Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2202 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 15:
Поразрядный поиск
Ключевые слова: radix, Search, поиск, ключ, основание, операции, производительность, память, доступ, обобщение
Некоторые методы поиска не сравнивают на каждом шаге полные значения ключей поиска, а просматривают ключи небольшими фрагментами. Эти методы носят название поразрядного поиска (radix search) и работают совершенно аналогично методам поразрядной сортировки, рассмотренным в "Поразрядная сортировка" . Они удобны, когда ключи поиска легко разбиваются на фрагменты, и могут обеспечить эффективные решения для многих реальных задач, применяющих поиск.
В поразрядном поиске применяется та же абстрактная модель, которая использовалась в "Поразрядная сортировка" : в зависимости от контекста ключ может быть словом (последовательностью байтов фиксированной длины) или строкой (последовательностью байтов переменной длины). Ключи, являющиеся словами, рассматриваются как числа, представленные в системе счисления с основанием R при различных значениях R (основание системы счисления), и обрабатываются отдельные цифры этих чисел. Строки можно рассматривать как числа переменной длины, ограничиваемые специальным символом, чтобы для ключей как фиксированной, так и переменной длины можно было создавать алгоритмы, основываясь на абстрактной операции " извлечь i-ю цифру ключа " вместе с соглашением об обработке ситуации, когда ключ содержит менее i цифр.
Принципиальное преимущество методов поразрядного поиска заключается в следующем: они обеспечивают приемлемую производительность для худшего случая без сложностей, присущих сбалансированным деревьям; они обеспечивают простой способ обработки ключей переменной длины; некоторые из них позволяют экономить память, сохраняя часть ключа внутри поисковой структуры; и они, наряду с деревьями бинарного поиска и хешированием, могут обеспечить быстрый доступ к данным. Недостатки этих методов связаны с тем, что некоторые из них могут неэффективно использовать память, и, как при поразрядной сортировке, их производительность может снижаться, если нет эффективного доступа к байтам ключей.
Вначале мы изучим несколько методов поиска, которые рассматривают ключи поиска побитно, используя биты для перемещения по структурам бинарных деревьев. Мы ознакомимся с рядом методов, каждый из которых устраняет проблемы, характерные для предыдущего, а в завершение рассмотрим остроумный метод, пригодный для многих приложений поиска.
Затем мы исследуем обобщение R-путевых деревьев. Как и в предыдущем случае, мы рассмотрим ряд методов, завершающийся гибким и эффективным методом, который может поддерживать базовую реализацию таблицы символов и множество ее расширений.
Обычно при поразрядном поиске вначале рассматриваются старшие цифры ключей. Многие методы непосредственно соответствуют MSD-методам поразрядной сортировки — так же, как BST-поиск соответствует быстрой сортировке. В частности, мы рассмотрим аналоги методов сортировки с линейным временем выполнения из "Поразрядная сортировка" — линейные по времени методы поиска, основанные на том же принципе.
В конце главы будет рассмотрено специфическое применение структур поразрядного поиска — для обработки строк, в том числе и для построения индексов для длинных текстовых строк. Рассмотренные в этой главе методы обеспечивают естественные решения для этого приложения и помогают заложить основу для решения более сложных задач обработки строк, приведенных в части 5.
Деревья цифрового поиска
Простейший метод поразрядного поиска основан на использовании деревьев цифрового поиска (digital search trees — DST), которые мы в дальнейшем будем называть DST-деревьями. Алгоритмы операций найти и вставить аналогичны поиску и вставке в бинарном дереве, за исключением одного различия: ветвление в дереве выполняется не по результату сравнения полных ключей, а в соответствии с выбранными битами ключа. На первом уровне используется ведущий бит; на втором уровне используется бит, следующий за ведущим и т.д., пока не встретится внешний узел. Программа 15.1 является реализацией операции найти; аналогично можно реализовать и операцию вставить. Вместо использования операции < для сравнения ключей мы будем считать, что доступна функция digit, обеспечивающая доступ к отдельным битам ключей. Этот код практически совпадает с кодом поиска в бинарном дереве (см. программу 12.8), но, как будет показано, имеет существенно иные характеристики производительности.
В "Поразрядная сортировка" было показано, что при использовании поразрядной сортировки особое внимание следует уделять совпадающим ключам; то же самое справедливо и по отношению к поразрядному поиску. В этой главе предполагается, что все значения ключей в таблице символов различны. Это предположение не ведет к потере общности, поскольку для поддержки приложений, содержащих записи с повторяющимися ключами, можно воспользоваться одним из методов, рассмотренных в "Таблицы символов и деревья бинарного поиска" . При освоении поразрядного поиска важно сосредоточиться на различных значениях ключей, поскольку значения ключей являются важными компонентами нескольких структур данных, которые мы рассмотрим в дальнейшем.
