Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2202 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 14:
Хеширование
Ключевые слова: операции, хеширование, hashing, вычисление, hash function, ключ, адрес, collision, resolution, производительность, поиск, время выполнения, значение
Рассмотренные нами алгоритмы поиска обычно основаны на абстрактной операции сравнения. Из этого ряда существенно выделяется метод распределяющего поиска, описанный в "Таблицы символов и деревья бинарного поиска" , при котором элемент с ключом i хранится в i-ой позиции таблицы, что позволяет обратиться к нему непосредственно. При распределяющем поиске значения ключей используются в качестве индексов массива, а не операндов операции сравнения; сам метод основан на том, что ключи являются различными целыми числами из того же диапазона, что и индексы таблицы. В этой главе мы рассмотрим хеширование (hashing) — расширенный вариант распределяющего поиска, применяемый в более типичных приложениях поиска, где ключи не обладают столь удобными свойствами. Конечный результат применения данного подхода совершенно не похож на методы, основанные на сравнении — вместо перемещения по структурам данных словаря с помощью сравнения ключей поиска с ключами в элементах, мы пытаемся обратиться к элементам в таблице непосредственно, выполняя арифметическое преобразование ключей в адреса таблицы.
Алгоритмы поиска, использующие хеширование, состоят из двух отдельных частей. Первый шаг — вычисление хеш-функции (hash function), которая преобразует ключ поиска в адрес в таблице. В идеале различные ключи должны были бы отображаться на различные адреса, но часто два или более различных ключа могут дать один и тот же адрес в таблице. Поэтому вторая часть поиска методом хеширования — процесс разрешения коллизий (collision resolution), который обрабатывает такие ключи. В одном из методов разрешения конфликтов, который мы рассмотрим в этой главе, используются связные списки, поэтому он находит непосредственное применение в динамических ситуациях, когда трудно заранее предугадать количество ключей поиска. В других двух методах разрешения коллизий достигается высокая производительность поиска, поскольку элементы хранятся в фиксированном массиве. Мы рассмотрим способ усовершенствования этих методов, позволяющий использовать их и в тех случаях, когда нельзя заранее предсказать размеры таблицы.
Хеширование — хороший пример баланса между временем и объемом памяти. Если бы не было ограничения на объем используемой памяти, любой поиск можно было бы выполнить с помощью всего лишь одного обращения к памяти, просто используя ключ в качестве адреса памяти, как при распределяющем поиске. Однако обычно этот идеальный случай недостижим, поскольку для длинных ключей может потребоваться огромный объем памяти. С другой стороны, если бы не было ограничений на время выполнения, можно было бы обойтись минимальным объемом памяти, пользуясь методом последовательного поиска. Хеширование представляет собой способ использования приемлемого объема как памяти, так и времени, и достижения баланса между этими двумя крайними требованиями. В частности, можно поддерживать любой баланс, просто меняя размер таблицы, а не переписывая код и не выбирая другие алгоритмы.
Хеширование — одна из классических задач компьютерных наук: его различные алгоритмы подробно исследованы и находят широкое применение. Мы увидим, что при совсем не жестких допущениях можно надеяться на поддержку операций найти и вставить в таблицах символов с постоянным временем выполнения, независимо от размера таблицы.
Это ожидаемое значение — теоретический оптимум производительности для любой реализации таблицы символов, но хеширование все же не является панацеей по двум основным причинам. Во-первых, время выполнения зависит от длины ключа, которая в реальных приложениях, использующих длинные ключи, может быть значительной. Во-вторых, хеширование не обеспечивает эффективные реализации других операций с таблицами символов, таких, как выбрать или сортировать. В этой главе мы подробно рассмотрим эти и другие вопросы.
Хеш-функции
Прежде всего необходимо решить задачу вычисления хеш-функции, преобразующей ключи в адреса таблицы. Обычно реализация этого арифметического вычисления не представляет сложности, но все же необходимо соблюдать осторожность, чтобы не нарваться на различные малозаметные подводные камни. При наличии таблицы, которая может содержать M элементов, нужна функция, преобразующая ключи в целые числа в диапазоне [0, M — 1]. Идеальная хеш-функция должна легко вычисляться и быть похожей на случайную функцию: для любых аргументов результаты в некотором смысле должны быть равновероятными.
