы и ранги результатов наблюдений связаны взаимно однозначным соответствием:
- их ранги. Тогда элементы матрицы и ранги результатов наблюдений связаны взаимно однозначным соответствием:

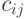 через ранги выражаются так:
через ранги выражаются так: 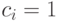 , если
, если 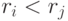 , и
, и 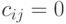 в противном случае.
в противном случае.Сказанное означает, что при обработке данных, измеренных в порядковой шкале, могут применяться только ранговые статистические методы. Отметим, что часто используемое в непараметрической статистике преобразование  (здесь
(здесь 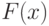 - непрерывная функция распределения случайной величины , причем предполагается произвольной) фактически означает переход к порядковой шкале, поскольку статистические выводы при этом инвариантны относительно допустимых преобразований в порядковой шкале.
- непрерывная функция распределения случайной величины , причем предполагается произвольной) фактически означает переход к порядковой шкале, поскольку статистические выводы при этом инвариантны относительно допустимых преобразований в порядковой шкале.
Разумеется, ранговые статистические методы могут применяться не только при обработке данных, измеренных в порядковой шкале. Так, для проверки независимости двух количественных признаков в случае, когда нет уверенности в нормальности соответствующего двумерного распределения, целесообразно пользоваться коэффициентами ранговой корреляции Кендалла или Спирмена.
В настоящее время с помощью непараметрических и прежде всего ранговых методов можно решать все те задачи эконометрики и прикладной статистики, что и с помощью параметрических методов, в частности, основанных на предположении нормальности. Однако параметрические методы вошли в массовое сознание исследователей и инженеров и мешают широкому внедрению более обоснованной и прогрессивной ранговой статистики. Так, при проверке однородности двух выборок вместо критерия Стьюдента целесообразно использовать ранговые методы (см. "Статистический анализ числовых величин" ), но пока это делается редко.
Объекты общей природы. Вероятностная модель объекта нечисловой природы в общем случае - случайный элемент со значениями в пространстве произвольного вида, а модель выборки таких объектов - совокупность независимых одинаково распределенных случайных элементов. Именно такая модель была использована для обработки наблюдений, каждое из которых - нечеткое множество [ [ 1.16 ] ].
Из-за имеющего разнобоя в терминологии приведем математические определения из справочника по теории вероятностей академика РАН Ю.В Прохорова и проф. Ю.А. Розанова [ [ 2.16 ] ].
Пусть 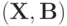 - некоторое измеримое пространство;
- некоторое измеримое пространство; 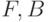 - измеримая функция
- измеримая функция 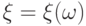 на пространстве элементарных событий
на пространстве элементарных событий 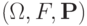 (где - вероятностная мера на
(где - вероятностная мера на 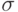 - алгебре - измеримых подмножеств , называемых событиями) со значениями в называется случайной величиной (чаще этот математический объект называют случайным элементом, оставляя термин "случайная величина" за частным случаем, когда
- алгебре - измеримых подмножеств , называемых событиями) со значениями в называется случайной величиной (чаще этот математический объект называют случайным элементом, оставляя термин "случайная величина" за частным случаем, когда  - числовая прямая) в фазовом пространстве . Распределением вероятностей этой случайной величины
- числовая прямая) в фазовом пространстве . Распределением вероятностей этой случайной величины 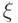 называется функция
называется функция 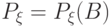 на -алгебре
на -алгебре 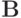 фазового пространства, определенная как
фазового пространства, определенная как
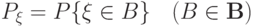 |
( 7) |
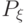 представляет собой вероятностную меру в фазовом пространстве ) [
[
2.16
]
, с.132].
представляет собой вероятностную меру в фазовом пространстве ) [
[
2.16
]
, с.132].Пусть 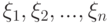 - случайные величины на пространстве случайных событий в соответствующих фазовых пространствах
- случайные величины на пространстве случайных событий в соответствующих фазовых пространствах 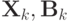 . Совместным распределением вероятностей этих величин называется функция
. Совместным распределением вероятностей этих величин называется функция  , определенная на множествах
, определенная на множествах 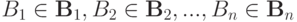 как
как
 |
( 8) |
Распределение вероятностей 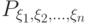 как функция на полукольце множеств вида
как функция на полукольце множеств вида  , в произведении пространств
, в произведении пространств 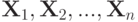 представляет собой аналог классической функции распределения. Случайные величины называются независимыми, если при любых
представляет собой аналог классической функции распределения. Случайные величины называются независимыми, если при любых 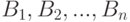 (см. [
[
2.16
]
, с.133])
(см. [
[
2.16
]
, с.133])
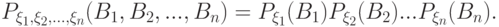 |
( 9) |
Предположим, что совместное распределение вероятностей 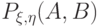 случайных величин и
случайных величин и 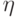 абсолютно непрерывно относительно некоторой меры на произведении пространств
абсолютно непрерывно относительно некоторой меры на произведении пространств  , являющейся произведением мер
, являющейся произведением мер  и
и 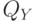 , т.е.:
, т.е.:
 |
( 10) |
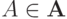 и
и 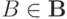 , где
, где 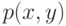 - соответствующая плотность распределения вероятностей [
[
2.16
]
, с.145].
- соответствующая плотность распределения вероятностей [
[
2.16
]
, с.145].В формуле (10) предполагается, что 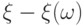 и
и 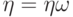 - случайные величины на одном и том же пространстве элементарных событий со значениями в фазовых пространствах
- случайные величины на одном и том же пространстве элементарных событий со значениями в фазовых пространствах 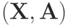 и
и 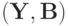 . Существование плотности вытекает из абсолютной непрерывности относительно в соответствии с теоремой Радона-Никодима.
. Существование плотности вытекает из абсолютной непрерывности относительно в соответствии с теоремой Радона-Никодима.
Условное распределение вероятностей  может быть выбрано одинаковым для всех
может быть выбрано одинаковым для всех 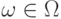 при которых случайная величина
при которых случайная величина 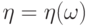 сохраняет одно и то же значение:
сохраняет одно и то же значение: 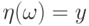 . При почти каждом
. При почти каждом 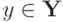 (относительно распределения
(относительно распределения 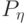 в фазовом пространстве ) условное распределение вероятностей
в фазовом пространстве ) условное распределение вероятностей  , где
, где  и будет абсолютно непрерывно относительно меры :
и будет абсолютно непрерывно относительно меры :
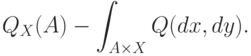
Причем соответствующая плотность условного распределения вероятностей будет иметь вид (см. [ [ 2.16 ] , с.145-146]):
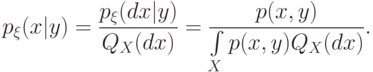 |
( 11) |
При построении вероятностных моделей реальных явлений важны вероятностные пространства из конечного числа элементарных событий. Для них перечисленные выше общие понятия становятся более прозрачными, в частности, снимаются вопросы измеримости (все подмножества конечного множества обычно считаются измеримыми). Вместо плотностей и условных плотностей рассматриваются вероятности и условные вероятности. Отметим, что вероятности можно рассматривать как плотности относительно меры, приписывающей каждому элементу пространства элементарных событий вес 1, т.е. считающей меры
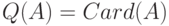
За последние десятилетия в прикладной статистике сформировалась новая область - статистика нечисловых данных, она же - статистика объектов нечисловой природы. К настоящему времени она развита не менее, чем ранее выделенные статистика случайных величин, многомерный статистический анализ, статистика временных рядов и случайных процессов. Краткая сводка основных постановок и результатов прикладной статистики в пространствах нечисловой природы приведены ниже в данном параграфе и в "Статистика нечисловых данных" .
Теория, построенная для результатов наблюдений, лежащих в пространствах общей природы, является центральным стержнем в статистике нечисловой природы. В ее рамках удалось разработать и изучить методы оценивания параметров и характеристик, проверки гипотез (в частности, с помощью статистик интегрального типа), параметрической и непараметрической регрессии (восстановления зависимостей), непараметрического оценивания плотности, дискриминантного и кластерного анализов и т.д.
Вероятностно-статистические методы, развитые для результатов наблюдений из пространств произвольного вида, позволяют единообразно проводить анализ данных из любого конкретного пространства. Так, в монографии [ [ 1.15 ] ] они применены к конечным случайным множествам, в работе [ [ 1.16 ] ] - к нечетким множествам. С их помощью установлено поведение обобщенного мнения экспертной комиссии (медианы Кемени) при увеличении числа экспертов, когда ответы экспертов лежат в том или ином пространстве бинарных отношений. Методы классификации могут быть основаны на непараметрических оценках плотности распределения вероятностей в пространстве общей природы. Такие методы были применены для медицинской диагностики в пространстве разнотипных данных, когда часть координат вектора измерена по количественным шкалам, а часть - по качественным, и т.д.
Анастасия Маркова