Программа 15.1. Бинарное DST-дерево
Для разработки реализации таблицы символов с использованием DST-деревьев мы изменили в стандартной реализации BST-дерева реализации операций найти и вставить (см. программу 12.8) — здесь приведен пример операции найти. Для принятия решения о том, следует ли переходить влево или вправо, вместо сравнения полных ключей выполняется проверка единственного (ведущего) бита ключа. В рекурсивных вызовах функции содержится третий параметр, позволяющий смещать вправо позицию проверяемого бита при спуске вниз по дереву. Для проверки битов используется функция digit, описанная в "Поразрядная сортировка" . Эти же изменения проведены и в реализации операции вставить; в остальном используется код из программы 12.8.
private:
Item searchR(link h, Key v, int d)
{ if (h == 0) return nullItem;
if (v == h->item.key()) return h->item;
if (digit(v, d) == 0)
return searchR(h->l, v, d+1);
else
return searchR(h->r, v, d+1);
}
public:
Item search(Key v)
{ return searchR(head, v, 0); }
На рис. 15.1 приведены двоичные представления однобуквенных ключей, используемых в остальных рисунках этой главы. На рис. 15.2 показан пример вставки в DST-дерево, а на рис. 15.3 — процесс вставки ключей в первоначально пустое дерево.
Разряды ключей управляют поиском и вставкой, но обратите внимание, что DST-деревья не обладают свойством упорядоченности, характерным для BST-деревьев. То есть ключи в узлах слева от данного не обязательно меньше, а ключи в узлах справа от данного не обязательно больше ключей данного узла, как это было бы в BST-дереве с различными ключами. Ключи слева от данного узла действительно меньше ключей справа от него — если узел находится на уровне к, все они совпадают в первых к разрядах, а следующий разряд равен 0 для ключей слева и 1 для ключей справа — но сам ключ узла может быть наименьшим, наибольшим или любым в диапазоне всех ключей из поддерева этого узла.
DST-деревья характеризуются тем, что каждый ключ находится где-то на пути, определяемом разрядами ключа (слева направо). Этого свойства достаточно для правильной работы реализаций операций найти и вставить в программе 15.1.

Как и в "Поразрядная сортировка" , в небольших примерах, приведенных на рисунках этой главы, для представления i-ой буквы алфавита используется 5-разрядное двоичное представление числа i, что и продемонстрировано здесь на примере нескольких ключей. Биты нумеруются слева направо от 0 до 4.
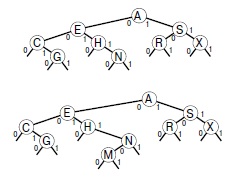
В этом DST-дереве (вверху) при неудачном поиске ключа M = 01101 мы переходим из корня влево (поскольку первый бит в двоичном представлении ключа равен 0), потом вправо (поскольку второй бит равен 1), затем вправо, влево и завершаем поиск на пустой ссылке под ключом N. Для вставки ключа M (внизу) мы заменяем пустую ссылку в месте завершения поиска ссылкой на новый узел, как это делается при вставке в BST-дерево.
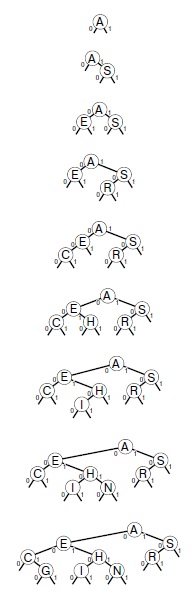
На этой последовательности рисунков показан результат вставки ключей A S E R C H I N G в первоначально пустое DST-дерево.
Предположим, что ключи являются словами фиксированной длины, состоящими из w битов. Из требования различия ключей следует, что  , и обычно предполагается, что N значительно меньше
, и обычно предполагается, что N значительно меньше 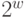 ; в противном случае лучше было бы использовать распределяющий поиск (см.
"Таблицы символов и деревья бинарного поиска"
). Этому условию удовлетворяет множество реальных задач. Например, использование DST-деревьев вполне подходит для таблицы символов, содержащей вплоть до 10 записей с 32-разрядными ключами (но, скорее всего, не 106 записей), или любое количество записей с 64-разрядными ключами. DST-деревья работают также и с ключами переменной длины; но мы отложим подробное рассмотрение этого случая до раздела 15.2, где будет рассмотрен и ряд других вариантов.
; в противном случае лучше было бы использовать распределяющий поиск (см.
"Таблицы символов и деревья бинарного поиска"
). Этому условию удовлетворяет множество реальных задач. Например, использование DST-деревьев вполне подходит для таблицы символов, содержащей вплоть до 10 записей с 32-разрядными ключами (но, скорее всего, не 106 записей), или любое количество записей с 64-разрядными ключами. DST-деревья работают также и с ключами переменной длины; но мы отложим подробное рассмотрение этого случая до раздела 15.2, где будет рассмотрен и ряд других вариантов.
Производительность в худшем случае для деревьев, построенных с помощью поразрядного поиска, значительно выше производительности в худшем случае для BST-деревьев — если количество ключей велико, а длина ключей мала по сравнению с их количеством. Во многих приложениях длина самого длинного пути в DST-дереве чаще всего оказывается сравнительно небольшой (например, если ключи образованы случайными значениями разрядов). В частности, самый длинный путь наверняка ограничен длиной самого длинного ключа; а если ключи имеют фиксированную длину, то время поиска ограничено этой длиной. Сказанное иллюстрируется на рис. 15.4.
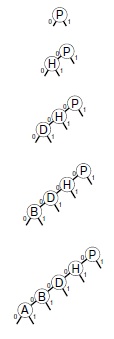
На этой последовательности рисунков показаны результаты вставки ключей P = 10000, H = 01000, D = 00100, B = 00010 и A = 00001 впер-воначально пустое DST-дерево. Последовательность деревьев кажется вырожденной, но длина пути ограничена длиной двоичного представления ключей. Ни один 5-разрядный ключ, за исключением 00000, не приведет к дальнейшему увеличению высоты дерева.
Лемма 15.1. Для выполнения поиска или вставки в DST-дереве, построенном из N случайных ключей, требуется околоlgN сравнений в среднем и около 2 lgN сравнений в худшем случае. Количество сравнений никогда не превышает количество разрядов в ключе поиска.
Вышеуказанные результаты в среднем и в худшем случае можно доказать для случайных ключей при помощи рассуждений, аналогичных приведенным, для более естественной задачи в следующем разделе, поэтому это доказательство вынесено туда в упражнение (см. упражнение 15.30). Доказательство основывается на интуитивном ожидании, что непросмотренная часть случайного ключа с равной вероятностью может начинаться с 0 или 1, поэтому с обеих сторон любого ключа их должно быть поровну. При каждом перемещении вниз по дереву используется один бит ключа, поэтому ни один поиск в DST-дереве не может потребовать больше сравнений, чем разрядов в ключе поиска. Для типичного случая, когда используются w-разрядные слова и количество ключей N значительно меньше общего возможного количества ключей 2w, длины путей близки кlgN. Поэтому для случайных ключей количество сравнений значительно меньше количества разрядов в ключах. 
На рис. 15.5 показано большое DST-дерево, образованное случайными 7-разрядными ключами. Это дерево почти идеально сбалансировано. Использование DST-деревьев удобно во многих реальных приложениях, поскольку эти деревья обеспечивают практически оптимальную производительность даже для очень больших задач, требуя лишь минимальных усилий на реализацию. Например, DST-дерево, построенное из 32-разрядных ключей (или четырех 8-битовых символов), гарантировано требует менее 32 сравнений, а DST-дерево, построенное из 64-разрядных ключей (или восьми 8-битовых символов), гарантировано требует менее 64 сравнений, даже при наличии миллиардов ключей. Для больших N эти гарантии сравнимы с теми, которые обеспечивают RB-деревья, но для их реализации требуется лишь примерно столько же усилий, как и для реализации стандартных BST-деревьев (которые могут гарантировать только производительность, пропорциональную N2). Это свойство делает DST-деревья привлекательной альтернативой использованию сбалансированных деревьев для практической реализации операций таблицы символов найти и вставить — при условии наличия эффективного доступа к разрядам ключей.

Это DST-дерево, построенное вставкой около 200 случайных ключей, так же хорошо сбалансировано, как и его аналоги из главы 15.
Упражнения
15.1. Нарисуйте DST-дерево, образованное вставками элементов с ключами E A S Y Q U T I O N в указанном порядке в первоначально пустое дерево при использовании двоичной кодировки, приведенной на рис. 15.1.
15.2. Приведите последовательность вставок ключей A B C D E F G, приводящую к образованию полностью сбалансированного DST-дерева, одновременно являющегося допустимым BST-деревом.
15.3. Приведите последовательность вставки ключей A B C D E F G, приводящую к образованию полностью сбалансированного DST-дерева, в котором каждый узел имеет ключ, меньший ключей всех узлов в его поддереве.
15.4. Нарисуйте DST-дерево, образованное вставками элементов с ключами 01010011 00000111 00100001 01010001 11101100 00100001 10010101 01001010 в указанном порядке в первоначально пустое дерево.
15.5. Можно ли в DST-деревьях хранить записи с повторяющимися ключами, как в BST-деревьях? Обоснуйте свой ответ.
15.6. Экспериментально сравните высоту и длину внутреннего пути DST-дерева, построенного вставками N случайных 32-разрядных ключей в первоначально пустое дерево, с этими же характеристиками стандартного BST-дерева и RB-дерева (см. "Сбалансированные деревья" ), построенных из этих же ключей, при N = 103, 104, 105 и 106 .
15.7. Приведите полную характеристику длины внутреннего пути для худшего случая DST-дерева, содержащего N различных w-разрядных ключей.
15.8. Реализуйте операцию удалить для таблицы символов на основе DST-дерева.
15.9. Реализуйте операцию выбрать для таблицы символов на основе DST-дерева.
15.10. Опишите, как можно за линейное время вычислить высоту DST-дерева, образованного заданным набором ключей, не прибегая к построению DST-дерева.