|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2193 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 4:
Абстрактные типы данных
Реализации АТД стека
В данном разделе рассматриваются две реализации АТД стека: в одной используются массивы, а в другой - связные списки. Эти реализации получаются в результате простого применения базовых средств, рассмотренных в "Элементарные структуры данных" . Мы считаем, что они различаются только своей производительностью.
Если для представления стека применяется массив, то все функции, объявленные в программе 4.4, реализуются очень просто - см. программу 4.7. Элементы заносятся в массив в точности так, как показано на рис. 4.1, при этом отслеживается индекс верхушки стека. Выполнение операции втолкнуть означает запоминание элемента в позиции массива, указываемой индексом верхушки стека, а затем увеличение этого индекса на единицу; выполнение операции вытолкнуть означает уменьшение индекса на единицу и извлечение элемента, обозначенного этим индексом.
Программа 4.7. Реализация стека магазинного типа на базе массива
В этой реализации N элементов стека хранятся как элементы массива: s[0], ..., s[N-1], начиная с первого занесенного элемента и завершая последним. Верхушкой стека (позицией, в которую будет занесен следующий элемент стека) является элемент s[N]. Максимальное количество элементов, которое может вмещать стек, программа-клиент передает в виде аргумента в конструктор STACK, размещающий в памяти массив заданного размера. Однако код не проверяет такие ошибки, как помещение элемента в заполненный стек (или выталкивание элемента из пустого стека).
template <class Item>
class STACK
{
private:
Item *s; int N;
public:
STACK(int maxN)
{ s = new Item[maxN]; N = 0; }
int empty() const
{ return N == 0; }
void push(Item item)
{ s[N++] = item; }
Item pop()
{ return s[ - N]; }
};
Операция создать (конструктор) выполняет выделение памяти под массив указанного размера, а операция проверить, пуст ли стек проверяет, равен ли индекс нулю. Скомпилированная вместе с клиентской программой (такой, как программа 4.5 или 4.6), эта реализация обеспечивает эффективный стек магазинного типа.
Известен один потенциальный недостаток применения представления стека (и не только) в виде массива: до использования массива необходимо знать его максимальный размер, чтобы выделить под него память. В рассматриваемой реализации эта информация передается в аргументе конструктора. Это ограничение - результат выбора реализации на базе массива; оно не присуще самому АТД стека. Зачастую бывает трудно определить максимальное число элементов, которое программа будет заносить в стек, и если выбрать слишком большое число, то такая реализация будет неэффективно использовать память, а это может быть нежелательно в тех приложениях, где память является ценным ресурсом. А если выбрать слишком маленькое число, программа может вообще оказаться неработоспособной. Применение АТД дает возможность рассматривать другие варианты и изменять реализацию без изменения кода клиентских программ.
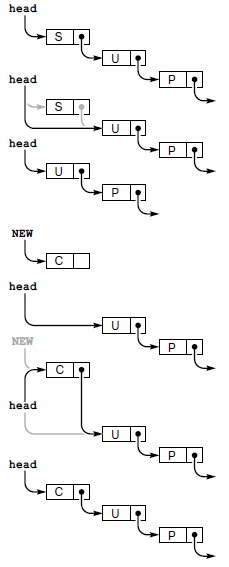
Например, чтобы стек мог свободно увеличиваться и уменьшаться, можно отдать предпочтение связному списку, как в программе 4.8. В таком стеке элементы будут храниться в обратном порядке по сравнению с реализацией на базе массива - начиная с последнего занесенного элемента и завершая первым (см. рис. 4.5). Это позволяет более просто реализовать базовые стековые операции. Чтобы вытолкнуть элемент, удаляется узел из начала списка, и из него извлекается элемент; чтобы втолкнуть элемент, создается новый узел и добавляется в начало списка. Поскольку все операции связного списка выполняются в начале списка, ведущий узел не нужен.
Стек представлен указателем head, который указывает на первый (последний вставленный) элемент. Чтобы вытолкнуть элемент из стека (вверху), удаляется элемент из начала списка, а в head заносится ссылка из этого элемента. Чтобы втолкнуть в стек новый элемент (внизу), он присоединяется в начало списка: в его поле ссылки заносится значение head, а в head - указатель на этот новый элемент.
Программа 4.8. Реализация стека магазинного типа на базе связного списка
В этой программе АТД реализуется с помощью связного списка. Представление данных для узлов связного списка организовано традиционным способом (см. "Элементарные структуры данных" ) и включает конструктор для узлов, который заполняет каждый новый узел заданными элементом и ссылкой.
template <class Item>
class STACK
{
private:
struct node
{ Item item; node* next;
node(Item x, node* t)
{ item = x; next = t; }
};
typedef node *link;
link head;
public:
STACK(int)
{ head = 0; }
int empty() const
{ return head == 0; }
void push(Item x)
{ head = new node(x, head); }
Item pop()
{ Item v = head->item; link t = head->next;
delete head; head = t; return v; }
};
Программа 4.8 не проверяет такие ошибки, как попытка извлечения элемента из пустого стека, занесение элемента в переполненный стек или нехватка памяти. В отношении двух последних условий имеются две возможности. Их можно трактовать как не связанные между собой ошибки и отслеживать количество элементов в списке, а при каждом занесении в стек проверять, что счетчик не превышает значение, переданное конструктору в качестве аргумента, и что операция new выполнена успешно. Но можно выбрать позицию, когда не требуется заранее знать максимальный размер стека, и, игнорируя аргумент конструктора, сообщать о переполнении стека только при отказе операции new (см. упражнение 4.24).
Программы 4.7 и 4.8 представляют две различные реализации одно и того же АТД. Можно заменять одну реализацию другой, не делая никаких изменений в клиентских программах, подобных тем, которые рассматривались в разделе 4.3. Они отличаются только производительностью. Реализация на базе массива использует объем памяти, необходимый для размещения максимального числа элементов, которые может вместить стек в процессе вычислений; реализация на базе списка использует объем памяти, пропорциональный количеству элементов, но при этом всегда расходует дополнительную память для одной ссылки на каждый элемент, а также дополнительное время на выделение памяти при каждой операции втолкнуть и освобождение памяти при каждой операции вытолкнуть. Если требуется стек больших размеров, который обычно заполняется практически полностью, то, по-видимому, предпочтение стоит отдать реализации на базе массива. Если же размер стека варьируется в широких пределах, и имеются другие структуры данных, которые могут занимать память тогда, когда в стеке находятся лишь несколько элементов, лучше воспользоваться реализацией на базе связного списка.
Мы еще не раз увидим в данной книге, что эти же самые соображения относительно использования оперативной памяти справедливы для многих реализаций АТД. Разработчикам часто приходится выбирать между возможностью быстрого доступа к любому элементу при необходимости заранее указывать максимальное число требуемых элементов (в реализации на базе массивов) и использованием памяти пропорционально количеству используемых элементов, но без возможности быстрого доступа к любому элементу (в реализации на базе связных списков).
Помимо этих основных соображений об использования памяти, обычно нас больше всего интересуют различия в производительности разных реализаций АТД, которые влияют на время выполнения. В данном случае различия между двумя рассмотренными реализациями незначительны.
Лемма 4.1. Используя либо массивы, либо связные списки для АТД стека магазинного типа, можно реализовать операции втолкнуть и вытолкнуть, имеющие постоянное время выполнения.
Этот факт непосредственно следует из внимательного изучения программ 4.7 и 4.8. 
То, что в реализациях на базе массива и связного списка элементы стека хранятся в разном порядке, для клиентских программ не имеет никакого значения. В реализациях могут использоваться какие угодно структуры данных, лишь бы они создавали впечатление абстрактного стека магазинного типа. В обоих рассмотренных случаях реализации способны создавать впечатление эффективного абстрактного объекта, который может выполнять необходимые операции с помощью всего лишь нескольких машинных инструкций. В данной книге мы будем разрабатывать структуры данных и эффективные реализации для других важных АТД.
Реализация на базе связного списка создает впечатление стека, который может увеличиваться неограниченно. Однако в реальности такой стек невозможен: рано или поздно, когда запрос на выделение еще некоторого объема памяти не сможет быть выполнен, операция new сгенерирует исключение. Можно также организовать стек на базе массива, который будет увеличиваться и уменьшаться динамически: когда стек заполняется наполовину, размер массива увеличивается в два раза, а когда стек становится наполовину пустым, размер массива уменьшается в два раза. Детали реализации такой стратегии мы оставляем в качестве упражнения в "Хеширование" , где этот процесс будет подробно рассмотрен для более сложных применений.
Упражнения
- 4.21. Определите содержимое элементов s[0], ..., s[4] после выполнения программой 4.7 операций, показанных на рис. 4.1.
- 4.22. Предположим, что вы заменяете в интерфейсе стека магазинного типа операцию проверить, пуст ли стек на операцию подсчитать, которая возвращает количество элементов, находящихся в данный момент в структуре данных. Реализуйте операцию подсчитать для представления на базе массива (программа 4.7) и представления на базе связного списка (программа 4.8).
- 4.23. Измените реализацию стека магазинного типа на базе массива (программа 4.7) так, чтобы в ней вызывалась функция-член error() при попытке клиентской программы выполнить операцию вытолкнуть, когда стек пуст, или операцию втолкнуть, когда стек переполнен.
- 4.24. Измените реализацию стека магазинного типа на базе связного списка (программа 4.8) так, чтобы в ней вызывалась функция-член error() при попытке клиентской программы выполнить операцию вытолкнуть, когда стек пуст, или операцию втолкнуть, когда отсутствует доступная память при вызове new.
- 4.25. Измените реализацию стека магазинного типа на базе связного списка (программа 4.8) так, чтобы для создания списка в ней использовался массив индексов (см. рис. 3.4).
- 4.26. Напишите реализацию стека магазинного типа на базе связного списка, в которой элементы списка хранятся начиная с первого занесенного элемента и завершая последним занесенным элементом. Потребуется использовать двухсвязный список.
- 4.27. Разработайте АТД, предоставляющий два разных стека магазинного типа. Воспользуйтесь реализацией на базе массива. Один стек расположите в начале массива, а другой - в конце. (Если клиентская программа работает так, что при увеличении одного стека другой уменьшается, эта реализация будет занимать меньший объем памяти, чем другие варианты.)
- 4.28. Реализуйте функцию вычисления инфиксных выражений, содержащих целые числа. Она должна включать программы 4.5 и 4.6 и использовать АТД из упражнения 4.27. Примечание: используйте тот факт, что оба стека содержат элементы одного и того же типа.
Создание нового АТД
В разделах 4.2 - 4.4 приведен пример полного кода программы на C++ для одной из наиболее важных абстракций: стека магазинного типа. В интерфейсе из раздела 4.2 определены основные операции; клиентские программы, вроде приведенных в разделе, 4.3 могут использовать эти операции независимо от их реализации, а реализация из раздела 4.4 обеспечивает конкретное представление и программный код АТД.
Создание нового АТД часто сводится к следующему процессу. Начав с разработки клиентской программы, предназначенной для решения прикладной задачи, определяются операции, которые считаются наиболее важными: какие операции хотелось бы выполнять над данными? Потом определяется интерфейс и записывается код программы-клиента, чтобы проверить, упростит ли использование АТД реализацию клиентской программы. Затем выполняется анализ, можно ли достаточно эффективно реализовать АТД для нужных операций. Если нет, необходимо найти источник неэффективности, а затем изменить интерфейс, поместив в него операции, более подходящие для эффективной реализации. Поскольку модификация влияет и на клиентскую программу, ее потребуется тоже соответствующим образом изменить. После нескольких таких итераций мы получим работающую клиентскую программу и работающую реализацию; тогда интерфейс "замораживается", т.е. мы решаем больше не изменять его. С этого момента разработка клиентских программ и реализаций выполняется раздельно: можно писать другие клиентские программы, использующие тот же самый АТД (скажем, программы-драйверы для тестирования АТД), можно записывать другие реализации, и можно сравнивать производительность различных реализаций.
В других ситуациях можно начать с определения АТД. При таком подходе необходимо решить следующие вопросы: какие базовые операции над имеющимися данными могут потребоваться клиентским программам, и какие операции мы умеем реализовать эффективно? Завершив разработку реализации, можно проверить ее эффективность с помощью клиентских программ. Перед окончательным "замораживанием" интерфейса, возможно, потребуется дополнительная модификация и тестирование.
В "Введение" был подробно рассмотрен пример, где размышления о том, какой уровень абстракции использовать, помогли отыскать эффективный алгоритм решения сложной задачи. Теперь посмотрим, как обсуждаемый в настоящей лекции обобщенный подход можно применить для инкапсуляции абстрактных операций из "Введение" .
В программе 4.9 определен интерфейс, включающий две операции (не считая операции создать). Похоже, что эти операции описывают алгоритмы связности, рассмотренные в "Введение" , на высоком уровне абстракции. Независимо от базовых алгоритмов и структур данных, необходимо иметь возможность проверки связности двух узлов, а также объявления, что конкретные два узла являются связанными.
Программа 4.10 - это клиентская программа, которая решает задачу связности, используя АТД с интерфейсом, представленным в программе 4.9. Одно из преимуществ этого АТД состоит в наглядности программы, поскольку она написана с использованием абстракций, позволяющих естественно представить процесс вычислений.
Программа 4.11 является реализацией интерфейса объединение-поиск, который определен в программе 4.9. В этой реализации (см. раздел 1.3 "Введение" ) применяется лес деревьев, в основе которого лежат два массива, представляющие известную информацию о связях. В разных алгоритмах, рассмотренных в "Введение" , используются различные реализации АТД, причем их можно тестировать независимо друг от друга, не изменяя клиентскую программу.
Программа 4.9. Интерфейс АТД для отношений эквивалентности
Интерфейс АТД построен так, чтобы было удобно записывать код, в точности соответствующий принятому решению выражать алгоритм связности с помощью класса, поддерживающего три абстрактных операции: инициализировать (initialize) абстрактную структуру данных для отслеживания связей между заданным числом узлов; найти (find), являются ли два узла связанными; и соединить (unite) два данных узла и считать их с этого момента связанными.
class UF
{
private:
// Программный код, зависящий от реализации
public:
UF(int);
int find(int, int);
void unite(int, int);
};
Программа 4.10. Клиент для АТД отношений эквивалентности
АТД из программы 4.9 позволяет отделить алгоритм определения связности от реализации объединение-поиск, делая его более доступным.
#include <iostream.h>
#include <stdlib.h>
#include "UF.cxx"
int main(int argc, char *argv[])
{ int p, q, N = atoi(argv[1]);
UF info(N);
while (cin >> p >> q)
if (!info.find(p, q))
{
info.unite(p, q);
cout << " " << p << " " << q << endl;
}
}
Программа 4.11. Реализация АТД отношений эквивалентности
Этот код взвешенного быстрого объединения из "Введение" является реализацией интерфейса из программы 4.9 в форме, удобной для его использования в других приложениях. Перегруженная приватная функция-член find реализует обход дерева вплоть до его корня.
class UF
{
private:
int *id, *sz;
int find(int x)
{ while (x != id[x]) x = id[x];
return x; }
public:
UF(int N)
{
id = new int[N]; sz = new int[N];
for (int i = 0; i < N; i++)
{ id[i] = i; sz[i] = 1; }
}
int find(int p, int q)
{ return (find(p) == find(q)); }
void unite(int p, int q)
{ int i = find(p), j = find(q);
if (i == j) return;
if (sz[i] < sz[j])
{ id[i] = j; sz[j] += sz[i]; }
else
{ id[j] = i; sz[i] += sz[j]; }
}
};
Программы на основе этого АТД несколько менее эффективны, нежели программа связности из "Введение" , поскольку в нем не учитывается, что в данной программе каждой операции объединение непосредственно предшествует операция поиск. Подобные дополнительные издержки являются платой за переход к более абстрактному представлению. В данном случае существует множество способов устранения этого недостатка, например, за счет усложнения интерфейса или реализации (см. упражнение 4.30). На практике пути бывают очень короткими (особенно, если применяется сжатие пути), так что в данном случае дополнительные издержки окажутся незначительными.
Сочетание программ 4.10 и 4.11 функционально эквивалентно программе 1.3, однако разбиение программы на две части более эффективно, так как:
- позволяет отделить решение задачи высокого уровня (задачи связности) от решения задачи низкого уровня (задачи объединение-поиск) и решать эти две задачи независимо
- предоставляет естественный способ сравнения различных алгоритмов и структур данных, применяемых при решении этой задачи
- определяет с помощью интерфейса способ проверки, что программа работает как задумано
- обеспечивает механизм, позволяющий переходить к новым представлениям (к новым структурам данных или новым алгоритмам) без каких-либо изменений кода клиентских программ
- предоставляет абстракцию, с помощью которой можно конструировать другие алгоритмы
Все эти преимущества характерны для многих задач, с которыми приходится сталкиваться при разработке компьютерных программ, так что эти базовые принципы построения абстрактных типов данных применяются исключительно широко.
В коде программы 4.11 смешаны интерфейс и реализация; поэтому он не допускает отдельную компиляцию клиентских программ и реализаций. Для того чтобы разные реализации могли использовать один и тот же интерфейс, программу можно, как в разделе 3.1 "Элементарные структуры данных" , разделить на три файла следующим образом.
Создается заголовочный файл - скажем, с именем UF.h - который будет содержать объявление класса, представление данных и объявления функций, но не определения функций. В рассматриваемом примере этот файл будет содержать код программы 4.9, в который также включается представление данных (приватные объявления из программы 4.11). Определения функций необходимо сохранить в отдельном файле .cxx, который (как и все клиенты) будет также содержать директиву include для файла UF.h. В этом случае появляется возможность раздельной компиляции клиентских программ и реализаций. Вообще-то определение любой функции-члена класса можно поместить в отдельный файл, если эта функция-член объявлена в классе, а в определении функции перед ее именем находится имя класса и знак ::. Например, определение функции find в нашем примере следовало бы записать так:
int UF::find(int p, int q)
{ return (find(p) == find(q)); }
К сожалению, при раздельной компиляции разные компиляторы налагают различные требования на реализацию шаблонов. Проблема заключается в том, что компилятор не может создать код для функции-члена, не зная типа параметра шаблона, который недоступен, так как определен в главной программе. Определение функций-членов внутри объявлений классов позволяет избежать таких проблем с компиляцией.
Однако такая трехфайловая система все равно не идеальна, поскольку представление данных хранится в одном файле с интерфейсом, хотя в действительности является частью реализации. С помощью ключевого слова private можно закрыть доступ к нему со стороны клиентских программ, но если провести в реализации изменения, которые требуют изменений в представлении данных, то придется изменить .h-файл и перекомпилировать все клиентские программы. Во многих ситуациях разработки программного обеспечения информация о программах-клиентах может отсутствовать, так что это слишком жесткое требование. Но иногда такой подход может иметь смысл. В случае очень большого и сложного АТД можно сначала договориться о представлении данных и интерфейсе, а уже потом усадить команду программистов за разработку различных частей реализации. В этом случае общедоступная часть интерфейса служит соглашением между программистами и клиентами, а приватная часть - соглашением сугубо между программистами. К тому же в ситуациях, когда необходимо найти оптимальный способ решения некоторой задачи при условии, что должна использоваться некая конкретная структура данных, эта стратегия - именно то, что нужно. Таким образом можно повысить производительность, изменив лишь незначительную часть огромной системы.
В языке C++ имеется механизм, специально предназначенный для того, чтобы писать программы с хорошо определенным интерфейсом, который позволяет полностью отделять клиентские программы от реализаций. Этот механизм базируется на понятии производных (derived) классов, посредством которых можно дополнять или переопределять некоторые члены существующего класса. Включение ключевого слова virtual в объявление функции-члена означает, что эта функция может быть переопределена в производном классе; добавление последовательности символов = 0 в конце объявления функции-члена указывает, что данная функция является чисто виртуальной (pure virtual) функцией, которая должна быть переопределена в любом производном классе. Производные классы обеспечивают удобный способ создания программ на основе работ других программистов и являются важным компонентом объектно-ориентированных систем программирования.
Абстрактный (abstract) класс - это класс, все члены которого являются чисто виртуальными функциями. В любом классе, порожденном от абстрактного класса, должны быть определены все функции-члены и любые необходимые приватные данные-члены - таким образом, согласно нашей терминологии, абстрактный класс является интерфейсом, а любой класс, порожденный от него, является реализацией. Программы-клиенты могут использовать интерфейс, а система C++ может обеспечить соблюдение соглашений между клиентами и реализациями, даже когда клиенты и реализации функций компилируются раздельно. Например, в программе 4.12 показан абстрактный класс uf для отношений эквивалентности; если изменить первую строку программы 4.11 следующим образом:
class UF : public class uf
то она будет указывать, что класс UF является производным от класса uf, и поэтому в нем определены (как минимум) все функции-члены класса uf - т.е. класс UF является реализацией интерфейса uf.
К сожалению, использование абстрактных классов влечет за собой значительное увеличение времени выполнения программы, поскольку каждый вызов виртуальной функции требует обращения к таблице указателей на функции-члены. Кроме того, компиляторы сильно ограничены в возможностях при оптимизации кода для абстрактных классов. Рассматриваемые в книге алгоритмы и структуры данных часто задействованы в частях системы, критичных к производительности, поэтому такая цена за гибкость, предоставляемую абстрактными классами, может оказаться непозволительно большой.
Есть еще один способ - применение четырех файлов, когда приватные части хранятся не в интерфейсе, а в отдельном файле. Например, в начало класса из программы 4.9 можно было бы добавить строки
private:
#include "UFprivate.h"
и поместить в файл UFprivate.h строки
int *id, *sz;
int find(int);
Эта стратегия позволяет аккуратно разграничить четыре компонента (клиентскую программу, реализацию, представление данных и интерфейс) и обеспечивает максимальную гибкость при экспериментировании со структурами данных и алгоритмами.
Программа 4.12. Абстрактный класс для АТД отношения эквивалентности
Приведенный ниже код формирует интерфейс АТД отношения эквивалентности, который обеспечивает полное разделение клиентов и реализаций (см. текст).
class uf
{
public:
virtual uf(int) = 0;
virtual int find(int, int) = 0;
virtual void unite(int, int) = 0;
};
Гибкость, которую дают производные классы и стратегия "четырех файлов ", сохраняет возможность (может быть, непреднамеренного) нарушения соглашений между клиентами и реализациями в отношении того, каким должен быть АТД. Все эти механизмы гарантируют, что клиентские программы и реализации будут корректно компоноваться; однако они также зависят друг от друга для выполнения таких действий, которые в общем случае нельзя описать формально. Например, предположим, что какой-нибудь неопытный программист не смог разобраться в нашем алгоритме взвешенного быстрого поиска и решил заменить его алгоритмом быстрого объединения (или, что еще хуже, реализацией, которая даже не дает правильного решения). Мы всегда стремились к тому, чтобы такие изменения вносились легко, но в данном случае это может совершенно испортить программу-клиент в важном приложении, которое зависит от производительности реализации для крупных задач. Практика программирования полна подобных примеров, и от них очень трудно защититься.
Однако подобные рассуждения уводят нас к свойствам языков программирования, компиляторов, компоновщиков и сред выполнения программ, что весьма далеко от темы алгоритмов. Поэтому мы обычно будем придерживаться простого разделения программы на два файла, где АТД реализуются в виде классов C++, общедоступные функции-члены составляют интерфейс, а реализация объединена с интерфейсом в отдельном файле, который включается в программы-клиенты и компилируется каждый раз при компиляции клиентов. В основном это связано с тем, что реализация в виде класса - это удобное и компактное средство представления структур данных и алгоритмов. Но если для какого-либо отдельного приложения потребуется большая гибкость, которая может быть обеспечена одним из рассмотренных способов, то ничто не помешает нам соответствующим образом изменить структуры классов.
Упражнения
- 4.29. Измените программу 4.11 так, чтобы в ней использовалось сжатие пути делением пополам.
- 4.30. Устраните упоминаемую в тексте неэффективность программы, добавив в программу 4.9 операцию, которая объединяет операции объединение и поиск, и соответствующим образом изменив программы 4.11 и 4.10.
- 4.31. Измените интерфейс (программа 4.9) и реализацию (программа 4.11) для отношений эквивалентности так, чтобы в них присутствовала функция, возвращающая количество узлов, которые связаны с данным.
- 4.32. Измените программу 4.11 так, чтобы для представления структуры данных в ней вместо параллельных массивов использовался массив структур.
- 4.33. Напишите программу из трех файлов (без шаблонов), вычисляющую значение постфиксного выражения с помощью стека целых чисел. Обеспечьте, чтобы клиентскую программу (аналог программы 4.5) можно было компилировать отдельно от реализации стека (аналог программы 4.7).
- 4.34. Измените решение предыдущего упражнения - отделите представление данных от реализаций функций-членов (программа из четырех файлов). Протестируйте полученный результат, подставив реализацию стека на базе связного списка (аналог программы 4.8) без перекомпиляции программы-клиента.
- 4.35. Создайте полную реализацию АТД отношения эквивалентности на базе абстрактного класса с виртуальными функциями и сравните производительность полученной программы и программы 4.11 на крупных задачах связности (в стиле таблицы 1.1).
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |