|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Опубликован: 09.11.2009 | Доступ: свободный | Студентов: 4094 / 1041 | Оценка: 4.66 / 4.45 | Длительность: 54:13:00
Темы: Математика, Экономика
Специальности: Экономист
Лекция 5:
Описание данных
5.6. Непараметрические оценки плотности
Эмпирическая функция распределения - это состоятельная непараметрическая оценка функции распределения числовой случайной величины. А как оценить плотность? Если продифференцировать эмпирическую функцию распределения, то получим бесконечности в точках, соответствующих элементам выборки, и 0 во всех остальных. Ясно, что это не оценка плотности.
Как же действовать? Каждому элементу выборки соответствует в эмпирическом распределении вероятность 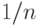 , где
, где  - объем выборки. Целесообразно эту вероятность не помещать в одну точку, а "размазать" вокруг нее, построив "холмик". Если "холмики" налегают друг на друга, то получаем положительную плотность на всей прямой. Чтобы получить состоятельную оценку плотности, необходимо выбирать ширину "холмика" в зависимости от объема выборки. При этом число "холмиков", покрывающих фиксированную точку, должно безгранично расти. Но одновременно доле таких "холмиков" следует убывать, поскольку покрывающие "холмики" должны быть порождены лишь ближайшими членами вариационного ряда.
- объем выборки. Целесообразно эту вероятность не помещать в одну точку, а "размазать" вокруг нее, построив "холмик". Если "холмики" налегают друг на друга, то получаем положительную плотность на всей прямой. Чтобы получить состоятельную оценку плотности, необходимо выбирать ширину "холмика" в зависимости от объема выборки. При этом число "холмиков", покрывающих фиксированную точку, должно безгранично расти. Но одновременно доле таких "холмиков" следует убывать, поскольку покрывающие "холмики" должны быть порождены лишь ближайшими членами вариационного ряда.
Реализация описанной идеи привела к различным вариантам непараметрических оценок плотности. Основополагающей является работа Н.В.Смирнова 1951 г. [ [ 5.26 ] ]. Вначале рассматривались непараметрические оценки плотности распределения числовых случайных величин и конечномерных случайных векторов. В 1980-х годах удалось сконструировать такие оценки в пространствах произвольной природы [ [ 5.18 ] ], а затем и для конкретных видов нечисловых данных [ [ 5.21 ] ].
Сначала рассмотрим непараметрические оценки плотности в наиболее общей ситуации. В статистике нечисловых данных выделяют общую теорию и статистику в конкретных пространствах нечисловой природы (например, статистику ранжировок). В общей теории есть два основных сюжета. Один связан со средними величинами и асимптотическим поведением решений экстремальных статистических задач, второй - с непараметрическими оценками плотности. Первый сюжет только что рассмотрен, второму посвящена заключительная часть настоящей лекции.
Понятие плотности в пространстве произвольной природы  требует специального обсуждения. В пространстве должна быть выделена некоторая специальная мера
требует специального обсуждения. В пространстве должна быть выделена некоторая специальная мера  , относительно которой будут рассматриваться плотности, соответствующие другим мерам, например, мере
, относительно которой будут рассматриваться плотности, соответствующие другим мерам, например, мере 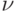 , задающей распределение вероятностей некоторого случайного элемента
, задающей распределение вероятностей некоторого случайного элемента 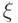 . В таком случае
. В таком случае 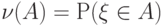 для любого случайного события
для любого случайного события  . Плотность
. Плотность 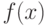 , соответствующая мере - это такая функция, что
, соответствующая мере - это такая функция, что
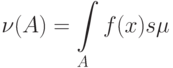
для любого случайного события . Для случайных величин и векторов мера - это объем множества , в математических терминах - мера Лебега. Для дискретных случайных величин и элементов со значениями в конечном множестве в качестве меры естественно использовать считающую меру, которая событию ставит в соответствие число его элементов. Используют также нормированную случайную меру, когда число точек в множестве делят на число точек во всем пространстве . В случае считающей меры значение плотности в точке  совпадает с вероятностью попасть в точку , т.е.
совпадает с вероятностью попасть в точку , т.е. 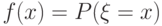 . Таким образом, с рассматриваемой точки зрения стирается грань между понятиями "плотность вероятности" и "вероятность (попасть в точку)".
. Таким образом, с рассматриваемой точки зрения стирается грань между понятиями "плотность вероятности" и "вероятность (попасть в точку)".
Как могут быть использованы непараметрические оценки плотности распределения вероятностей в пространствах нечисловой природы? Например, для решения задач классификации (диагностики, распознавания образов - см.
"Многомерный статистический анализ"
). Зная плотности распределения классов, можно решать основные задачи диагностики - как задачи выделения кластеров, так и задачи отнесения вновь поступающего объекта к одному из диагностических классов. В задачах кластер-анализа можно находить моды плотности и принимать их за центры кластеров или за начальные точки итерационных методов типа  -средних или динамических сгущений. В задачах собственно диагностики (дискриминации, распознавания образов с учителем) можно принимать решения о диагностике объектов на основе отношения плотностей, соответствующих классам. При неизвестных плотностях представляется естественным использовать их состоятельные оценки.
-средних или динамических сгущений. В задачах собственно диагностики (дискриминации, распознавания образов с учителем) можно принимать решения о диагностике объектов на основе отношения плотностей, соответствующих классам. При неизвестных плотностях представляется естественным использовать их состоятельные оценки.
Методы оценивания плотности вероятности в пространствах общего вида предложены и первоначально изучены в работе [ [ 5.18 ] ]. В частности, в задачах диагностики объектов нечисловой природы предлагаем использовать непараметрические ядерные оценки плотности типа Парзена-Розенблатта (этот вид оценок и его название впервые были введены в статье [ [ 5.18 ] ] ). Они имеют вид:
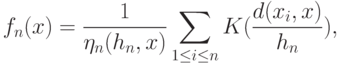
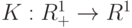 - так называемая ядерная функция,
- так называемая ядерная функция,  - выборка, по которой оценивается плотность,
- выборка, по которой оценивается плотность, 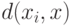 - показатель различия (метрика, расстояние, мера близости) между элементом выборки
- показатель различия (метрика, расстояние, мера близости) между элементом выборки 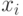 и точкой , в которой оценивается плотность, последовательность
и точкой , в которой оценивается плотность, последовательность 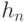 показателей размытости такова, что
показателей размытости такова, что  и
и 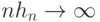 при
при 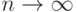 , а
, а  - нормирующий множитель, обеспечивающий выполнение условия нормировки (интеграл по всему пространству от непараметрической оценки плотности
- нормирующий множитель, обеспечивающий выполнение условия нормировки (интеграл по всему пространству от непараметрической оценки плотности  по мере должен равняться 1). Ранее американские исследователи Парзен и Розенблатт использовали подобные статистики в случае
по мере должен равняться 1). Ранее американские исследователи Парзен и Розенблатт использовали подобные статистики в случае  с
с  .
.Введенные описанным образом ядерные оценки плотности - частный случай так называемых линейных оценок, также впервые предложенных в работе [ [ 5.18 ] ]. В теоретическом плане они выделяются тем, что удается получать результаты такого же типа, что в классическом одномерном случае, но, разумеется, с помощью совсем иного математического аппарата.
Свойства непараметрических ядерных оценок плотности. Рассмотрим выборку со значениями в некотором пространстве произвольного вида. В этом пространстве предполагаются заданными показатель различия  и мера . Одна из основных идей рассматриваемого подхода состоит в том, чтобы согласовать их между собой. А именно, на их основе построим новый показатель различия
и мера . Одна из основных идей рассматриваемого подхода состоит в том, чтобы согласовать их между собой. А именно, на их основе построим новый показатель различия  , так называемый "естественный", в терминах которого проще формулируются свойства непараметрической оценки плотности. Для этого рассмотрим шары
, так называемый "естественный", в терминах которого проще формулируются свойства непараметрической оценки плотности. Для этого рассмотрим шары  радиуса
радиуса  и их меры
и их меры 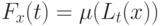 .
Предположим, что
.
Предположим, что 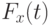 как функция
как функция 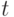 при фиксированном непрерывна и строго возрастает. Введем функцию
при фиксированном непрерывна и строго возрастает. Введем функцию 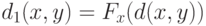 . Это - монотонное преобразование показателя различия или расстояния, а потому
. Это - монотонное преобразование показателя различия или расстояния, а потому 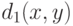 - также показатель различия (даже если - метрика, для неравенство треугольника может быть не выполнено). Другими словами, , как и
- также показатель различия (даже если - метрика, для неравенство треугольника может быть не выполнено). Другими словами, , как и 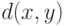 , можно рассматривать как показатель различия (меру близости) между и
, можно рассматривать как показатель различия (меру близости) между и  .
.
Для вновь введенного показателя различия введем соответствующие шары 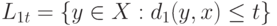 . Поскольку обратная функция
. Поскольку обратная функция 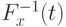 определена однозначно, то
определена однозначно, то
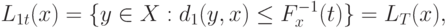
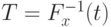 . Следовательно, справедлива цепочка равенств
. Следовательно, справедлива цепочка равенств 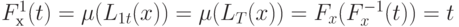 (для всех тех значений параметра , для которых определены все участвующие в записи математические объекты).
(для всех тех значений параметра , для которых определены все участвующие в записи математические объекты).Переход от к напоминает классическое преобразование, использованное Н.В. Смирновым при изучении непараметрических критериев согласия и однородности, а именно, преобразование 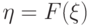 , переводящее случайную величину с непрерывной функцией распределения
, переводящее случайную величину с непрерывной функцией распределения 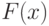 в случайную величину
в случайную величину 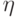 , равномерно распределенную на отрезке [0,1]. Оба рассматриваемых преобразования существенно упрощают дальнейшие рассмотрения. Преобразование
, равномерно распределенную на отрезке [0,1]. Оба рассматриваемых преобразования существенно упрощают дальнейшие рассмотрения. Преобразование  зависит от точки , что не влияет на дальнейшие рассуждения, поскольку ограничиваемся изучением сходимости в отдельно взятой точке.
зависит от точки , что не влияет на дальнейшие рассуждения, поскольку ограничиваемся изучением сходимости в отдельно взятой точке.
Функцию , для которой мера шара радиуса равна , называем в соответствии с работой [
[
5.18
]
] "естественным показателем различия" или "естественной метрикой". В случае конечномерного пространства 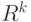 и евклидовой метрики имеем
и евклидовой метрики имеем 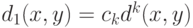 , где
, где 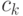 - объем шара единичного радиуса в .
- объем шара единичного радиуса в .
Поскольку можно записать, что
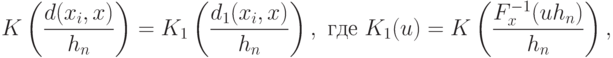 к , соответствует переходу от одной ядерной функции к другой, т.е. от
к , соответствует переходу от одной ядерной функции к другой, т.е. от 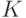 к
к 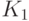 . Выгода от такого перехода заключается в том, что утверждения о поведении непараметрических оценок плотности приобретают более простую формулировку.
. Выгода от такого перехода заключается в том, что утверждения о поведении непараметрических оценок плотности приобретают более простую формулировку.Теорема 5. Пусть - естественная метрика, плотность  непрерывна в точке и ограничена на всем пространстве , причем
непрерывна в точке и ограничена на всем пространстве , причем 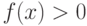 , ядерная функция
, ядерная функция 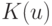 удовлетворяет простым условиям регулярности
удовлетворяет простым условиям регулярности
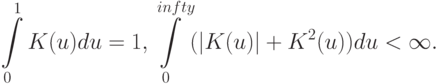
Тогда 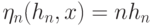 , оценка является состоятельной, т.е.
, оценка является состоятельной, т.е. 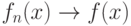 по вероятности при и, кроме того,
по вероятности при и, кроме того,
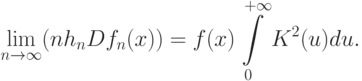
Теорема 5 доказывается методами, развитыми в работе [
[
5.18
]
]. Однако остается открытым вопрос о скорости сходимости ядерных оценок, в частности, о поведении величины 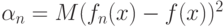 - среднего квадрата ошибки, и об оптимальном выборе показателей размытости . Для того, чтобы продвинуться в решении этого вопроса, введем новые понятия. Для случайного элемента
- среднего квадрата ошибки, и об оптимальном выборе показателей размытости . Для того, чтобы продвинуться в решении этого вопроса, введем новые понятия. Для случайного элемента  со значениями в рассмотрим так называемое круговое распределение
со значениями в рассмотрим так называемое круговое распределение 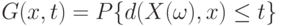 и круговую плотность
и круговую плотность  .
.
Теорема 6. Пусть ядерная функция непрерывна и финитна, т.е. существует число 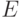 такое, что
такое, что 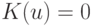 при
при 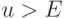 . Пусть круговая плотность является достаточно гладкой, т.е. допускает разложение
. Пусть круговая плотность является достаточно гладкой, т.е. допускает разложение
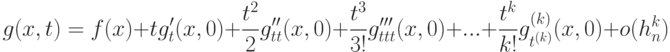 , причем остаточный член равномерно ограничен на
, причем остаточный член равномерно ограничен на ![[0,hE]](/sites/default/files/tex_cache/87c5e527bc649b4694cf9a473dc5b0af.png) .
.Пусть

Тогда
![\begin{gathered}
\alpha_n=[Mf_n(x)-f(x)]^2+Df_n(x)= \\
=h_n^{2k}\left(\int\limits_0^E u^k K(u)du\right)^2
(g_{t^{(k)}}^k(x,0))^2+\frac{f(x)}{nh_n}\int\limits_0^E K^2(u)du+\\
+o\left(h_n^{2k}+\frac{1}{nh_n}\right).
\end{gathered}](/sites/default/files/tex_cache/62a4c965e08597dec8b3ad42396518e1.png)
Доказательство теоремы 6 проводится с помощью разработанной в статистике объектов нечисловой природы математической техники, образцы которой представлены, в частности, в работе [
[
5.18
]
]. Если коэффициенты при основных членах в правой части последней формулы не равны 0, то величина  достигает минимума, равного
достигает минимума, равного  при
при  . Эти выводы совпадают с классическими результатами, полученными ранее рядом авторов для весьма частного случая прямой
. Эти выводы совпадают с классическими результатами, полученными ранее рядом авторов для весьма частного случая прямой  (см., например, монографию [
[
4.7
]
, с.316]). Заметим, что для уменьшения смещения оценки приходится применять знакопеременные ядра .
(см., например, монографию [
[
4.7
]
, с.316]). Заметим, что для уменьшения смещения оценки приходится применять знакопеременные ядра .
Непараметрические оценки плотности в конечных пространствах [
[
5.21
]
]. В случае пространств из конечного числа элементов естественных метрик не существует. Однако можно получить аналоги теорем 5 и 6, переходя к пределу не только по объему выборки , но и по новому параметру дискретности  .
.
Рассмотрим некоторую последовательность  ., конечных пространств. Пусть в
., конечных пространств. Пусть в  заданы показатели различия
заданы показатели различия  . Будем использовать нормированные считающие меры ставящие в соответствие каждому подмножеству долю элементов всего пространства , входящих в . Как и ранее, рассмотрим как функцию объем шара радиуса , т.е.
. Будем использовать нормированные считающие меры ставящие в соответствие каждому подмножеству долю элементов всего пространства , входящих в . Как и ранее, рассмотрим как функцию объем шара радиуса , т.е.
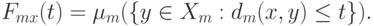
Введем аналог естественного показателя различия 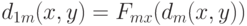 . Наконец, рассмотрим аналоги преобразования Смирнова
. Наконец, рассмотрим аналоги преобразования Смирнова 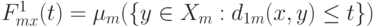 . Функции
. Функции 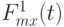 , в отличие от ранее рассмотренной ситуации, уже не совпадают тождественно с , они кусочно-постоянны и имеют скачки в некоторых точках
, в отличие от ранее рассмотренной ситуации, уже не совпадают тождественно с , они кусочно-постоянны и имеют скачки в некоторых точках 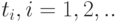 ., причем в этих точках
., причем в этих точках  .
.
Теорема 7. Пусть точки скачков равномерно сближаются, т.е. 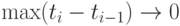 при
при  (другими словами,
(другими словами, 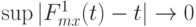 при ). Тогда существует последовательность параметров дискретности
при ). Тогда существует последовательность параметров дискретности 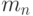 такая, что при предельном переходе
такая, что при предельном переходе 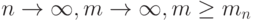 справедливы заключения теорем 5 и 6.
справедливы заключения теорем 5 и 6.
Пример 1. Пространство 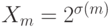 всех подмножеств конечного множества
всех подмножеств конечного множества  из элементов допускает (см.
"Различные виды статистических данных"
и монографию [
[
1.15
]
]) аксиоматическое введение метрики
из элементов допускает (см.
"Различные виды статистических данных"
и монографию [
[
1.15
]
]) аксиоматическое введение метрики  где
где  - символ симметрической разности множеств. Рассмотрим непараметрическую ядерную оценку плотности типа Парзена-Розенблатта
- символ симметрической разности множеств. Рассмотрим непараметрическую ядерную оценку плотности типа Парзена-Розенблатта

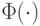 - функция нормального стандартного распределения. Можно показать, что эта оценка удовлетворяет условиям теоремы 7 с
- функция нормального стандартного распределения. Можно показать, что эта оценка удовлетворяет условиям теоремы 7 с  .
.Пример 2. Рассмотрим пространство функций 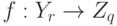 определенных на конечном множестве
определенных на конечном множестве  , со значениями в конечном множестве
, со значениями в конечном множестве  . Это пространство можно интерпретировать как пространство нечетких множеств (см.
"Различные виды статистических данных"
), а именно,
. Это пространство можно интерпретировать как пространство нечетких множеств (см.
"Различные виды статистических данных"
), а именно,  - носитель нечеткого множества, а
- носитель нечеткого множества, а 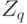 - множество значений функции принадлежности. Очевидно, число элементов пространства равно
- множество значений функции принадлежности. Очевидно, число элементов пространства равно  . Будем использовать расстояние
. Будем использовать расстояние 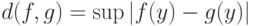 . Непараметрическая оценка плотности имеет вид:
. Непараметрическая оценка плотности имеет вид:
![f_{nm}(x)=\frac{1}{nh_n}\sum_{i=1}^n K
\left(
\frac{[2\sup_y|x(y)-x_i(y)|+1/q]^r}{h_n(1+1/q)^r}
\right).](/sites/default/files/tex_cache/3a66163f0a4c7834b92de90e7d4a07b6.png)
Если 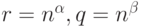 , то при
, то при 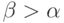 выполнены условия теоремы 7, а потому справедливы теоремы 5 и 6.
выполнены условия теоремы 7, а потому справедливы теоремы 5 и 6.
Пример 3. Рассматривая пространства ранжировок объектов, в качестве расстояния 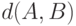 между ранжировками и
между ранжировками и 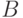 примем минимальное число инверсий, необходимых для перехода от к . Тогда
примем минимальное число инверсий, необходимых для перехода от к . Тогда 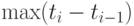 не стремится к 0 при , условия теоремы 7 не выполнены.
не стремится к 0 при , условия теоремы 7 не выполнены.
Пример 4. В прикладных работах наиболее распространенный пример объектов нечисловой природы - вектор разнотипных данных: реальный объект описывается вектором, часть координат которого - значения количественных признаков, а часть - качественных (номинальных и порядковых). Для пространств разнотипных признаков, т.е. декартовых произведений непрерывных и дискретных пространств, возможны различные постановки. Пусть, например, число градаций качественных признаков остается постоянным. Тогда непараметрическая оценка плотности сводится к произведению двух величин - частоты попадания в точку в пространстве качественных признаков и классической оценки типа Парзена-Розенблатта в пространстве количественных переменных. В общем случае расстояние можно, например, рассматривать как сумму трех расстояний.
А именно, евклидова расстояния между количественными факторами, расстояния 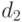 между номинальными признаками
между номинальными признаками  , если
, если 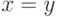 , и
, и 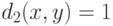 , если
, если  ) и расстояния
) и расстояния 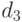 между порядковыми переменными (если и - номера градаций, то
между порядковыми переменными (если и - номера градаций, то  . Наличие количественных факторов приводит к непрерывности и строгому возрастанию функции
. Наличие количественных факторов приводит к непрерывности и строгому возрастанию функции  , а потому для непараметрических оценок плотности в пространствах разнотипных признаков верны теоремы 5 - 6.
, а потому для непараметрических оценок плотности в пространствах разнотипных признаков верны теоремы 5 - 6.
Программная реализация описания числовых данных с помощью непараметрических оценок плотности включена в ряд программных продуктов по прикладной статистике, в частности, в пакет программ анализа данных ППАНД [ [ 5.19 ] ].
Контрольные вопросы и задачи
- Часто ли результаты измерений имеют нормальное распределение?
- По выборке фактических данных о величине годового дохода (в тыс. долл.), взятых на конец 1970-х гг. (США), постройте вариационный ряд, гистограмму (группируя данные по 6-ти равным интервалам); определите выборочные среднее арифметическое, медиану и моду:
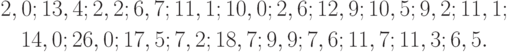
- Дано распределение по градациям (табл.1) почасовой заработной платы 303 рабочих, занятых в промышленности (
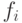 - число рабочих, имеющих почасовую заработную плату ). Постройте эмпирическую функцию распределения, найдите выборочные медиану, моду и среднее арифметическое.
- число рабочих, имеющих почасовую заработную плату ). Постройте эмпирическую функцию распределения, найдите выборочные медиану, моду и среднее арифметическое.
- Какие средние величины целесообразно использовать при расчете средней заработной платы (или среднего дохода)?
- Постройте пример, показывающий некорректность использования среднего арифметического
 в порядковой шкале, используя допустимое преобразование
в порядковой шкале, используя допустимое преобразование  (при положительных усредняемых величинах ).
(при положительных усредняемых величинах ). - Постройте пример, показывающий некорректность использования среднего геометрического в порядковой шкале. Другими словами, приведите пример чисел
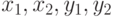 и строго возрастающего преобразования
и строго возрастающего преобразования  таких, что
таких, что![(x_1x_2)^{1/2}<(y_1y_2)^{1/2},[f(x_1)f(x_2)]^{1/2}>[f(y_1)f(y_2)]^{1/2}.](/sites/default/files/tex_cache/9cf0c778d91b7e5f04d7e95ba347f456.png)
- Приведите пример чисел и строго возрастающего преобразования
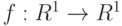 таких, что
таких, что![\begin{gathered}
{[}(x_1)^2+(x_2)^2]^{1/2}<[(y_1)^2+(y_2)^2]^{1/2}, \\
[(f(x_1))^2+(f(x_2))^2]^{1/2}>[(y(y_1))^2+(f(y_2))^2]^{1/2}.
\end{gathered}](/sites/default/files/tex_cache/27f6a1cf3cfdde64b9fd9e535a504fda.png)
- Какая математическая модель используется для описания случайного множества?
- Как соотносятся эмпирические и теоретические средние для числовых данных и в пространствах произвольной природы?
- Почему описание числовых данных с помощью непараметрических оценок плотности предпочтительнее их описания с помощью гистограмм?
Темы докладов, рефератов, исследовательских работ
- Проведите описание данных, приведенных в табл.5.1 (п.5.2). Постройте таблицы (типа табл.5.2 и 5.3 там же), рассчитайте выборочные характеристики.
- Показатели разброса, связи, показатели различия (в том числе метрики) в порядковой шкале.
- Ранговые методы математической статистики как инвариантные методы анализа порядковых данных.
- Показатели разброса, связи, показатели различия (в том числе метрики) в шкале интервалов.
- Показатели разброса, связи, показатели различия (в том числе метрики) в шкале отношений.
- Теорема В.В. Подиновского: любое изменение коэффициентов весомости единичных показателей качества продукции приводит к изменению упорядочения изделий по средневзвешенному показателю.
- Вероятностные модели бинарных отношений.
- Вероятностные модели парных сравнений.
- Средние и законы больших чисел в пространстве упорядочений.
- Непараметрические оценки плотности в непрерывных и дискретных пространствах.
Анастасия Маркова