Хеш-функция зависит от типа ключа. Строго говоря, для каждого возможного вида ключей требуется отдельная хеш-функция. Для повышения эффективности обычно желательно избегать явного преобразования типов, обратившись вместо этого к идее рассмотрения двоичного представления ключей в машинном слове в виде целого числа, которое можно использовать в арифметических вычислениях. Хеширование появилось до языков высокого уровня — на ранних компьютерах было обычным делом рассматривать какое-либо значение то как строковый ключ, то как целое число. В некоторых языках высокого уровня затруднительно создавать программы, которые зависят от представления ключей в конкретном компьютере, поскольку такие программы, по сути, являются машинно-зависимыми, и поэтому их трудно перенести на другой компьютер. Обычно хеш-функции зависят от процесса преобразования ключей в целые числа, поэтому в реализациях хеширования бывает трудно одновременно обеспечить и машинную независимость, и эффективность. Как правило, простые целочисленные ключи или ключи типа с плавающей точкой можно преобразовать с помощью всего одной машинной операции, но строковые ключи и другие типы составных ключей требуют больших затрат и большего внимания к эффективности.
Вероятно, простейшей является ситуация, когда ключами являются числа с плавающей точкой из фиксированного диапазона. Например, если ключи — числа, большие 0 и меньшие 1, их можно просто умножить на M, округлить результат до меньшего целого числа и получить адрес в диапазоне между 0 и M — 1; такой пример показан на рис. 14.1. Если ключи больше s и меньше t, их можно масштабировать, вычтя s и разделив на t—s, в результате чего они попадут в диапазон значений между 0 и 1, а затем умножить на M и получить адрес в таблице.

Для преобразования чисел с плавающей точкой в диапазоне между 0 и 1 в индексы таблицы, размер которой равен 97, выполняется умножение этих чисел на 97. В данном примере произошло три коллизии: для индексов, равных 17, 53 и 76. Хеш-значения определяются старшими разрядами ключа, младшие разряды не играют никакой роли. Одна из целей разработки хеш-функции — устранение такого дисбаланса, чтобы во время вычисления учитывался каждый разряд.
Если ключи являются w-разрядными целыми числами, их можно преобразовать в числа с плавающей точкой и разделить на 2w для получения чисел с плавающей точкой в диапазоне между 0 и 1, а затем умножить на M, как в предыдущем абзаце. Если операции с плавающей точкой занимают много времени, а числа не столь велики, чтобы привести к переполнению, этот же результат может быть получен с помощью целочисленных арифметических операций: нужно ключ умножить на M, а затем выполнить сдвиг вправо на w разрядов для деления на 2w (или, если умножение приводит к переполнению, выполнить сдвиг, а затем умножение). Такие методы бесполезны для хеширования, если только ключи не распределены по диапазону равномерно, поскольку хеш-значение определяется только ведущими цифрами ключа.
Более простой и эффективный метод для w-разрядных целых чисел — один из, пожалуй, наиболее часто используемых методов хеширования — выбор в качестве размера M таблицы простого числа и вычисление остатка от деления к на M, т.е. h(k) = k mod M для любого целочисленного ключа k. Такая функция называется модульной хеш-функцией. Ее очень просто вычислить (k % M в языке C++), и она эффективна для достижения равномерного распределения значений ключей между значениями, меньшими M. Небольшой пример показан на рис. 14.2.
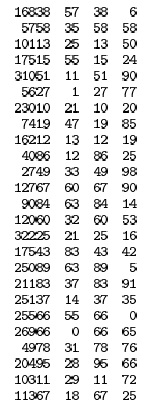
В трех правых столбцах показан результат хеширования 16-разрядных ключей, приведенных слева, с помощью следующих функций:
v % 97 (слева)
v % 100 (в центре) и
(int) (a * v) % 100 (справа),
где a = .618033. Размеры таблицы для этих функций соответственно равны 97, 100 и 100. Значения выглядят случайными (поскольку случайны ключи). Вторая функция (v % 100) использует лишь две крайние правые цифры ключей и поэтому для неслучайных ключей может показывать низкую производительность.
Модульное хеширование применимо и к ключам с плавающей точкой. Если ключи принадлежат небольшому диапазону, можно масштабировать их в числа из диапазона между 0 и 1, 2w для получения w-разрядных целочисленных значений, а затем использовать модульную хеш-функцию. Другой вариант — просто использовать в качестве операнда модульной хеш-функции двоичное представление ключа (если оно доступно).
Модульное хеширование применяется во всех случаях, когда имеется доступ к битам, из которых состоят ключи, независимо от того, являются ли они целыми числами, представленными машинным словом, последовательностью символов, упакованных в машинное слово, или представлены любым другим возможным вариантом. Последовательность случайных символов, упакованная в машинное слово — не совсем то же, что случайные целочисленные ключи, поскольку не все разряды используются для кодирования. Но оба эти типа (и любой другой тип ключа, закодированный так, чтобы уместиться в машинном слове) можно заставить выглядеть случайными индексами в небольшой таблице.
Основная причина выбора в качестве размера M хеш-таблицы простого числа для модульного хеширования показана на рис. 14.3. В этом примере символьных данных с 7-разрядным кодированием ключ трактуется как число с основанием 128 — по одной цифре для каждого символа в ключе. Слово now соответствует числу 1816567, которое может быть также записано как

поскольку в ASCII-коде символам n, o и w соответствуют числа 1568 = 110, 1578 = 111 и 1678 = 119. Выбор размера таблицы M = 64 для этого типа ключа неудачен, поскольку добавление к х значений, кратных 64 (или 128), не меняет значение х mod 64 — для любого ключа значением хеш-функции является значение последних 6 разрядов этого ключа. Безусловно, хорошая хеш-функция должна учитывать все разряды ключа, особенно для символьных ключей. Аналогичные ситуации могут возникать, когда M содержит множитель, являющийся степенью 2. Простейший способ избежать этого — выбрать в качестве M простое число.
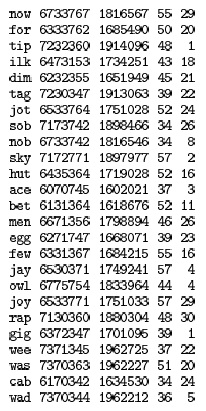
В каждой строке этой таблицы приведены: 3-буквенное слово, представление этого слова в ASCII-коде как 21-битовое число в восьмеричной и десятичной формах и стандартные модульные хеш-функции для размеров таблиц 64 и 31 (два крайних справа столбца). Размер таблицы 64 приводит к нежелательным результатам, поскольку для получения хеш-значения используются только самые правые разряды ключа, а буквы в словах обычного языка распределены неравномерно. Например, всем словам, оканчивающимся на букву у, соответствует хеш-значение 57. И, напротив, простое значение 31 вызывает меньше коллизий в таблице более чем вдвое меньшего размера.
Модульное хеширование очень просто реализовать, за исключением того, что размер таблицы должен быть простым числом. Для некоторых приложений можно довольствоваться небольшим известным простым числом или же поискать в списке известных простых чисел такое, которое близко к требуемому размеру таблицы. Например, числа равные 2t — 1, являются простыми при t = 2, 3, 5, 7, 13, 17, 19 и 31 (и ни при каких других значениях t < 31): это известные простые числа Мерсенна. Чтобы динамически распределить таблицу нужного размера, нужно вычислить простое число, близкое к этому значению. Такое вычисление нетривиально (хотя для этого и существует остроумный алгоритм, который будет рассмотрен в части 5), поэтому на практике обычно используют таблицу заранее вычисленных значений (см. рис. 14.4). Использование модульного хеширования — не единственная причина, по которой размер таблицы стоит сделать простым числом; еще одна причина рассматривается в разделе 14.4.

Эта таблица наибольших простых чисел, меньших 2n, для 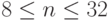 , может использоваться для динамического распределения хеш-таблицы, когда нужно, чтобы размер таблицы был простым числом. Для любого данного положительного значения в охваченном диапазоне эту таблицу можно использовать для определения простого числа, отличающегося от него менее чем в 2 раза.
, может использоваться для динамического распределения хеш-таблицы, когда нужно, чтобы размер таблицы был простым числом. Для любого данного положительного значения в охваченном диапазоне эту таблицу можно использовать для определения простого числа, отличающегося от него менее чем в 2 раза.
Другой вариант обработки целочисленных ключей — объединение мультипликативного и модульного методов: нужно умножить ключ на константу в диапазоне между 0 и 1, а затем выполнить деление по модулю M. Другими словами, необходимо использовать функцию 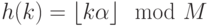 . Между значениями
. Между значениями  , M и эффективным основанием системы счисления ключа существует взаимосвязь, которая теоретически могла бы привести к аномальному поведению, но если использовать произвольное значение a, в реальном приложении вряд ли возникнет какая-либо проблема. Часто в качестве a выбирают значение ф = 0,618033... (золотое сечение).
, M и эффективным основанием системы счисления ключа существует взаимосвязь, которая теоретически могла бы привести к аномальному поведению, но если использовать произвольное значение a, в реальном приложении вряд ли возникнет какая-либо проблема. Часто в качестве a выбирают значение ф = 0,618033... (золотое сечение).
Изучено множество других вариаций на эту тему, в частности, хеш-функции, которые могут быть реализованы с помощью таких эффективных машинных инструкций, как сдвиг и выделение по маске (см. раздел ссылок).
Во многих приложениях, в которых используются таблицы символов, ключи не являются числами и не обязательно являются короткими; чаще это алфавитно-цифровые строки, которые могут быть весьма длинными. Ну и как вычислить хеш-функцию для такого слова, как averylongkey?
В 7-разрядном ASCII-коде этому слову соответствует 84-разрядное число \begin{align*} 97 \cdot 128^{11} &+ 118 \cdot 128^{10} + 101 \cdot 128^{9} + 114 \cdot 128^{8} + 121 \cdot 128^{7}\\ &+ 108 \cdot 128^{6} + 111 \cdot 128^{5} + 110 \cdot 128^{4} + 103 \cdot 128^{3}\\ &+ 107 \cdot 128^{2} + 101 \cdot 128^{1} + 121 \cdot 128^{0}, \end{align*},
которое слишком велико, чтобы с ним можно было выполнять обычные арифметические функции в большинстве компьютеров. А зачастую требуется обрабатывать и гораздо более длинные ключи.
Чтобы вычислить модульную хеш-функцию для длинных ключей, они преобразуются фрагмент за фрагментом. Можно воспользоваться арифметическими свойствами функции модуля и использовать алгоритм Горнера (см. раздел 4.9 "Абстрактные типы данных" ). Этот метод основан на еще одном способе записи чисел, соответствующих ключам. Для рассматриваемого примера запишем следующее выражение: \begin{align*} ((((((((((97 \cdot 128^{11} &+ 118) \cdot 128^{10} + 101) \cdot 128^{9} + 114) \cdot 128^{8} + 121) \cdot 128^{7}\\ &+ 108) \cdot 128^{6} + 111) \cdot 128^{5} + 110) \cdot 128^{4} + 103) \cdot 128^{3}\\ &+ 107) \cdot 128^{2} + 101) \cdot 128^{1} + 121. \end{align*}
То есть десятичное число, соответствующее символьной кодировке строки, можно вычислить при просмотре ее слева направо, умножая накопленное значение на 128, а затем добавляя кодовое значение следующего символа. В случае длинной строки этот способ вычисления в конце концов приведет к числу, большему того, которое вообще можно представить в компьютере. Однако это число и не нужно, поскольку требуется только (небольшой) остаток от его деления на M. Результат можно получить, даже не сохраняя большое накопленное значение, т.к. в любой момент вычисления можно отбросить число, кратное M — при каждом выполнении умножения и сложения нужно хранить только остаток от деления по модулю M. Результат будет таким же, как если бы у нас имелась возможность вычислить длинное число, а затем выполнять деление (см. упражнение 14.10). Это наблюдение ведет к непосредственному арифметическому способу вычисления модульных хеш-функций для длинных строк — см. программу 14.1. В этой программе используется еще одно, последнее ухищрение: вместо основания 128 в ней используется простое число 127. Причина этого изменения рассматривается в следующем абзаце.
Существует множество способов вычисления хеш-функций приблизительно с теми же затратами, что и для модульного хеширования с использованием метода Горнера (одна-две арифметические операции для каждого символа в ключе). Для случайных ключей эти методы практически не отличаются друг от друга, но реальные ключи редко бывают случайными. Возможность ценой небольших затрат придать реальным ключам случайный вид приводит к рассмотрению рандомизированных алгоритмов хеширования, поскольку нам требуются хеш-функции, которые создают случайные индексы таблицы независимо от распределения ключей. Рандомизацию организовать нетрудно, поскольку вовсе не требуется буквально придерживаться определения модульного хеширования — нужно всего лишь, чтобы в вычислении целого числа, меньшего M, использовались все разряды ключа.
Программа 14.1. Хеш-функция для строковых ключей
Данная реализация хеш-функции для строковых ключей использует одно умножение и одно сложение для каждого символа в ключе. Если константу 127 заменить на 128, программа просто вычисляла бы методом Горнера остаток от деления числа, соответствующего 7-разрядному ASCII-представлению ключа, на размер таблицы. Простое основание, равное 127, помогает избежать аномалий, которые возникают, если размер таблицы является степенью 2 или кратным 2.
int hash(char *v, int M)
{ int h = 0, a = 127;
for (; *v != 0; v++)
h = (a*h + *v) % M;
return h;
}
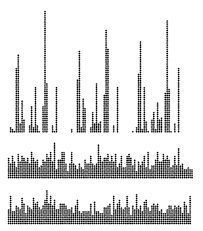
На этих диаграммах показано распределение для набора английских слов (первые 1000 различных слов романа Мел-вилла " Моби Дик " ) при использовании программы 14.1 с
M = 96 и a = 128 (вверху),
M = 97 и a = 128 (в центре) и
M = 96 и a = 127 (внизу)
Неравномерное распределение в первом случае является результатом неравномерного употребления букв и сохранения неравномерности из-за того, что и размер таблицы, и множитель кратны 32. Два других примера выглядят случайными, поскольку размер таблицы и множитель являются взаимно простыми числами.
В программе 14.1 показан один из способов сделать это: использование простого основания вместо степени 2 и целого числа, соответствующего ASCII-представлению строки. На рис. 14.5 рис. 14.5 показано, как это изменение улучшает распределение для типичных строковых ключей. Теоретически хеш-значения, созданные программой 14.1, могут давать плохие результаты для размеров таблицы, которые кратны 127 (хотя на практике это, скорее всего, будет почти незаметно); для создания рандомизированного алгоритма можно было бы выбрать значение множителя наугад. Еще более эффективный подход — использование случайных значений коэффициентов в вычислении и различных случайных значений для каждой цифры ключа. Такой подход дает рандомизированный алгоритм, называемый универсальным хешированием (universal hashing).
Теоретически идеальная универсальная хеш-функция — это функция, для которой вероятность коллизии между двумя различными ключами в таблице размером M в точности равна 1/M. Можно доказать, что использование в качестве коэффициента а в программе 14.1 не фиксированного произвольного значения, а последовательности случайных различных значений преобразует модульное хеширование в универсальную хеш-функцию. Однако затраты на генерирование нового случайного числа для каждого символа в ключе обычно неприемлемы. На практике можно достичь компромисса, показанного в программе 14.1, не храня массив различных случайных чисел для каждого символа ключа, а варьируя коэффициенты с помощью генерации простой псевдослучайной последовательности.
Подведем итоги: чтобы для реализации абстрактной таблицы символов использовать хеширование, сначала необходимо расширить интерфейс абстрактного типа, включив в него операцию hash, которая отображает ключи на неотрицательные целые числа, меньшие размера таблицы M.
Непосредственная реализация
inline int hash(Key v, int M)
{ return (int) M*(v-s)/(t-s); }
выполняет эту задачу для ключей с плавающей точкой со значениями между s и t; для целочисленных ключей можно просто вернуть значение v % M. Если M не является простым числом, хеш-функция может возвращать
(int) (.616161 * (float) v) % M
или результат аналогичного целочисленного выражения, вроде
(16161 * (unsigned) v) % M
Все эти функции, включая программу 14.1 для работы со строковыми ключами, проверены временем; они равномерно распределяют ключи и служат программистам в течение многих лет. Универсальный метод, представленный в программе 14.2 — заметное усовершенствование для строковых ключей, которое обеспечивает случайные хеш-значения при небольших дополнительных затратах; аналогичные рандомизированные методы можно применять и к целочисленным ключам (см. упражнение 14.1).