

|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2178 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 4:
Абстрактные типы данных
АТД первого класса
Интерфейсы и реализации АТД стека и очереди в разделах с 4.2 по 4.7 выполняют важную функцию: они скрывают от клиентских программ структуру данных, используемую в реализации. Эти АТД повсеместно встречаются и будут служить в качестве основы для множества других реализаций, рассматриваемых в книге.
Однако если такие типы данных использовать в программах аналогично встроенным типам данных, например, int или float, то возможны неприятности. В данном разделе мы научимся конструировать АТД, с которыми можно работать так же, как и со встроенными типами данных, и все-таки скрывать от клиентов детали реализации.
Определение 4.4. Тип данных первого класса - это тип данных, который можно использовать в программах таким же образом, как и встроенные типы данных.
Например, типы данных первого класса можно использовать в объявлениях переменных, в операторах присваивания, в аргументах и возвращаемых значениях функций. В этом определении, равно как и в других, относящихся к типам данных, нельзя достигнуть точности, не углубившись в сложные вопросы семантики операций. Как будет показано, одно дело требовать, чтобы можно было написать a = b, где a и b - объекты определенного пользователем класса, и совсем другое дело точно определить, что означает эта запись.
В идеале хотелось бы, чтобы все типы данных имели некоторый универсальный набор хорошо определенных операций; в действительности же каждый тип данных характеризуется своим собственным набором операций. Это различие между типами данных само по себе препятствует точному определению типа данных первого класса, поскольку оно предполагает необходимость дать определения для каждой операции, заданной для встроенных типов данных, а это бывает редко. Однако чаще всего важны лишь несколько критических операций, и вполне достаточно применять их для собственных типов данных так же, как и для встроенных типов.
Во многих языках программирования создание типов данных первого класса является делом трудным или даже невозможным; но в языке C++ есть все необходимые базовые инструменты - это концепция класса и возможность перегрузки операций. Язык C++ позволяет легко определять классы, которые являются типами данных первого класса; более того, имеется четкий способ модернизации тех классов, которые таковыми не являются.
Метод, который применяется в языке C++ для реализации типов данных первого класса, применим к любому классу: в частности, он применим к обобщенным очередям и, таким образом, дает возможность создания программ, которые оперируют со стеками и очередями FIFO практически так же, как и с другими типами данных C++. При изучении алгоритмов эта возможность достаточно важна, поскольку она предоставляет естественный способ выражения высокоуровневых операций с такими АТД. Например, можно говорить об операциях объединения двух очередей - т.е. создания из них одной очереди. Далее будут рассматриваться алгоритмы, которые реализуют такие операции для АТД очереди с приоритетами ( "Очереди с приоритетами и пирамидальная сортировка" ) и АТД таблицы символов ( "Таблицы символов и деревья бинарного поиска" .
Если доступ к типу данных первого класса осуществляется только через интерфейс, то это АТД первого класса (см. определение 4.1). Обеспечение возможности работать с экземплярами АТД примерно так же, как со встроенными типами данных, например, int или float - важная цель многих языков программирования высокого уровня, поскольку это позволяет написать любую программу так, чтобы она могла обрабатывать наиболее важные объекты приложения. Это позволяет большому коллективу программистов одновременно работать над большими системами, используя точно определенный набор абстрактных операций. Кроме того, это позволяет реализовывать абстрактные операции самыми разными способами без какого-либо изменения кода приложения (например, для новых компьютеров или сред программирования).
Для начала в качестве примера рассмотрим АТД первого класса, соответствующий абстракции комплексного числа. Наша цель - получить возможность записывать программы, подобные программе 4.17, которая выполняет алгебраические действия над комплексными числами с помощью операций, определенных в АТД. В данной программе объявляются и инициализируются комплексные числа, а также применяются операции *= и <<. Можно было бы воспользоваться и другими операциями, но в качестве примера достаточно рассмотреть только эти две. На практике часто используется класс complex из библиотеки C++ , в котором перегружены все необходимые операции, включая даже тригонометрические функции.
Работа программы 4.17 основана на некоторых математических свойствах комплексных чисел. Cейчас мы немного отклонимся от основной темы и кратко рассмотрим эти свойства. В некотором смысле это даже и не отклонение, поскольку достаточно интересно рассмотреть связь между комплексными числами как математической абстракцией и их представлением в компьютерной программе.
Число 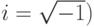 i = V-1 является мнимым числом. Хотя
i = V-1 является мнимым числом. Хотя  как вещественное число не имеет смысла, мы называем его i и выполняем над ним алгебраические операции, заменяя каждый раз i2 на - 1. Комплексное число состоит из двух частей, вещественной и мнимой, и записывается в виде a + bi, где а и b - вещественные числа. Для умножения комплексных чисел применяются обычные алгебраические правила, только i2 всякий раз заменяется на -1. Например:
как вещественное число не имеет смысла, мы называем его i и выполняем над ним алгебраические операции, заменяя каждый раз i2 на - 1. Комплексное число состоит из двух частей, вещественной и мнимой, и записывается в виде a + bi, где а и b - вещественные числа. Для умножения комплексных чисел применяются обычные алгебраические правила, только i2 всякий раз заменяется на -1. Например:
(а + bi)(c + di) = ac + bci + adi + bdi2 = (ac - bd) + (ad + bc)i .
Программа 4.17. Драйвер комплексных чисел (корни из единицы)
Эта клиентская программа выполняет вычисления над комплексными числами с использованием АТД, который позволяет проводить вычисления непосредственно с интересующей нас абстракцией. Для этого объявляются переменные типа Complex, которые затем задействуются в арифметических выражениях с перегруженными операциями. Данная программа проверяет реализацию АТД, вычисляя степени корней из единицы. При помощи соответствующего определения перегруженной операции << (см. упражнение 4.70) выводится таблица, приведенная на рис. 4.12.
#include <iostream.h>
#include <stdlib.h>
#include <math.h>
#include "COMPLEX.cxx"
int main(int argc, char *argv[])
{ int N = atoi(argv[1]);
cout << N << " комплексные корни из единицы" << endl;
for (int k = 0; k < N; k++)
{ float theta = 2.0*3.1415 9*k/N;
Complex t(cos(theta), sin(theta)), x = t;
cout << k << ": " << t << " ";
for (int j = 0; j < N-1; j++) x *= t;
cout << x << endl;
}
}
При умножении комплексных чисел вещественные или мнимые части могут сокращаться (принимать значения 0), например:
(1 - i) (1 - i) = 1 - i - i + i2 = - 2i,
(1 + i)4 = 4i2 = -4,
(1 + i)8 = 16.
Разделив обе части последнего уравнения на 16 = 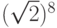 , получим
, получим
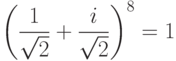
Вообще говоря, имеется много комплексных чисел, которые при возведении в степень дают 1. Они называются комплексными корнями из единицы. Действительно, для каждого натурального N имеется ровно N комплексных чисел z, для которых справедливо zN = 1. Нетрудно показать, что этим свойством обладают числа
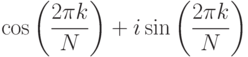 ,
,
для к = 0, 1, ... , N - 1 (см. упражнение 4.68). Например, если в этой формуле взять к = 1 и N = 8, получим только что найденный корень восьмой степени из единицы.
Программа 4.17 вычисляет все корни N-ой степени из единицы для любого данного N и затем возводит их в N-ю степень с помощью операции *=, определенной в данном АТД. Выходные данные программы показаны на рис. 4.12 рис. 4.12. При этом каждое из этих чисел, возведенное в N-ю степень, должно дать один и тот же результат - 1, или 1 + 0i. Полученные мнимые части не равны строго нулю из-за ограниченной точности вычислений. Наш интерес к этой программе объясняется тем, что класс Complex используется в ней точно так же, как встроенный тип данных. Ниже будет подробно показано, почему это возможно.
Даже в таком простом примере важно, чтобы тип данных был абстрактным, поскольку имеется еще одно стандартное представление, которым можно было бы воспользоваться - полярные координаты (см. упражнение 4.67).
Эта таблица содержит выходные данные программы 4.17 для вызова с параметрами a.out 8, а реализация перегруженной операции << выполняет соответствующее форматирование выходных данных (см. упр. 4.70). Восемь комплексных корней из единицы равны: 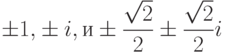 (два левых столбца). При возведении в восьмую степень все эти восемь чисел дают в результате 1 + 0i (два левых столбца).
(два левых столбца). При возведении в восьмую степень все эти восемь чисел дают в результате 1 + 0i (два левых столбца).
Программа 4.18 - это интерфейс, который может использоваться такими клиентами, как программа 4.17; а программа 4.19 - это реализация, в которой используется стандартное представление данных (одно число типа float для вещественной части и одно для мнимой).
Когда в программе 4.17 выполняется операция x = t, где x и t являются объектами класса Complex, система выделяет память для нового объекта и копирует в новый объект значения, относящиеся к объекту t. То же самое происходит и при использовании объекта класса Complex в качестве аргумента или возвращаемого значения функции. А когда объект выходит за пределы области видимости, система освобождает связанную с ним память. Например, в программе 4.17 система освобождает память, выделенную объектам t и x класса Complex, после цикла for так же, как и память, выделенную переменной r типа float. В общем, класс Complex используется подобно встроенным типам данных, т.е. он относится к типам данных первого класса.
Программа 4.18. Интерфейс АТД первого класса для комплексных чисел
Этот интерфейс для комплексных чисел дает возможность реализациям создавать объекты типа Complex (инициализированные двумя значениями типа float), обращаться к вещественной и мнимой частям и использовать операцию *=. Хотя это и не указано явно, стандартные системные механизмы, действующие для всех классов, позволяют использовать объекты класса Complex в операторах присваивания, а также в качестве аргументов и возвращаемых значений функций.
class Complex
{
private:
// Программный код, зависящий от реализации
public:
Complex(float, float);
float Re() const;
float Im() const;
Complex& operator*=(Complex&);
};
Программа 4.19. АТД первого класса для комплексных чисел
Этот код реализует АТД, определенный в программе 4.18. Для представления вещественной и мнимой частей комплексного числа используются числа типа float. Это тип данных первого класса, так как в представлении данных отсутствуют указатели. Когда объект класса Complex применяется либо в операторе присваивания, либо в аргументе функции, либо как возвращаемое значение, система создает его копию, размещая в памяти новый объект и копируя данные - в точности как для встроенных типов данных.
Перегруженная операция << в текущей реализации не форматирует выходные данные (см. упр. 4.70).
#include <iostream.h>
class Complex
{
private:
float re, im;
public:
Complex(float x, float y)
{ re = x; im = y; }
float Re() const
{ return re; }
float Im() const
{ return im; }
Complex& operator*=(const Complex& rhs)
{ float t = Re();
re = Re()*rhs.Re() - Im()*rhs.Im();
im = t*rhs.Im() + Im()*rhs.Re();
return *this;
}
};
ostream& operator<<(ostream& t, const Complex& c)
{ t << c.Re() << " " << c.Im(); return t; }
На самом деле в языке C++ к типам данных первого класса относится любой класс, если ни один из его данных-членов не является указателем. При копировании объекта копируется каждый его член; при присваивании объекту значения перезаписывается каждый его член; когда объект выходит за пределы области видимости, занимаемая им память освобождается. В системе существуют стандартные механизмы для каждой из упомянутых ситуаций: в каждом классе имеются стандартные конструктор копирования, операция присваивания и деструктор.
Однако если некоторые данные-члены являются указателями, то эффект выполнения этих стандартных функций окажется совершенно иным. В операции присваивания стандартный конструктор копирования создает копию указателей, но действительно ли это то, что нам требуется? Это важный вопрос семантики копирования, на который необходимо ответить при проектировании любого АТД. Или, если говорить более широко, при разработке программного обеспечения используются АТД вопрос управления памятью является решающим. Сейчас мы рассмотрим пример, который поможет осветить эти вопросы более детально.
Программа 4.20 является примером клиентской программы, которая оперирует с очередями FIFO как с типами данных первого класса. Она моделирует процесс поступления и обслуживания клиентов в совокупности M очередей. На рис. 4.13 показан пример выходных данных этой программы. С помощью данной программы мы покажем, как механизм типов данных первого класса позволяет работать с таким высокоуровневым объектом, как очередь - подобные программы можно использовать для проверки различных методов организации очереди по обслуживанию клиентов и т.п.
Программа 4.20. Клиентская программа, имитирующая обслуживание с очередями
Данная клиентская программа моделирует ситуацию, при которой клиенты, ожидающие обслуживания, случайным образом помещаются в одну из M очередей обслуживания, затем, опять-таки случайным образом, выбирается очередь (возможно, та же) и, если она не пуста, выполняется обслуживание (клиент удаляется из очереди). После выполнения любой из этих операций выводятся номер добавленного клиента, номер обслуженного клиента и содержимое очередей.
Здесь неявно предполагается, что класс QUEUE принадлежит к типу данных первого класса. Эта программа не будет корректно работать с реализациями, предоставленными в программах 4.14 и 4.15, из-за неправильной семантики копирования во внутреннем цикле for.
Конструктор копирования из реализации АТД очереди в программе 4.22 исправляет этот дефект. Во внутреннем цикле for этой реализации каждый раз создается копия соответствующей очереди q, а деструктор позволяет системе освободить память, занятую копиями.
#include <iostream.h>
#include <stdlib.h>
#include "QUEUE.cxx"
static const int M = 4;
int main(int argc, char *argv[])
{ int N = atoi(argv[1]);
QUEUE<int> queues[M];
for (int i = 0; i < N; i++, cout << endl)
{ int in = rand() % M, out = rand() % M;
queues[in].put(i);
cout << i << " поступил ";
if (!queues[out].empty())
cout << queues[out].get() << " обслужен";
cout << endl;
for (int k = 0; k < M; k++, cout << endl)
{
QUEUE<int> q = queues[k];
cout << k << ": ";
while (!q.empty())
cout << q.get() << " ";
}
}
}
Предположим, что используется рассмотренная ранее реализация очереди на базе связного списка из программы 4.14. Когда выполняется операция p = q, где p и q являются объектами класса QUEUE, система выделяет память для нового объекта и копирует в новый объект значения, относящиеся к объекту q. Но это указатели head и tail - сам связный список не копируется! Если впоследствии связный список, относящийся к объекту p, изменяется, тем самым изменяется и связный список, относящийся к объекту q. Безусловно, программа 4.20 не рассчитана на такое поведение. Если использовать объект класса QUEUE как аргумент функции, процесс будет выглядеть так же. В случае встроенных типов данных мы ожидаем, что внутри функции будет свой собственный объект, который можно использовать по своему усмотрению. Это ожидание означает, что в случае структуры данных с указателями требуется создание копии. Однако система не знает, как это сделать - именно мы должны предоставить необходимый код. То же самое справедливо и для возвращаемых значений функций.
Здесь приведена заключительная часть выходных данных программы 4.20 для вызова из командной строки с аргументом 8 0. Показано содержимое очередей после указанных операций:случайным образом выбирается очередь, и в нее заносится следующий элемент; затем еще раз выбирается очередь (также случайно) и, если она не пуста, из нее извлекается элемент.
Еще хуже обстоят дела, когда объект класса QUEUE выходит за пределы видимости: система освобождает память, относящуюся к указателям, но не всю память, занимаемую собственно связным списком. Действительно, как только указатели прекращают свое существование, исчезает возможность доступа к данной области памяти. Вот вам пример утечки памяти (memory leak) - серьезной проблемы, всегда требующей особого внимания при написании программы, которая имеет дело с распределением памяти.
В языке C++ существуют специальные механизмы, которые упрощают создание классов, имеющих корректную семантику копирования и предотвращающих утечки памяти. Для этого необходимо написать следующие функции-члены:
- Конструктор копирования - для создания нового объекта, который является копией данного объекта.
- Перегруженную операцию присваивания - чтобы объект мог присутствовать в левой части оператора присваивания.
- Деструктор - для освобождения памяти, выделенной под объект во время его создании.
Когда системе необходимо выполнить указанные операции, она использует эти функции-члены. Если таких функций в классе нет, система обращается к стандартным функциям. Они работают так, как это описано для класса Complex, однако ведут к неверной семантике копирования и утечкам памяти, если какие-нибудь данные-члены являются указателями. Программа 4.21 - интерфейс очереди FIFO, в который включены три перечисленных функции. Подобно конструкторам, они имеют отличительные сигнатуры, в которые входит имя класса.
Когда при создании объекту присваивается начальное значение, либо объект передается в качестве параметра или возвращается из функции, система автоматически вызывает конструктор копирования QUEUE(const QUEUE&). Для выполнения операции = вызывается операция присваивания QUEUE& operator=(const QUEUE&), которая и присваивает значение одной очереди другой. Деструктор ~QUEUE() вызывается в том случае, когда необходимо освободить память, выделенную под какую-либо очередь. Если в программе присутствует объявление без установки начального значения, наподобие QUEUE<int> q;, то для создания объекта q система использует конструктор QUEUE(). Но если объект при объявлении инициализируется, наподобие QUEUE<int> q = p (или эквивалентной формы QUEUE<int> q(p)), система использует конструктор копирования QUEUE(const QUEUE&). Эта функция должна создавать новую копию объекта p, а не просто еще один указатель на него. Как обычно для ссылочных параметров, ключевое слово const означает намерение не изменять объект p, а использовать его только для доступа к информации.
Чтобы пользовательский класс, данные-члены которого могут содержать указатели, больше походил на встроенный тип данных, в его интерфейс необходимо включить конструктор копирования, перегруженную операцию присваивания и деструктор, как это сделано в данном расширении простого интерфейса очереди FIFO из программы 4.13.
template <class Item>
class QUEUE
{
private:
// Код, зависящий от реализации
public:
QUEUE(int);
QUEUE(const QUEUE&);
QUEUE& operator=(const QUEUE&);
~QUEUE();
int empty() const;
void put(Item);
Item get();
};
Программа 4.22 содержит реализацию конструктора копирования, перегруженной операции присваивания и деструктора для реализации очереди на базе связного списка из программы 4.14. Деструктор проходит по всей очереди и с помощью операции delete освобождает память, выделенную под каждый узел. Если клиентская программа присваивает значения некоторого объекта самому себе, то операция присваивания ничего не делает; иначе вызывается деструктор, а затем с помощью put копируется каждый элемент очереди, стоящей справа от знака операции. Конструктор копирования очищает очередь и затем с помощью операции присваивания выполняет копирование.
За счет помещения в класс конструктора копирования, перегруженной операции присваивания и деструктора (как в программе 4.22) любой класс языка C++ можно превратить в АТД первого класса. Такие функции обычно действуют по принципу простого обхода структур данных. Однако эти дополнительные шаги предпринимаются не всегда, поскольку
- часто используется только один экземпляр объекта определенного класса;
- даже при наличии нескольких экземпляров может оказаться необходимым запрет непреднамеренного копирования огромных структур данных.
В общем, теперь мы знаем о возможности создания типов данных первого класса, но мы знаем и о необходимости компромисса между качеством и ценой, которую приходится платить за его реализацию и использование, в особенности когда дело касается большого объема данных.
Приведенные рассуждения также объясняют, почему библиотека языка C++ включает класс string, несмотря на привлекательность низкоуровневой структуры данных типа строки в стиле языка C. C-строки не принадлежат к типам данных первого класса, поскольку по сути это просто указатели. И многие программисты впервые сталкиваются с некорректной семантикой копирования именно при копировании указателя на C-строку, ожидая, что будет скопирована сама строка. В противоположность этому, класс string языка C++ является типом данных первого класса, поэтому при работе с очень длинными строками следует соблюдать особую осторожность.
Программа 4.22. Реализация очереди первого класса на базе связного списка
Можно модернизировать реализацию класса очереди FIFO из программы 4.14, чтобы превратить этот тип данных в "первоклассный". Для этого в класс потребуется добавить приведенные ниже реализации конструктора копирования, перегруженной операции присваивания и деструктора. Эти функции перекрывают функции, используемые по умолчанию, и вызываются, когда необходимо копировать или уничтожать объекты.
Деструктор ~QUEUE() вызывает приватную функцию-член deletelist, которая проходит по всему связному списку, вызывая для каждого узла функцию delete. Таким образом, при освобождении памяти, связанной с указателями, освобождается и вся память, занимаемая объектом.
Если перегруженная операция присваивания вызывается для присваивания объекта самому себе (например, q = q), никакие действия не выполняются. Иначе вызывается функция deletelist, чтобы очистить память, связанную со старой копией объекта (в результате получается пустой список). Затем для каждого элемента списка из правой части операции присваивания вызывается функция put, и таким образом создается копия этого списка. В обоих случаях возвращаемое значение представляет собой ссылку на объект, которому присвоено значение другого объекта.
Конструктор копирования QUEUE(const QUEUE&) очищает список, а затем с помощью перегруженной операции присваивания создает копию аргумента.
private:
void deletelist()
{
for (link t = head; t != 0; head = t)
{ t = head->next; delete head; }
}
public:
QUEUE(const QUEUE& rhs)
{ head = 0; *this = rhs; }
QUEUE& operator=(const QUEUE& rhs)
{
if (this == &rhs) return *this;
deletelist();
link t = rhs.head;
while (t != 0)
{ put(t->item); t = t->next; }
return *this;
}
~QUEUE()
{ deletelist(); }
В качестве другого примера можно изменить программу 4.20 таким образом, чтобы она периодически выводила лишь несколько первых элементов каждой очереди, и можно было бы отслеживать изменения в очередях даже тогда, когда они становятся очень большими. Однако при наличии очень больших очередей производительность программы существенно снижается, поскольку при инициализации локальной переменной в цикле for вызывается конструктор копирования, который создает копию всей очереди, даже если нужно лишь несколько элементов. А в конце каждой итерации цикла память, занимаемая очередью, освобождается деструктором, т.к. она связана с локальной переменной. Для программы 4.20 в ее нынешнем виде, когда выполняется доступ к каждому элементу копии, дополнительные затраты на выделение и освобождение памяти увеличивают время выполнения только на некоторый постоянный коэффициент. Но если требуется доступ лишь к нескольким элементам очереди, такие затраты неприемлемы. В такой ситуации лучше использовать стандартную реализацию операции копировать, которая копирует только указатели, и добавить в этот АТД операции, обеспечивающих доступ к элементам очереди без ее модификации.
Утечка памяти - это трудно выявляемый дефект, который поражает многие большие системы. Хотя освобождение памяти, занятой некоторым объектом, обычно является в принципе несложным делом, на практике очень тяжело следить за всеми выделенными областями памяти. Механизм деструкторов в языке C++ помогает, однако система не может гарантировать, что обход структур данных выполняется так, как задумано. Когда объект прекращает свое существование, его указатели теряются безвозвратно, и любой указатель, не обработанный деструктором, является потенциальным источником утечки памяти. Один из типичных источников - когда в классе вообще забывают определить деструктор - конечно же, стандартный деструктор вряд ли корректно очистит память. Особое внимание этому вопросу необходимо уделить при использовании абстрактных классов, наподобие класса из программы 4.12.
В ряде систем существует автоматическое распределение памяти - в таких случаях система самостоятельно определяет, какая область памяти больше не используется программами, после чего освобождает ее. Ни одно из этих решений не является полностью приемлемым. Одни полагают, что распределение памяти - слишком важное дело, чтобы поручать его системе; другие же считают, что это слишком важное дело, чтобы его можно было поручать программистам.
Список вопросов, которые могут возникнуть при рассмотрении реализаций АТД, будет очень длинным даже в случае таких простых АТД, как те, которые рассматриваются в настоящей лекции. Нужна ли возможность хранения в одной очереди объектов разных типов? Требуется ли нам в одной клиентской программе использовать разные реализации для очередей одного и того же типа, если известны различия в их производительности? Следует ли включать в интерфейс информацию об эффективности реализаций? Какую форму должна иметь эта информация? Подобные вопросы показывают, насколько важно уметь разбираться в основных характеристиках алгоритмов и структур данных и понимать, каким образом клиентские программы могут эффективно их использовать. В некотором смысле именно это и является темой данной книги. Хотя полные реализации часто представляют собой упражнения по технике программирования, а не по проектированию алгоритмов, мы все же стараемся не забывать об этих существенных вопросах, чтобы разработанные алгоритмы и структуры данных могли послужить фундаментом для создания инструментальных программных средств в самых разнообразных приложениях (см. раздел ссылок).
Упражнения
- 4.63. Перегрузите операции + и += для работы с комплексными числами (программы 4.18 и 4.19).
- 4.64. Преобразуйте АТД отношения эквивалентности (из раздела 4.5) в тип данных первого класса.
- 4.65. Создайте АТД первого класса для использования в программах, оперирующих с игральными картами.
-
4.66. Используя АТД из упражнения 4.65, напишите программу, которая опытным
путем определяет вероятность раздачи различных наборов карт при игре в покер.
-
4.67. Разработайте реализацию для АТД комплексных чисел на базе представления комплексных чисел в полярных координатах (т.е. в формате
 ).
).
-
4.68. Воспользуйтесь тождеством
 для доказательства того, что
для доказательства того, что 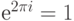 , а N комплексных корней N-ой степени из единицы равны
, а N комплексных корней N-ой степени из единицы равны
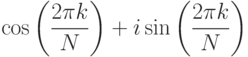
для к = 0, 1, ... , N - 1.
- 4.69. Перечислите корни N-ой степени из единицы для значений N от 2 до 8.
- 4.70. Используя операции precision и setw из файла iostream.h, создайте реализацию перегруженной операции << для программы 4.19, которая выдаст выходные данные, приведенные на рис. 4.12 рис. 4.12 для программы 4.17.
- 4.71. Опишите точно, что произойдет в результате запуска программы 4.20 моделирования обслуживания с очередями, если использовать простую реализацию вроде программы 4.14 или 4.15.
- 4.72. Разработайте реализацию описанного в тексте АТД первого класса для очереди FIFO (программа 4.21), в которой в качестве базовой структуры данных используется массив.
- 4.73. Напишите интерфейс АТД первого класса для стека.
- 4.74. Разработайте реализацию АТД первого класса для стека магазинного типа из упражнения 4.73, в которой в качестве базовой структуры данных используется массив.
- 4.75. Разработайте реализацию АТД первого класса для стека магазинного типа из упражнения 4.73, в которой в качестве базовой структуры данных используется связный список.
- 4.76. Используя приведенные ранее АТД первого класса для комплексных чисел (программы 4.18 и 4.19), измените программу вычисления постфиксных выражений из раздела 4.3 таким образом, чтобы она вычисляла постфиксные выражения, состоящие из комплексных чисел с целыми коэффициентами. Для простоты считайте, что все комплексные числа имеют ненулевые целые коэффициенты как для вещественной, так и для мнимой частей, и записываются без пробелов. Например, для исходного выражения
1+2i0+1i+1-2i*3+4i+
программа должна вывести результат 8+4i.
- 4.77. Выполните математический анализ процесса моделирования обслуживания с очередями в программе 4.20, чтобы определить (как функцию аргументов N и M) вероятность того, что очередь, выбранная для N-ой операции get, будет пустой, а также ожидаемое количество элементов в этих очередях после N итераций цикла for.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |