|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2195 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 15:
Поразрядный поиск
Алгоритмы индексирования текстовых строк
В "Таблицы символов и деревья бинарного поиска" был рассмотрен процесс построения индекса строк, где для определения, присутствует ли в длинном тексте заданная ключевая строка, использовалось BST-дерево с указателями на подстроки. В этом разделе мы рассмотрим более сложные реализации этого АТД, использующие многопутевые trie-деревья, но отправная точка остается той же. Каждая позиция в тексте считается началом строкового ключа, который простирается до конца текста. Из этих ключей строится таблица символов, содержащая указатели на строки. Все ключи различны (хотя бы потому, что все они имеют различную длину), и почти все они очень велики. Цель поиска состоит в определении, является ли заданный искомый ключ префиксом одного из ключей в индексном указателе, что эквивалентно определению того, присутствует ли искомый ключ где-либо в текстовой строке.
Дерево поиска, которое построено из ключей, определенных индексами символов текстовой строки, называется деревом суффиксов (suffix tree). Для его построения можно воспользоваться любым алгоритмом, допускающим ключи переменной длины. Особенно подходят методы, основанные на применении trie-деревьев (за исключением методов, формирующих однонаправленные пути из окончаний ключей), поскольку их время выполнения зависит не от длины ключей, а только от количества цифр, необходимых для различения. Такое поведение прямо противоположно, например, алгоритмам хеширования, которые нельзя непосредственно применить для решения этой задачи, т.к. их время выполнения пропорционально длине ключей.
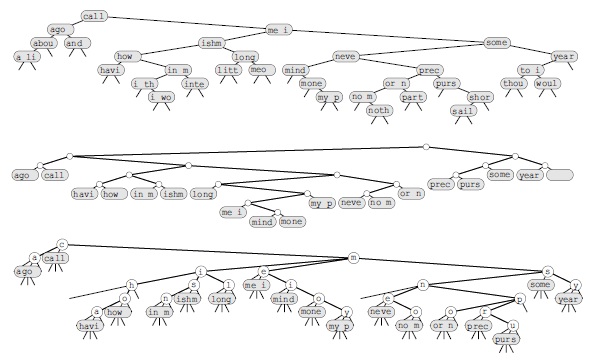
На рис. 15.20 приведены примеры строковых индексов, построенных с использованием BST-деревьев, patricia-деревьев и TST-деревьев (с листьями). В этих индексах используются только ключи, которые начинаются на границах слов; индексирование, начинающееся с границ символов, позволило бы построить более сложный индекс, но при этом потребовало бы гораздо больше памяти.
Строго говоря, даже текст, состоящий из случайной строки, не приводит к случайному набору ключей в соответствующем индексе (поскольку ключи не являются независимыми). Однако в реальных приложениях, использующих индексирование, редко приходится иметь дело со случайными текстами, и это теоретическое несоответствие не помешает нам пользоваться преимуществом быстрых реализаций индексирования, возможных благодаря поразрядным методам. Мы не будем подробно рассматривать характеристики производительности при использовании каждого из этих алгоритмов для построения строкового индекса, т.к. многие компромиссы, связанные с общими таблицами символов со строковыми ключами, проявляются и при решении задачи индексирования строк.
Здесь показаны индексы текстовых строк, построенные из текста call me ishmael some years ago never mind how long precisely... с использованием BST-дерева (вверху), patricia-дерева (в центре) и TST-дерева (внизу). Узлы, содержащие указатели на строки, отмечены первыми четырьмя символами указываемых строк.
Для обычного текста в первую очередь, вероятно, стоит рассмотреть реализации на основе стандартных BST-деревьев, поскольку их легко реализовать (см. упражнение 12.10). Для типичных приложений это решение должно обеспечить хорошую производительность. Один из побочных эффектов взаимной зависимости ключей — особенно при построении строкового индекса для каждой символьной позиции — то, что худший случай BST-деревьев не будет особой проблемой в очень больших текстах, поскольку несбалансированные BST-деревья возникают только в крайне причудливых случаях.
Patricia-деревья изначально разрабатывались для приложений строкового индексирования. Для использования программ 15.5 и 15.4 потребуется лишь обеспечить реализацию функции bit, чтобы при заданном указателе на строку и целочисленном значении i она возвращала i-й бит строки (см. упражнение 15.82). На практике высота patricia-дерева, реализующего индекс текстовой строки, будет логарифмической. Кроме того, patricia-дерево обеспечивает быстрые реализации неудачного поиска, т.к. в нем нет необходимости проверять все байты ключа.
TST-деревья обеспечивают некоторые преимущества в производительности, характерные для patricia-деревьев, легко реализуются и используют встроенные операции доступа к байтам, обычно присутствующие в современных компьютерах. Кроме того, они допускают простые реализации, подобные программе 15.9, которые могут решать и задачи, более сложные, чем поиск полного соответствия с искомым ключом. Для построения строкового индекса на основе TST-дерева необходимо удалить код, обрабатывающий конечные части ключей в структуре данных, поскольку ни одна строка гарантированно не является префиксом другой и, следовательно, никогда не придется сравнивать строки вплоть до их конца. При этом нужно изменить определение операции == в интерфейсе типа элемента, чтобы две строки считались равными, если одна из них является префиксом другой, как это было сделано в разделе 12.7 "Таблицы символов и деревья бинарного поиска" , поскольку мы будем сравнивать ключ поиска (короткий) с текстовой строкой (длинной), начиная с некоторой позиции внутри текстовой строки. Третье удобное изменение — хранение в каждом узле не символов, а их индексов в строке, чтобы каждый узел в дереве ссылался на позицию в текстовой строке (позицию, которая следует за первым вхождением строки, определенной символами на ветвях равенства от корня до этого узла). Реализация перечисленных изменений — интересное и поучительное упражнение, ведущее к созданию гибкой и эффективной реализации индекса текстовых строк (см. упражнение 15.81).
Несмотря на все описанные преимущества, важно помнить, что в обычных приложениях, использующих индексирование текста с помощью DST-деревьев, patricia-деревьев или TST-деревьев, сам текст фиксирован, и поэтому нет необходимости использовать динамические операции вставить. То есть, как правило, индекс строится один раз, а затем без каких-либо изменений используется для выполнения очень большого количества поисков. Следовательно, динамические структуры данных типа BST-деревьев, patricia-деревьев или TST-деревьев могут оказаться вообще ненужными: достаточно базового алгоритма бинарного поиска. Индекс представляет собой набор указателей на строки, а формирование индекса эквивалентно сортировке этих указателей. Основное преимущество бинарного поиска по сравнению с динамическими структурами данных заключается в экономии памяти. Для индексирования текстовой строки в N позициях при помощи бинарного поиска требуется лишь N указателей на строки; а для индексирования строки в N позициях с помощью метода, основанного на каком-либо дереве, требуется, по меньшей мере 3N указателей (один указатель на строку и еще две ссылки на поддеревья). Как правило, индексные указатели текста имеют очень большой размер, поэтому бинарный поиск может оказаться более удобным, т.к. он гарантирует логарифмическое время поиска, но при этом использует менее трети памяти, используемой методами на основе деревьев. Но при наличии достаточного объема доступной памяти TST- или trie-деревья позволяют для многих приложений реализовать более быстрые операции найти, т.к., в отличие от бинарного поиска, перемещение по ключам выполняется без возвратов.
Если имеется очень большой текст, но ожидается немного поисков в нем, то построение полного индексного указателя, видимо, будет неоправданным. Задача поиска строк состоит в быстром определении, содержит ли текст заданный искомый ключ (без предварительной обработки текста). Между этими двумя крайними случаями — без предварительной обработки и с построением полного индекса — находится много других задач обработки строк.
Упражнения
15.77. Нарисуйте 26-путевое DST-дерево, образованное в результате индексирования текстовой строки из слов now is the time for all good people to come the aid of their party.
15.78. Нарисуйте 26-путевое trie-дерево, образованное в результате индексирования текстовой строки из слов now is the time for all good people to come the aid of their party.
15.79. Нарисуйте TST-дерево, образованное в результате индексирования текстовой строки из слов now is the time for all good people to come the aid of their party в стиле рис. 15.20.
15.80. Нарисуйте TST-дерево, образованное в результате индексирования текстовой строки из слов now is the time for all good people to come the aid of their party. Используйте описанную в тексте реализацию, в которой TST-дерево содержит в каждом узле указатели на символы строк.
15.81. Измените реализации поиска и вставки в TST-дерево, приведенные в программах 15.11 и 15.12, чтобы обеспечить индексирование строк на основе TST-дерева.
15.82. Реализуйте интерфейс, позволяющий с помощью patricia-деревьев обрабатывать строковые ключи в стиле C (т.е. массивы символов), как если бы они были битовыми строками.
15.83. Нарисуйте patricia-дерево, образованное в результате индексирования текстовой строки из слов now is the time for all good people to come the aid of their party при использовании 5-разрядного двоичного кодирования, когда i-я буква алфавита кодируется двоичным представлением числа i.
15.84. Объясните, почему неэффективна идея улучшения бинарного поиска с помощью того же базового принципа, на котором основаны TST-деревья (сравнение символов, а не строк).
15.85. Найдите в вашей системе большой (не менее 106 байтов) текстовый файл и сравните высоту и длину внутреннего пути стандартного BST-дерева, patricia-дерева и TST-дерева, полученных в результате построения индексного указателя для данного файла.
15.86. Экспериментально сравните высоту и длину внутреннего пути стандартного BST-дерева, patricia-дерева и TST-дерева, полученных в результате построения индексного указателя для текстовой строки, состоящей из N случайных символов 32-символьного алфавита при N = 103, 104, 105 и 106 .
15.87. Напишите эффективную программу для определения самой длинной повторяющейся последовательности в очень длинной текстовой строке.
15.88. Напишите эффективную программу для определения 10-символьной последовательности, чаще всего встречающейся в очень длинной текстовой строке.
15.89. Постройте индекс строки, который поддерживает операцию, возвращающую количество вхождений ее аргумента в индексированном тексте, а также поддерживает, подобно операции сортировать, операцию найти, которая посещает все позиции в тексте, соответствующие искомому ключу.
15.90. Опишите текстовую строку, состоящую из N символов, для которой индексирование, основанное на применении TST-дерева, работает особенно плохо. Оцените затраты на индексирование этой же строки с помощью BST-дерева.
15.91. Пусть нужно проиндексировать случайную N-разрядную строку для позиций разрядов, кратных 16. Экспериментально определите, какие размеры байтов (1, 2, 4, 8 или 16) ведут к наименьшему времени индексирования с помощью TST-дерева, при N = 103, 104, 105 и 106 .
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |