|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2187 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 3:
Элементарные структуры данных
Третий вариант рекомендован и широко распространен в программировании на C, C++ и других языках. Он предусматривает разбиение программы на три файла:
- Интерфейс, где определяется структура данных и объявляются функции, используемые для управления этой структурой
- Реализация функций, объявленных в интерфейсе
- Клиентская программа, которая использует функции, объявленные в интерфейсе, для работы на более высоком уровне абстракции
Подобная организация позволяет использовать программу 3.2 с целыми и значениями с плавающей точкой, либо расширить ее для обработки других типов данных, просто откомпилировав вместе со специальным кодом для нужного типа данных. Ниже мы рассмотрим изменения, необходимые для данного примера.
Под термином "интерфейс" подразумевается описание типа данных. Это соглашение между клиентской программой и программой реализации. Клиент соглашается обращаться к данным только через функции, определенные в интерфейсе, а реализация соглашается предоставлять необходимые функции.
Для программы 3.2 интерфейс должен включать следующие объявления:
typedef int Number;
Number randNum();
Первая строка указывает тип обрабатываемых данных, а вторая - операции, связанные с этим типом. Этот код можно поместить в файл с именем, например, Number.h, где на него будут независимо ссылаться и клиенты, и реализации.
Реализация интерфейса Number.h представляет собой функцию randNum, которая может содержать следующий код:
#include <stdlib.h>
#include "Number.h"
Number randNum()
{ return rand(); }
Первая строка содержит ссылку на предоставленный системой интерфейс, в котором описана функция rand(). Вторая строка - ссылка на реализуемый нами интерфейс (она включена для проверки того, что реализуемая и объявленная функции имеют одинаковый тип). Две последних строки содержат код функции. Этот код можно хранить, например, в файле int.c. Реальный код функции rand содержится в стандартной библиотеке времени выполнения C++.
Клиентская программа, соответствующая примеру 3.2, будет начинаться с директив include для интерфейсов, где объявлены используемые функции:
#include <iostream.h>
#include <math.h>
#include "Number.h"
После этих трех строк может следовать описание функции main из программы 3.2. Этот код может храниться, например, в файле с именем avg.c.
Результатом совместной компиляции программ avg.c и int.c будут те же функциональные возможности, что и реализуемые программой 3.2. Но рассматриваемая реализация более гибкая, поскольку связанный с типом данных код инкапсулирован и может использоваться другими клиентскими программами, а также потому, что программа avg.c без изменений может использоваться с другими типами данных. По-прежнему предполагается, что любой тип, используемый под именем Number, преобразуется в тип float. C++ позволяет описывать это преобразование, а также описывать желаемые встроенные операторы (наподобие += и <<) как часть нового типа данных. Использование одних и тех же имен функций или операторов для различных типах данных называется перегрузкой (overloading).
Помимо рассмотренного варианта "клиент-интерфейс-реализация" существует много других способов поддержки различных типов данных. Эта концепция не зависит от определенного языка программирования, либо метода реализации. Однако имена файлов не являются частью языка, и, возможно, придется изменить рекомендованный выше простой метод для функционирования в конкретной среде C++ (в системах существуют различные соглашения или правила, относящиеся к содержимому файлов заголовков, а некоторые системы требуют определенных расширений, таких как .C или .cxx для файлов программ). Одна из наиболее важных особенностей C++ - понятие классов, которые предоставляют удобный метод описания и реализации типов данных. В этой главе за основу взято простое решение, но впоследствии практически повсеместно будут использоваться классы. "Абстрактные типы данных" посвящена применению классов для создания базовых типов данных, важных для разработки алгоритмов. Кроме того, там будет подробно рассмотрено взаимоотношение между классами C++ и парадигмой "клиент-интерфейс-реализация".
Такие механизмы предназначены в основном для поддержки бригад программистов, решающих задачи создания и сопровождения очень больших приложений. Но для нас данный материал важен потому, что на протяжении книги эти механизмы будут применяться как естественный способ замены усовершенствованных реализаций алгоритмов и структур данных старыми методами, чтобы сравнивать различные алгоритмы решения одних и тех же прикладных задач.
Часто приходится создавать структуры данных, которые позволяют обрабатывать наборы данных. Структуры данных могут быть большими, либо интенсивно используемыми. Поэтому необходимо выделить наиболее важные операции, которые будут выполняться над данными, и иметь методы эффективной реализации этих операций. Выполнение этих задач - первые шаги в процессе последовательного создания абстракций более высокого уровня из абстракций низших уровней. Этот процесс представляет собой удобный способ разработки все более мощных программ. Простейшим механизмом группировки данных в C++ являются массивы (array), которые рассматриваются в разделе 3.2, и структуры (structure), о которых пойдет речь ниже.
Структуры представляют собой сгруппированные типы, используемые для описания наборов данных. Этот подход позволяет управлять всем набором как единым целым, сохраняя при этом возможность ссылаться на отдельные компоненты по их именам. Структуры в языке C++ можно использовать для описания нового типа данных, а также для определения операций с этими данными. Другими словами, со сгруппированными данными можно обращаться примерно так же, как со встроенными типами вроде int и float. Как будет показано ниже, можно присваивать имена переменным и передавать эти переменные в качестве аргументов функций, а также выполнять множество других операций.
Например, при обработке геометрических данных используется абстрактное понятие точки на плоскости. Следовательно, можно написать
struct point { float x; float y; } ;
где имя point будет использоваться для указания пар чисел с плавающей точкой.
Выражение
struct point a, b;
объявляет две переменные этого типа. Можно ссылаться по имени на отдельные члены структуры. Например, операторы
a.x = 1.0; a.y = 1.0; b.x = 4.0; b.y = 5.0;
устанавливают значения переменных таким образом, что a представляет точку (1,1), а b - точку (4,5). Кроме того, структуры можно передавать функциям в качестве аргументов. Например, код
float distance(point a, point b)
{ float dx = a.x - b.x, dy = a.y - b.y;
return sqrt(dx*dx + dy*dy);
}
описывает функцию, которая вычисляет расстояние между двумя точками на плоскости. Это демонстрирует естественный способ использования структур для группировки данных в типичных приложениях.
Программа 3.3 представляет собой интерфейс, который содержит описание типа данных для точек на плоскости: в нем используется структура для представления точек и содержится операция вычисления расстояния между двумя точками. Функция, реализующая данную операцию, приведена в программе 3.4. Подобная схема "интерфейс-реализация" используется для описания типов данных при любой возможности, поскольку в ней описание инкапсулировано в интерфейсе, а реализация выражена в прямой и понятной форме. Тип данных используется в клиентской программе за счет включения интерфейса и компиляции реализации совместно с клиентом (либо с помощью средств раздельной компиляции). Программа реализации 3.4 включает интерфейс (программу 3.3), чтобы обеспечить соответствие описания функции потребностям клиента. Смысл в том, чтобы клиентские программы могли работать с точками без необходимости принимать какие-либо допущения об их представлении. В "Абстрактные типы данных" будет показано, как осуществить следующий этап разделения клиента и реализации.
Программа 3.3. Интерфейс типа данных point
Этот интерфейс описывает тип данных, состоящий из набора значений "пары чисел с плавающей точкой" и операции "вычисление расстояния между двумя точками".
struct point { float x; float y; };
float distance(point, point);
Программа 3.4. Реализация структуры данных point
Здесь содержится определение функции distance, объявленной в программе 3.3. Используется библиотечная функция вычисления квадратного корня.
#include <math.h>
#include "Point.h"
float distance(point a, point b)
{ float dx = a.x - b.x, dy = a.y - b.y;
return sqrt(dx*dx + dy*dy);
}
Данный пример структуры point прост и включает два элемента одного типа. Обычно в структурах содержатся различные типы данных. Подобные структуры будут часто встречаться в оставшейся части главы.
Структуры позволяют группировать данные. Кроме того, в языке C++ можно связывать данные с операциями, которые должны с ними выполняться, с помощью механизма классов (class). Подробности определения классов с множеством примеров приводятся в "Абстрактные типы данных" . Классы позволяют даже использовать программу, такую как 3.2, для обработки элементов типа point после описания соответствующих арифметических операций и преобразований типов для точек. Эта возможность использования ранее определенных операций высокого уровня абстракции даже для вновь созданных типов данных является одной из важных и выдающихся особенностей программирования на C++. Она основана на способности непосредственного определения собственных типов данных средствами языка. При этом классы позволяют не только описывать компоновку данных в структуре, но и точно задавать операции над данными (а также структуры данных и алгоритмы, которые их поддерживают). Классы формируют основу рассматриваемых в книге реализаций. Однако прежде чем приступить к детальному изучению описания и использования классов ( "Абстрактные типы данных" ), необходимо рассмотреть ряд низкоуровневых механизмов для управления данными и их объединения.
Помимо предоставления основных типов int, float и char, а также возможности встраивать их в составные типы с помощью описателя struct, C++ допускает косвенные манипуляции с данными. Указатель (pointer) - это ссылка на объект в памяти (обычно реализуемая в виде машинного адреса). Чтобы объявить переменную a как указатель на целое значение, используется выражение int *a. На само целое можно ссылаться значение с помощью записи *a. Возможно объявление указателей на любой тип данных. Унарная операция & предоставляет машинный адрес объекта и удобна для инициализации указателей. Например, выражение *&a означает то же, что и a.
Косвенное обращение к объекту через указатель часто удобнее прямого обращения, а также может оказаться более эффективным, особенно для больших объектов. Множество примеров этого преимущества приведено в разделах с 3.3 по 3.7. Как будет показано, еще более важна возможность использования указателей в структурах данных способами, которые поддерживают эффективные алгоритмы обработки данных. Указатели служат основой многих структур данных и алгоритмов.
Простой и важный пример использования указателей связан с описанием функции, которая должна возвращать несколько значений. Например, следующая функция (использующая функции sqrt и atan2 из стандартной библиотеки) преобразует декартовы координаты в полярные:
polar(float x, float y, float *r, float *theta)
{ *r = sqrt(x*x + y*y); *theta = atan2(y, x); }
Аргументы передаются этой функции по значению - если функция и присвоит новое значение переменной аргумента, эта операция является локальной и скрыта от вызывающей функции. Поэтому функция не может изменять указатели на числа с плавающей точкой r и theta, но способна изменять значения самих чисел с помощью косвенного обращения. Например, если вызывающая функция содержит объявление float a, b, то вызов функции
polar(1.0, 1.0, &a, &b)
приведет к тому, что для a установится значение 1.414 214 (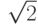 ), а для b - значение 0.785398 (п/4). Оператор & позволяет передавать адреса a и b в функцию, которая работает с этими аргументами как с указателями.
), а для b - значение 0.785398 (п/4). Оператор & позволяет передавать адреса a и b в функцию, которая работает с этими аргументами как с указателями.
В языке C++ можно достичь того же результата посредством ссылочных параметров:
polar(float x, float y, floats r, floats theta)
{ r = sqrt(x*x + y*y); theta = atan2(y, x); }
Запись floats означает "ссылка на float". Ссылки можно рассматривать как встроенные указатели, при каждом использовании которых выполняется автоматический переход. Например, в этой функции ссылка на theta означает ссылку на любую переменную float, используемую во втором аргументе вызывающей функции. Если вызывающая функция содержит объявление float a, b, как в примере из предыдущего абзаца, то в результате вызова функции polar(1.0, 1.0, a, b) переменной a будет присвоено значение 1.414214, а переменной b - значение 0.785398.
До сих пор речь в основном шла об описании отдельных информационных элементов, обрабатываемых программами. Во многих случаях необходимо работать с потенциально крупными наборами данных, и сейчас мы обратимся к основным методам достижения этой цели. Обычно термин структура данных относится к механизму организации информации для обеспечения удобных и эффективных средств управления и доступа к ней. Многие важные структуры данных основаны либо на одном из двух элементарных решений, рассматриваемых ниже, либо на обоих сразу. Массив (array) служит средством организации объектов четко упорядоченным образом, что более удобно для доступа, чем для управления. Список (list) позволяет организовать объекты в виде логической последовательности, что более удобно для управления, чем для доступа.
Упражнения
- 3.1. Найдите наибольшее и наименьшее числа, которые можно представить типами int, long int, short int, float и double в своей среде программирования.
- 3.2. Протестируйте генератор случайных чисел в своей системе. Для этого сгенерируйте N случайных целых чисел в диапазоне от 0 до r - 1 с помощью выражения rand() % r и вычислите среднее значение и среднеквадратичное отклонение для r = 10, 100 и 1000 и N = 103, 104, 105 и 106 .
- 3.3. Протестируйте генератор случайных чисел в своей системе. Для этого сгенерируйте N случайных чисел типа double в диапазоне от 0 до 1, преобразуя их в целые числа диапазона от 0 до r - 1 путем умножения на r и усечения результата. Затем вычислите среднее значение и среднеквадратичное отклонение для r = 10, 100 и 1000 и N = 103, 104, 105 и 106 .
- 3.4. Выполните упражнения 3.2 и 3.3 для r = 2, 4 и 16.
- 3.5. Реализуйте функции, позволяющие применять программу 3.2 для случайных разрядов (чисел, которые могут принимать значения только 0 и 1).
- 3.6. Определите структуру для представления игральных карт.
- 3.7. Напишите клиентскую программу, которая использует типы данных из программ 3.3 и 3.4, для следующей задачи: чтение последовательности точек (пар чисел с плавающей точкой) из стандартного устройства ввода и поиск точки, ближайшей к первой.
- 3.8. Добавьте к типу данных point (программы 3.3 и 3.4) функцию, которая определяет, лежат ли три точки на одной прямой, с допуском 10-4. Считайте, что все точки находятся в единичном квадрате.
- 3.9. Определите тип данных для треугольников, находящихся в единичном квадрате, включая функцию вычисления площади треугольника. Затем напишите клиентскую программу, которая генерирует случайные тройки пар чисел с плавающей точкой от 0 до 1 и вычисляет среднюю площадь сгенерированных треугольников.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |