


|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2182 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 16:
Внешний поиск
Индексно-последовательный доступ
Прямой подход к построению индекса заключается в сохранении массива c ключами и ссылками на элементы, упорядоченного по ключам, с последующим использованием бинарного поиска (см. "Таблицы символов и деревья бинарного поиска" ) для реализации операции найти. Для N элементов этот метод потребовал бы lgN проб, даже в случае очень большого файла. Наша базовая модель немедленно приводит нас к рассмотрению двух модификаций этого простого метода. Во-первых, индекс и сам по себе очень велик и обычно не помещается на одной странице. Поскольку доступ к страницам можно получить только через ссылки на страницы, вместо этого можно построить явное полностью сбалансированное бинарное дерево с ключами и указателями на страницы во внутренних узлах и с ключами и указателями на элементы во внешних. Во-вторых, затраты на доступ к M записям таблицы не отличаются от затрат на доступ к двум записям, поэтому можно воспользоваться M-арным деревом при таких же затратах на каждый узел, как и для бинарного дерева. Такое усовершенствование уменьшает количество проб до пропорционального приблизительно logMN. Как было показано в "Поразрядная сортировка" и "Поразрядный поиск" , это значение можно считать практически постоянным. Например, если M= 1000, то logMN меньше 5 для всех N, меньших 1 триллиона.
На рис. 16.1 приведен пример набора ключей, а на рис. 16.2 — пример такой структуры дерева для этих ключей. Чтобы примеры были достаточно понятными, приходится использовать сравнительно небольшие значения M и N, но все же из этих примеров видно, что деревья для большого значения M будут плоскими.
Ключи (слева), используемые в примерах этой главы, представляют собой трехзначные восьмеричные числа, которые будут также интерпретироваться как 9-разрядные двоичные значения (справа).
Дерево на рис. 16.2 рис. 16.2 является абстрактным представлением индекса, оно не зависит от устройства и похоже на множество других рассмотренных нами структур данных. Однако оно не особо отличается от зависящих от устройств индексов, которые можно встретить в программном обеспечении низкоуровневого доступа к дискам.
Например, в ряде ранних систем использовалась двухуровневая схема, в которой нижний уровень соответствовал элементам на страницах конкретного дискового устройства, а второй уровень — главному индексу отдельных устройств. В таких системах главный индекс хранился в оперативной памяти, поэтому для доступа к элементу с помощью такого индекса требовались две операции доступа: одна для чтения индекса и вторая для чтения страницы, содержащей элемент. С увеличением емкости дисков возрастали и размеры индексов, и для хранения индекса требовалось уже несколько страниц, что со временем привело к использованию иерархической схемы наподобие показанной на рис. 16.2. Мы продолжим работать с абстрактным представлением, помня, что при необходимости оно может быть непосредственно реализовано с помощью типичного аппаратного и программного обеспечения низкого уровня.
Во многих современных системах аналогичная древовидная структура используется для организации очень больших файлов в виде последовательности дисковых страниц. Такие деревья не содержат ключей, но они могут эффективно поддерживать стандартные операции последовательного доступа к файлу, и (если каждый узел содержит счетчик размера его дерева) нахождения страницы, содержащей к-й элемент файла.
Поскольку метод индексации, показанный на рис. 16.2, сочетает последовательную организацию ключей с индексным доступом, по историческим причинам он называется индексно-последовательным доступом (indexed sequential access). Этот метод удобен для приложений, в которых изменения в базе данных выполняются редко. Иногда сам индекс называют каталогом (directory). Недостаток использования индексно-последовательного доступа заключается в больших затратах на изменение каталога. Например, для добавления единственного ключа может потребоваться перестройка буквально всей базы данных с присвоением новых позиций многим ключам и новых значений индексам. Для преодоления этого недостатка и обеспечения возможности небольшого увеличения базы данных в ранних системах на дисках резервировались страницы переполнения, а в страницах — области переполнения; но все равно в динамических ситуациях такие технологии были не очень эффективны (см. упражнение 16.3). Методы, которые будут рассматриваться в разделах 16.3 и 16.4, обеспечивают надежные и эффективные альтернативы таким элементарным схемам.
Лемма 16.1. Для выполнения поиска в индексно-последовательном файле требуется выполнение лишь постоянного количества проб, однако вставка может вызвать перестройку всего индекса.
В данном случае (и вообще в этой главе) термин постоянный используется нестрого и обозначает величину, пропорциональную
logMN
для больших M. Как уже было сказано, это оправдано для размеров реальных файлов. На
рис.
16.3 показаны дополнительные примеры. Даже при наличии 128-битного ключа поиска, пригодного для указания неимоверно огромного количества (2128) различных элементов, при 1000-путевом ветвлении элемент с заданным ключом можно найти при помощи всего 13 проб. 
В последовательном индексе ключи хранятся упорядоченными в полных страницах (справа), а индекс указывает на наименьший ключ в каждой странице (слева). При добавлении ключа требуется перестроить всю структуру данных.
Эти впечатляющие граничные значения позволяют смело принять, что на практике вряд ли встретится таблица символов, содержащая более 1030 элементов. Даже в такой неимоверно большой базе данных при 1000-путевом ветвлении элемент с заданным ключом можно найти с помощью менее 10 проб. И даже если бы как-то удалось записать информацию о каждом электроне во Вселенной, 1000-путевое ветвление позволило бы получить доступ к любому конкретному элементу с помощью менее 27 проб.
Мы не будем рассматривать реализации поиска и построения индексов подобного типа, поскольку они представляют собой специальные случаи более общих механизмов, рассматриваемых в следующем разделе (см. упражнение 16.17 и программу 16.2).
Упражнения
16.1. Составьте таблицу значений logM N для M= 10, 100 и 1000 и N= 103, 104, 105 и 106 .
16.2. Нарисуйте структуру индексно-последовательного файла для ключей 516, 177, 143, 632, 572, 161, 774, 470, 411, 706, 461, 612, 761, 474, 774, 635, 343, 461, 351, 4 30, 664, 127, 34 5, 171 и 357 при M= 5 и N= 6.
16.3. Предположим, что мы строим структуру индексно-последовательного файла для N элементов, со страницами емкостью M, но оставляем на каждой странице к свободных мест для возможного расширения. Приведите формулу для определения количества проб, необходимых для выполнения поиска, в виде функции от N, M и к. Используйте эту формулу для определения количества проб, необходимых для выполнения поиска при k = M/10, M= 10, 100 и 1000 и N= 103, 104, 105 и 106 .
16.4. Предположим, что затраты на одну пробу равны приблизительно а единиц времени, а средние затраты на поиск элемента на странице составляют приблизительно PM единиц времени. Найдите значение M, при котором затраты на поиск в структуре индексно-последовательного файла минимальны, при 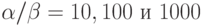 и
N= 103, 104, 105 и 106
.
и
N= 103, 104, 105 и 106
.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |