Комбинаторные вычисления
Введение
Комбинаторная математика является старой дисциплиной. Она получила свое наименование в 1666 г. от Лейбница в его "Dissertation de Arte Combinatori". Комбинаторные алгоритмы с их акцентом на разработку, анализ и реализацию практических алгоритмов являются продуктом века вычислительных машин.
Предмет теории комбинаторных алгоритмов - вычисления на дискретных математических структурах. Это новое направление исследований. Лишь в последние несколько лет из наборов искусных приемов и разрозненных алгоритмов сформировалась система знаний о разработке, реализации и анализе алгоритмов.
Комбинаторные вычисления находятся в таком же отношении к комбинаторной математике (дискретной, конечной математике), как численные методы анализа - к анализу. Комбинаторные вычисления развиваются в следующем направлении:
- интенсивно изобретаются новые алгоритмы;
- происходит быстрый прогресс (главным образом в математическом плане) в понимании алгоритмов, их разработки и анализа;
- происходит переход от изучения отдельных алгоритмов к исследованию свойств, присущих классам алгоритмов.
В отличие от некоторых других разделов математики, комбинаторные вычисления не имеют "ядра", то есть некоторого количества "фундаментальных теорем", составляющих суть предмета, из которых выводится большинство результатов. Сначала может показаться, что в целом эта область состоит из наборов специальных методов и хитрых приемов. Однако после того, как было исследовано достаточно много комбинаторных алгоритмов, стали вырисовываться некоторые общие принципы. Именно эти принципы делают комбинаторные вычисления связной областью знаний и позволяют изложить ее в систематизированном виде.
Проблема представления: коды, сохраняющие разности
Чрезвычайно важной проблемой в комбинаторных вычислениях является задача эффективного представления объектов, подлежащих обработке. Она возникает потому, что обычно имеется много возможных способов представления сложных объектов более простыми структурами, которые можно заложить в языки программирования, но не все такие представления в одинаковой степени эффективны с точки зрения времени и памяти. Более того, идеальное представление зависит от вида производимых операций.
Приведем примеры, в которых задаются весьма специфические операции над целыми. Целые определяются как данные простейшего типа почти во всех вычислительных устройствах и языках программирования. Таким образом, проблема представления, как правило, не возникает. Имеющееся представление почти всегда наилучшее. Однако существуют некоторые заслуживающие внимания исключения, когда выгодно или даже необходимо использовать представление целых в вычислительном устройстве иным способом. Эти исключения появляются в следующих случаях:
- Необходимы целые, больше имеющихся непосредственно в аппаратном оборудовании.
- Необходимы только небольшие целые, и требуется сэкономить память, упаковывая их по несколько в одну ячейку.
- Действия с целыми производятся не общепринятыми арифметическими операциями.
- Целые используются для представления других типов объектов, и необходимо иметь возможность легко обращать целое в соответствующий ему объект и обратно.
Проблемы кодов, сохраняющих разности, касаются случаев 2 и 3.
В задачах распознавания образов и классификации для решения вопроса, будут ли
два объекта  эквивалентными,стандартной является следующая процедура. представляются векторами признаков
эквивалентными,стандартной является следующая процедура. представляются векторами признаков 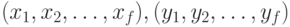 соответственно, где каждая компонента означает признак объекта, выраженный целым значением. Считается, что эквиваленты тогда и только тогда, если
соответственно, где каждая компонента означает признак объекта, выраженный целым значением. Считается, что эквиваленты тогда и только тогда, если

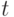 — целое, называемое порогом.
— целое, называемое порогом.Классы алгоритмов
Одной из причин быстрого прогресса комбинаторных вычислений является усиление внимания к исследованию классов алгоритмов в противоположность изучению отдельных из них. Для того чтобы утверждать, например, что "все алгоритмы, предназначенные для выполнения того-то и того-то, должны обладать такими-то и такими-то свойствами" или "не существует алгоритма, удовлетворяющего тому-то и тому-то", необходимо иметь дело с четко определенным классом алгоритмов. Именно при таком определении становится возможным говорить, что данный алгоритм является оптимальным по отношению к некоторому свойству, если он работает по крайней мере так же хорошо (относительно этого свойства), как любой другой алгоритм из рассматриваемого класса.
Как можно строго определить, возможно, бесконечный, класс алгоритмов? Исследуем этот вопрос на примере задачи о фальшивой монете. Рассматриваемый в этом примере класс алгоритмов порождает более обширный и более важный класс алгоритмов - так называемые деревья решений.
Задача. Имеется  монет, о которых известно, что
монет, о которых известно, что 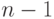 из них являются настоящими и не более чем одна монета, фальшивая (легче или тяжелее остальных монет). Дополнительно к группе из сомнительных монет дается еще одна монета, причем заведомо известно, что она настоящая. Имеются также весы, с помощью которых можно сравнить общий вес любых
из них являются настоящими и не более чем одна монета, фальшивая (легче или тяжелее остальных монет). Дополнительно к группе из сомнительных монет дается еще одна монета, причем заведомо известно, что она настоящая. Имеются также весы, с помощью которых можно сравнить общий вес любых  монет с общим
весом любых других монет и тем самым установить, имеют ли две группы
по монет одинаковый вес либо одна из групп легче другой. Задача состоит в том, чтобы найти фальшивую монету, если она есть, за наименьшее число взвешиваний, или
сравнений.
монет с общим
весом любых других монет и тем самым установить, имеют ли две группы
по монет одинаковый вес либо одна из групп легче другой. Задача состоит в том, чтобы найти фальшивую монету, если она есть, за наименьшее число взвешиваний, или
сравнений.
Решение Пусть сомнительные монеты занумерованы числами  . Монете, о которой известно, что она настоящая, поставим в соответствие номер 0.
Пусть
. Монете, о которой известно, что она настоящая, поставим в соответствие номер 0.
Пусть  - множество монет. Если
- множество монет. Если 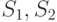 — непересекающиеся непустые подмножества множества
— непересекающиеся непустые подмножества множества  , то через
, то через 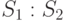 обозначим операцию сравнения весов множества . При сравнении возможны три исхода, которые обозначим следующим образом:
обозначим операцию сравнения весов множества . При сравнении возможны три исхода, которые обозначим следующим образом:  в зависимости от того, является ли вес
в зависимости от того, является ли вес  меньшим, равным или большим веса
меньшим, равным или большим веса 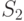 .
.
Рассматриваемые алгоритмы можно представить в форме дерева решений.
Корень дерева на рисунке изображен полой окружностью и помечен
отношением  . Это означает, что алгоритм начинает работу
сравнением весов монет с номерами 1 и 2. Три исходящие из корня ветви ведут к поддеревьям,
определяющим продолжение работы алгоритма после каждого из трех возможных
исходов первого сравнения. Окружности, залитые черной краской, называются
листьями дерева и означают, что работа алгоритма заканчивается. Метки
соответствуют исходам: "1л" - монета 1 легкая, "1т"
- монета 1 тяжелая, "н" - все монеты настоящие. Непомеченная вершина дерева
означает, что при наших предположениях этот случай возникнуть не может.
. Это означает, что алгоритм начинает работу
сравнением весов монет с номерами 1 и 2. Три исходящие из корня ветви ведут к поддеревьям,
определяющим продолжение работы алгоритма после каждого из трех возможных
исходов первого сравнения. Окружности, залитые черной краской, называются
листьями дерева и означают, что работа алгоритма заканчивается. Метки
соответствуют исходам: "1л" - монета 1 легкая, "1т"
- монета 1 тяжелая, "н" - все монеты настоящие. Непомеченная вершина дерева
означает, что при наших предположениях этот случай возникнуть не может.
Алгоритм, приведенный на рис. 1.1, требует двух сравнений в одних случаях и трех - в других. Скажем, что он требует "трех сравнений в худшем случае". Обычно важно знать, сколько работы требует алгоритм в среднем, однако для этого требуется задать вероятности различных исходов. Если предположим, что все восемь исходов 1л, 1т, 2л, 2т, 3л, 3т, 4л, 4т, - равновероятны, то тогда этот алгоритм требует в среднем 7/3 сравнений.
На одну чашку весов можем положить больше одной монеты. Например, можно начать сравнения, положив на одну чашку весов монеты 1 и 2, а на другую - монеты 3 и 4 (рис. 1.2).
Если посчастливится, задачу можно решить за одно сравнение - это может
произойти, когда все монеты настоящие. Независимо от того, как дополняется это дерево
решений, в худшем случае задача все равно потребует тех же трех сравнений, поскольку
единственное тернарное решение не может идентифицировать один из четырех
исходов, которые возможны на ветви, помеченной символом "  ", так же как и один из четырех исходов на ветви, помеченной символом "
", так же как и один из четырех исходов на ветви, помеченной символом " 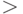 ". К тому же, независимо от того, как дополняется это дерево решений, оно потребует в
среднем по крайней мере 7/3 сравнений, и в этом случае оно не лучше, чем дерево на
рис.1.1.
". К тому же, независимо от того, как дополняется это дерево решений, оно потребует в
среднем по крайней мере 7/3 сравнений, и в этом случае оно не лучше, чем дерево на
рис.1.1.
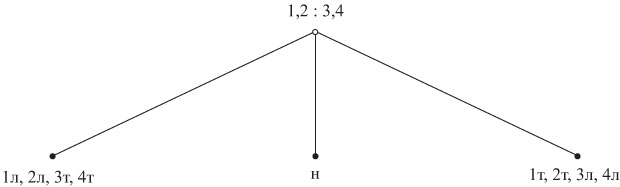
Используя монету 0, о которой известно, что она настоящая, можно получить приведенное на рис. 1.3 дерево решений (полное двухъярусное тернарное дерево), которое и в худшем, и в среднем случае требует двух сравнений.
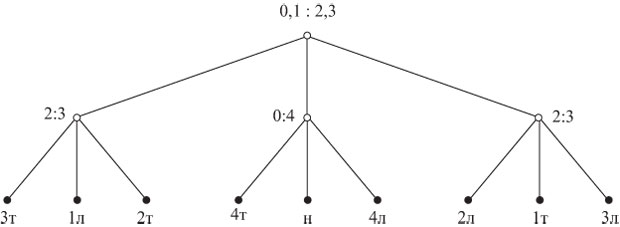
Рассматриваемый класс алгоритмов решения задачи о фальшивой монете есть множество тернарных деревьев решений (примеры на рис.1.1, рис.1.2, рис.1.3), обладающих следующими свойствами:
- каждый узел помечен сравнением
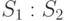 , где и - непересекающиеся непустые подмножества множества
, где и - непересекающиеся непустые подмножества множества  всех монет;
всех монет; - каждый лист либо не помечен, что соответствует невозможному исходу в предположении существования не более чем одной фальшивой монеты, либо помечен одним из исходов iл, iT, н, означающим соответственно, что все монеты настоящие. Четко определив подлежащий дальнейшему рассмотрению класс алгоритмов, можно исследовать свойства, которыми должно обладать каждое дерево из этого класса, и определить, как найти алгоритмы, являющиеся в некотором смысле оптимальными. Решим эту проблему в начале для четырех монет, а затем перейдем к общему случаю.
Поскольку в задаче о четырех монетах требуется различить девять возможных
исходов, любое дерево решений для этой задачи должно иметь, по крайней мере,
девять листьев и, следовательно, не менее двух ярусов. Поэтому дерево на
рис.1.3 является оптимальным и для худшего случая, и для среднего. Существуют ли
другие оптимальные деревья? Для ответа на этот вопрос нужно рассмотреть множество
всех деревьев решений для задачи о четырех монетах. Попытаемся исключить из
дальнейшего рассмотрения какую-либо часть этого множества. Прежде всего видно,
что путем любой перестановки множества 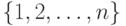 сомнительных монет из одного дерева, приведенного на рис.1.3, можно получить другие оптимальные деревья.
Все они будут изоморфны дереву на рис.1.3. Исходя из этого, уточним постановку
задачи и будем интересоваться попарно неизоморфными деревьями.
сомнительных монет из одного дерева, приведенного на рис.1.3, можно получить другие оптимальные деревья.
Все они будут изоморфны дереву на рис.1.3. Исходя из этого, уточним постановку
задачи и будем интересоваться попарно неизоморфными деревьями.