|
Добрый день можно поинтересоваться где брать литературу предложенную в курсе ?Большинство книг я не могу найти в известных источниках |
Московский государственный университет путей сообщения
Опубликован: 06.09.2012 | Доступ: свободный | Студентов: 1275 / 195 | Оценка: 5.00 / 5.00 | Длительность: 35:22:00
Темы: САПР, Аппаратное обеспечение
Специальности: Разработчик аппаратуры
Лекция 28:
Словари неисправностей и способы их организации
Аннотация: В лекции описан классический словарь неисправностей, применяемый при контроле ЦУ и локализации его неисправностей. Представлены его различные модификации, включая таблицу неисправностей, компактный словарь, словари с использованием сверток и организацией по выходам.
Ключевые слова: размерность, значение, таблица, список, вектор, бит, место, представление, количество информации, единица, реакция, свертка, множества, алгоритм, подтаблица, выход, объект, работ
В отличие от компактного тестирования, когда применение определенного метода требует построения специального диагностического теста, а возможно и специального проектирования устройства, методы диагностирования с использованием словарей неисправностей строятся в предположении, что диагностический тест построен заранее и позволяет с достаточной степенью точности определить техническое состояние объекта диагностирования.
Простейшая организация словаря неисправностей - словарь полной реакции (СПР) - была описана в предыдущей лекции.Напомним, что СПР представляет собой 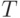 - ТФН. Объем такого словаря при большой длине диагностического теста составляет значительную величину. Для сокращения этого объема предпринималось множество подходов. Ниже рассматриваются основные из них.
- ТФН. Объем такого словаря при большой длине диагностического теста составляет значительную величину. Для сокращения этого объема предпринималось множество подходов. Ниже рассматриваются основные из них.
28.1.Классические словари неисправностей
В работе [1] рассматривается другая организация информации, представленной в СПР. Построим вспомогательную таблицу на основе СПР (имеющую ту же размерность), которую назовем таблицей обнаружения неисправностей. В клетке этой таблицы на пересечении 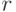 -ой строки и
-ой строки и  -го столбца проставим значение
-го столбца проставим значение  , где
, где  обозначает поразрядную операцию сложения по модулю два.
обозначает поразрядную операцию сложения по модулю два.
Для схемы  на рис. 27.1 с множеством возможных неисправностей, представленным в табл. 27.1, и со словарем неисправностей из табл. 27.5 такая вспомогательная таблица приведена в табл. 28.1.
на рис. 27.1 с множеством возможных неисправностей, представленным в табл. 27.1, и со словарем неисправностей из табл. 27.5 такая вспомогательная таблица приведена в табл. 28.1.

|
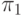
|

|

|
|
|---|---|---|---|---|

|
00 | 00 | 00 | 00 |
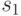
|
01 | 10 | 00 | 00 |
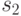
|
11 | 00 | 00 | 00 |

|
11 | 00 | 11 | 00 |
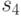
|
10 | 00 | 11 | 00 |

|
10 | 00 | 10 | 00 |
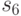
|
10 | 00 | 10 | 10 |
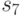
|
01 | 00 | 01 | 00 |

|
00 | 11 | 00 | 00 |
Вследствие того, что каждая неисправность обнаруживается обычно небольшим количеством тестовых воздействий, в [1] было предложено изменить организацию информации в этой таблице следующим образом: для каждой неисправности сохранять список пар номер тестового воздействия:выходная реакция для всех обнаруживающих эту неисправность тестовых воздействий. Каждую такую пару называют реакцией обнаружения, а полученную в результате построения структуру называют вектором обнаружения неисправностей.
Для схемы вектор обнаружения неисправностей представлен в табл. 28.2.
Похожая организация этой же информации называется списком обнаружения неисправностей. В нем для каждой неисправности сохраняется список пар номер тестового воздействия:номер выхода, соответствующих единицам в таблице обнаружения неисправностей. Каждую такую пару называют точкой обнаружения.
Для схемы список обнаружения неисправностей представлен в табл. 28.3.
В табл. 28.4 приведен список последовательностей обнаружения, о котором будет сказано ниже.
Естественно, что для технического состояния в вектор обнаружения неисправностей не будет помещено ни одной реакции обнаружения, а в список обнаружения неисправностей - ни одной точки обнаружения.
Объем информации, необходимой для хранения одной реакции обнаружения, равен 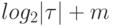 , точки обнаружения -
, точки обнаружения -  бит, а следовательно, объем информации для сохранения всего вектора обнаружения неисправностей равен
бит, а следовательно, объем информации для сохранения всего вектора обнаружения неисправностей равен
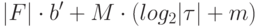
бит, а для сохранения списка обнаружения неисправностей -
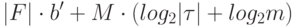
бит, где 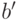 - количество бит, необходимых для отделения данных по одной неисправности от остальной информации,
- количество бит, необходимых для отделения данных по одной неисправности от остальной информации,  - общее число реакций обнаружения или точек обнаружения соответственно,
- общее число реакций обнаружения или точек обнаружения соответственно, 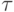 - использовнный тест,
- использовнный тест,  - количество выходных переменных объекта диагностирования.
- количество выходных переменных объекта диагностирования.
Из построения таблицы вектора и списка обнаружения неисправностей очевидно, что величина оценки глубины диагностирования с использованием этих структур вместо СПР не изменяется.
Для списка обнаружения неисправностей, как впрочем и для вектора обнаружения неисправностей, можно легко произвести дальнейшее сокращение его объема. В частности, можно для каждой неисправности оставить лишь те точки обнаружения, которые в процессе диагностирования однозначно идентифицируют каждую неисправность.
Так, для примера, если точки обнаружения и не будут иметь место, то сформируется список подозреваемых неисправностей  , и тогда наличие точки обнаружения уже однозначно идентифицирует неисправное состояние , а значит необходимость проверки точки обнаружения для этого состояния отпадает.
Сокращенный таким образом список неисправностей приведен в табл. 28.5.
, и тогда наличие точки обнаружения уже однозначно идентифицирует неисправное состояние , а значит необходимость проверки точки обнаружения для этого состояния отпадает.
Сокращенный таким образом список неисправностей приведен в табл. 28.5.
Можно проводить дальнейшее сокращение объема такого варианта словаря неисправностей, например, за счет ограничения максимального числа точек обнаружения для каждой неисправности. Но такое сокращение может привести к потере в разрешающей способности диагностирования. Так, например, ограничим количество точек обнаружения в списке обнаружения неисправностей из табл. 28.5 двумя точками. Результат такого сокращения приведен в табл. 28.6.
В результате такого сокращения становятся неразличимыми между собой состояния из множеств 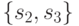 и
и  .
.
В работе [2] предложена организация словаря неисправностей, похожая на представление информации в виде списка обнаружения неисправностей. Но здесь точки обнаружения, соответствующие одним и тем же тестовым воздействиям, объединяются в пару номер тестового воздействия:последовательность номеров выходов. Такой словарь называют списком последовательностей обнаружения. Пример такого словаря приведен в табл. 28.4. При такой организации словаря для отделения одних элементов списка от других необходим разделитель (в примере в качестве разделителя взят символ ":"). Количество информации, необходимой для хранения такого словаря, уменьшается за счет удаления повторений идентификаторов тестового воздействия, но в то же время возникает необходимость увеличения информации за счет добавления разделителей.
Дмитрий Медведевских