Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2197 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 3:
Элементарные структуры данных
Ключевые слова: операции, структура данных, Data, управление памятью, хранение данных, механизмы, compound, structure, дерево, tree
Организация обрабатываемых данных является важным этапом разработки программ. Для реализации многих приложений правильный выбор структуры данных - единственное важное решение: когда выбор сделан, разработка алгоритмов не вызывает затруднений. Для одних и тех же данных различные структуры занимают различный объем памяти. Одни и те же операции с различными структурами данных приводят к алгоритмам различной эффективности. Выбор алгоритмов и структур данных тесно взаимосвязан, и программисты постоянно изыскивают способы повышения быстродействия или экономии памяти за счет оптимального выбора.
Структура данных не является пассивным объектом: необходимо принимать во внимание выполняемые с ней операции (и алгоритмы, используемые для этих операций). Эта концепция формально выражена в понятии типа данных (data type). В данной главе основное внимание уделяется конкретным реализациям базовых принципов, используемых для организации данных. Будут рассмотрены основные методы организации данных и управления ими, изучен ряд примеров, демонстрирующих преимущества каждого подхода, и сопутствующие вопросы, такие как управление памятью. В "Абстрактные типы данных" будут введены абстрактные типы данных, в которых описание типов данных отделено от их реализации.
Мы рассмотрим свойства массивов, связных списков и строк. Эти классические структуры данных имеют широкое применение: вместе с деревьями (см. "Рекурсия и деревья" ) они составляют основу почти всех алгоритмов, рассматриваемых в данной книге. Мы изучим различные примитивные операции для управления структурами данных и получим базовый набор средств, которые позволят разрабатывать сложные алгоритмы для более трудных задач.
Хранение данных в виде объектов переменных размеров, а также в связных структурах, требует знания, как система управляет памятью, которую она выделяет программам для данных. Эта тема рассматривается не во всех подробностях, поскольку много важных моментов зависит от системы и аппаратных средств. Но мы все же ознакомимся с принципами управления памятью и несколькими базовыми механизмами решения этой задачи. Кроме того, будут рассмотрены конкретные методы, в которых используются механизмы выделения памяти для программ на C++.
В конце главы приводятся несколько примеров составных структур (compound structure), таких как массивы связных списков и массивы массивов. Построение абстрактных механизмов все большей сложности из более простых постоянно встречается в данной книге. Мы рассмотрим ряд примеров, которые в дальнейшем послужат основой для более совершенных алгоритмов.
Изучаемые в этой главе структуры данных - важные строительные блоки, которые можно использовать естественным образом как в C++, так и во многих других языках программирования. В "Рекурсия и деревья" будет рассмотрена еще одна важная структура данных - дерево (tree). Массивы, строки, связные списки и деревья служат базовыми элементами большинства алгоритмов, о которых идет речь в книге. В "Абстрактные типы данных" рассматривается использование конкретных представлений, разработанных на основе абстрактных типов данных. Эти представления могут применяться в различных приложениях. Остальная часть книги посвящена различным модификациям базовых средств, деревьев и абстрактных типов данных для создания алгоритмов, решающих более сложные задачи. Они также могут служить основой для высокоуровневых абстрактных типов данных в различных приложениях.
Строительные блоки
В этом разделе рассматриваются базовые низкоуровневые конструкции, используемые для хранения и обработки информации в языке C++. Все обрабатываемые компьютером данные в конечном счете состоят из отдельных битов. Однако написание программ, обрабатывающих только биты - слишком трудоемкое занятие. Типы позволяют указывать, как будут использоваться определенные наборы битов, а функции позволяют задавать операции, выполняемые над данными. Структуры C++ используются для группирования разнородных частей информации, а указатели (pointer) служат для косвенных ссылок на информацию. В этом разделе будут рассмотрены базовые механизмы языка C++ - чтобы уяснить общий принцип организации программ. Наша главная цель - заложить основу для разработки структур высших уровней ( "Абстрактные типы данных" и "Рекурсия и деревья" ), на базе которых будет построено большинство алгоритмов, рассматриваемых в данной книге.
Программы обрабатывают информацию, которая происходит из математических или естественных языковых описаний окружающего мира. Поэтому вычислительные среды обеспечивают встроенную поддержку основных строительных блоков подобных описаний - чисел и символов. В C++ программы используют совсем немного базовых типов данных:
- Целые числа (int).
- Числа с плавающей точкой (float).
- Символы (char).
На эти типы часто ссылаются по их именам в языке C++ (int, float и char), хотя часто используются обобщенные термины - целое (integer), число с плавающей точкой и символ (character). Символы чаще всего используются в абстракциях более высокого уровня - например, для создания слов и предложений. Поэтому обзор символьных данных будет отложен до раздела 3.6, а пока обратимся к числам.
Для представления чисел используется фиксированное количество битов. Таким образом, тип int относится к целым числам некоего диапазона, который зависит от количества битов, используемых для их представления. Числа с плавающей точкой содержат приблизительные значения действительных чисел, а используемое для их представления количество битов определяет точность этого приближения. В C++ мы выбираем либо большую точность, либо экономию памяти. Для целых имеются типы int, long int и short int, а для чисел с плавающей точкой - float и double. В большинстве систем эти типы соответствуют готовым аппаратным представлениям. Количество битов, используемое для представления чисел, а, следовательно, и диапазон значений (для целых) или точность (для чисел с плавающей точкой), зависит от компьютера (см. упражнение 3.1), хотя язык C++ предоставляет определенные гарантии. Ради простоты в этой книге обычно используются типы int и float - за исключением случаев, когда необходимо подчеркнуть, что задача требует применения больших чисел.
В современном программировании при выборе типов данных больше ориентируются на потребности программы, чем на возможности компьютера, прежде всего из соображений переносимости приложений. Например, тип short int рассматривается как объект, который может принимать значения от -32767 до 32767, а не 16-битовый объект. Кроме того, в концепцию целых чисел входят и операции, которые могут с ними выполняться: сложение, умножение и т.д.
Определение 3.1. Тип данных - это множество значений и набор операций над ними.
Операции связаны с типами, а не наоборот. При выполнении операции необходимо обеспечить, чтобы ее операнды и результат были нужного типа. Пренебрежение этим правилом - распространенная ошибка программирования. В некоторых случаях C++ выполняет неявное преобразование типов; в других используется приведение (cast), т.е. явное преобразование типов. Например, если x и N целые числа, выражение
((float) x) / N
включает оба типа преобразований: оператор (float) выполняет приведение - величина x преобразуется в значение с плавающей точкой. Затем, в соответствии с правилами C++, выполняется неявное преобразование N, чтобы оба аргумента операции деления были значениями с плавающей точкой.
Многие операции, связанные со стандартными типами данных (такие как арифметические), встроены в язык C++. Другие операции существуют в виде функций, которые определены в стандартных библиотеках функций. Остальные операции реализуются в функциях C++, которые определены в программах (см. программу 3.1). Таким образом, концепция типа данных связана не только со встроенными типами (целые, значения с плавающей точкой и символы). Разработчики часто определяют собственные типы данных, что служит эффективным средством организации программных средств. При определении простой функции C++, по сути, создается новый тип данных. Реализуемая функцией операция добавляется к операциям, определенным для типов данных, которые представлены аргументами функции. В некотором смысле, каждая программа C++ является типом данных - списком множеств значений (встроенных или других типов) и связанных с ними операций (функций). Возможно, эта концепция слишком обобщена, чтобы быть полезной, но мы еще убедимся в ценности рассмотрения программ как типов данных.
При написании программ одна из задач заключается в такой их организации, чтобы они были применимы к как можно большему количеству ситуаций. Тогда старую программу можно применить для решения новых задач, которые иногда совершенно не связаны с первоначальной. Во-первых, осмысление и точное определение используемых программой операций позволяет легко распространить ее на любой тип данных, для которого эти операции могут поддерживаться. Во-вторых, после точного определения действий программы можно добавить выполняемую ей абстрактную операцию к операциям, которые имеются в нашем распоряжении для решения новых задач.
Программа 3.1. Определение функций
Для реализации новых операций с данными в C++ используется механизм определения функций (function definition).
Все функции имеют список аргументов и, возможно, возвращаемое значение (return value). Приведенная функция lg имеет один аргумент и возвращаемое значение, оба типа int. Функция main не принимает аргументов и возвращает значение типа int (по умолчанию - значение 0, которое означает успешное завершение).
Функция объявляется (declare) путем присвоения ей имени и типа возвращаемого значения. Первая строка программы ссылается на библиотечный файл, который содержит объявления cout, << и endl. Во второй строке объявляется функция lg. Если функция определена до ее использования (см. следующий абзац), объявление необязательно. Объявление предоставляет информацию, необходимую другим функциям для вызова данной с использованием аргументов допустимого типа. Вызывающая функция может использовать данную функцию в выражении - наподобие переменных, имеющих тот же тип, что и возвращаемое значение.
Функции определяются (define) посредством кода C++. Все программы на C++ содержат описание функции main, а в данном примере также имеется описание функции lg. Определение функции содержит имена аргументов (называемых параметрами) и описание вычислений с этими именами, как если бы они были локальными переменными. При вызове функции эти переменные инициализируются, принимая значения передаваемых аргументов, после чего выполняется код функции. Оператор return служит для завершения выполнения функции и передачи возвращаемого значения вызывающей функции. Обычно вызывающая функция не испытывает других воздействий, хотя нам встретится много исключений из этого правила.
Разграничение определений и объявлений создает гибкость в организации программ. Например, они могут содержаться в разных файлах (см. текст). Кроме того, в простой программе, подобной приведенной здесь, определение функции lg можно поместить перед определением main и опустить объявление.
#include <iostream.h>
int lg(int);
int main() {
for (int N = 1000; N <= 1000000000; N *= 10)
cout << lg(N) << " " << N << endl;
}
int lg(int N) {
for (int i = 0; N > 0; i++, N /= 2) ;
return i;
}
В программе 3.2 реализованы несложные вычисления с использованием простых типов данных, определенных с помощью операции typedef и функции (которая сама реализована с помощью библиотечной функции). Главная функция ссылается на определяемый тип данных, а не встроенный числовой тип. Не указывая тип чисел, обрабатываемых программой, мы расширяем ее потенциальную область применения. Подобный подход может продлить время жизни программы. Если из-за появления нового приложения, компилятора или компьютера нам придется использовать новый тип чисел, в программе будет достаточно просто изменить тип данных.
Программа 3.2. Типы чисел
Эта программа вычисляет среднее значение ц и среднеквадратичное отклонение ст последовательности целых чисел
x1 x2, ..., xN
, сгенерированных библиотечной процедурой rand. Ниже приводятся математические формулы:
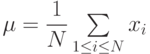
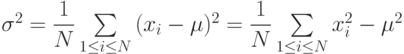
Обратите внимание, что прямая реализация формулы определения 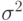 требует одного прохода для вычисления среднего и еще одного прохода для вычисления суммы квадратов разностей членов последовательности и среднего значения. Однако преобразование формулы позволяет вычислить за один проход.
требует одного прохода для вычисления среднего и еще одного прохода для вычисления суммы квадратов разностей членов последовательности и среднего значения. Однако преобразование формулы позволяет вычислить за один проход.
Объявление typedef используется для локализации указания, что данные имеют тип int. Например, typedef и описание функции randNum могут содержаться в отдельном файле (указываемом директивой include). Впоследствии можно будет использовать программу для тестирования случайных чисел другого типа, изменив этот файл (см. текст).
Независимо от типа данных программа использует тип int для индексов и тип float для вычисления среднего значения и среднеквадратичного отклонения. Она сможет работать только если заданы преобразования данных в тип float.
#include <iostream.h>
#include <stdlib.h>
#include <math.h>
typedef int Number;
Number randNum() {
return rand();
}
int main(int argc, char *argv[]) {
int N = atoi(argv[1]);
float ml = 0.0, m2 = 0.0;
for (int i = 0; i < N; i++) {
Number x = randNum();
ml += ((float) x)/N;
m2 += ((float) x*x)/N;
}
cout << " Среднее: " << ml << endl;
cout << "Ср.-кв.откл.: " << sqrt(m2-m1*m1) << endl;
}
Этот пример не является полным решением задачи вычисления средних величин и среднеквадратичных отклонений в программе, не зависящей от типа данных; подобная цель и не ставилась. Например, программа требует преобразования чисел типа Number в тип float, чтобы они могли участвовать в вычислении среднего значения и отклонения. В данном виде программа зависима от приведения к типу float, предусмотренного для встроенного типа int. Вообще говоря, можно явно описать такое приведение для любого типа Number.
При попытке выполнения каких-либо действий, помимо арифметических, вскоре возникнет необходимость добавления к типу данных новых операций. Например, может потребоваться вывод чисел на экран или принтер. При любой попытке разработать тип данных на основе знания об операциях, необходимых для программы, необходимо отыскать компромисс между уровнем обобщения и простотой реализации и использования.
Имеет смысл подумать, как изменять тип данных таким образом, чтобы программа 3.2 работала и с другими типами чисел, скажем, float вместо int. В языке C+ + предусмотрен ряд механизмов, позволяющих воспользоваться тем, что определение типа данных локализовано. Для такой небольшой программы проще всего сделать копию файла, затем изменить объявление typedef на typedef float Number, а тело процедуры randNum на return 1.0*rand()/RAND_MAX; (при этом будут возвращаться случайные числа с плавающей точкой в диапазоне от 0 до 1). Однако даже для такой простой программы этот подход неудобен: теперь у нас две копии программы, и все последующие изменения придется проводить в обеих копиях. В C++ возможно другое решение - поместить описания typedef и randNum в отдельный заголовочный файл (header file) с именем, например, Number.h и заменить их в коде программы 3.2 директивой
#include "Number.h"
Затем можно создать второй заголовочный файл с другими описаниями typedef и randNum и использовать главную программу 3.2 без всяких изменений, меняя лишь имя нужного файла на Number.h.