|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Опубликован: 09.11.2009 | Доступ: свободный | Студентов: 4080 / 1033 | Оценка: 4.66 / 4.45 | Длительность: 54:13:00
Темы: Математика, Экономика
Специальности: Экономист
Теги:
Лекция 12:
Статистика интервальных данных
12.5. Интервальный дискриминантный анализ
Перейдем к задачам классификации в статистике интервальных данных. Как известно [ [ 12.38 ] ], важная их часть - задачи дискриминации (диагностики, распознавания образов с учителем). В этих задачах заданы классы (полностью или частично, с помощью обучающих выборок), и необходимо принять решение - к какому этих классов отнести вновь поступающий объект.
В линейном дискриминантном анализе правило принятия решений основано на линейной функции 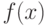 от распознаваемого вектора
от распознаваемого вектора 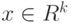 . Рассмотрим для простоты случай двух классов. Правило принятия решений определяется константой
. Рассмотрим для простоты случай двух классов. Правило принятия решений определяется константой 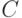 - при
- при 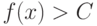 распознаваемый объект относится к первому классу, при
распознаваемый объект относится к первому классу, при 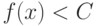 - ко второму.
- ко второму.
В первоначальной вероятностной модели Р.Фишера предполагается, что классы заданы обучающими выборками объемов 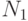 и
и 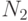 соответственно из многомерных нормальных распределений с разными математическими ожиданиями, но одинаковыми ковариационными матрицами. В соответствии с леммой Неймана-Пирсона, дающей правило принятия решений при поверке статистических гипотез, дискриминантная функция является линейной. Для ее практического использования теоретические характеристики распределения необходимо заменить на выборочные. Тогда дискриминантная функция приобретает следующий вид
соответственно из многомерных нормальных распределений с разными математическими ожиданиями, но одинаковыми ковариационными матрицами. В соответствии с леммой Неймана-Пирсона, дающей правило принятия решений при поверке статистических гипотез, дискриминантная функция является линейной. Для ее практического использования теоретические характеристики распределения необходимо заменить на выборочные. Тогда дискриминантная функция приобретает следующий вид
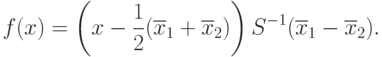
Здесь  - выборочное среднее арифметическое по первой выборке
- выборочное среднее арифметическое по первой выборке 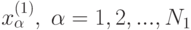 а
а 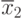 - выборочное среднее арифметическое по второй выборке
- выборочное среднее арифметическое по второй выборке 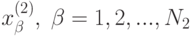 . В роли
. В роли  может выступать любая состоятельная оценка общей для выборок ковариационной матрицы. Обычно используют следующую оценку, естественным образом сконструированную на основе выборочных ковариационных матриц:
может выступать любая состоятельная оценка общей для выборок ковариационной матрицы. Обычно используют следующую оценку, естественным образом сконструированную на основе выборочных ковариационных матриц:
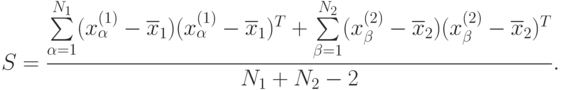
В соответствии с подходом статистики интервальных данных считаем, что специалисту по анализу данных известны лишь значения с погрешностями
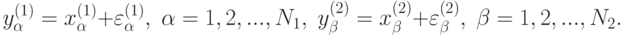
Таким образом, вместо статистик делает выводы на основе искаженной линейной дискриминантной функции  , в которой коэффициенты рассчитаны не по исходным данным
, в которой коэффициенты рассчитаны не по исходным данным 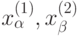 , а по искаженным погрешностями значениям
, а по искаженным погрешностями значениям 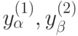 .
.
Это - модель с искаженными параметрами дискриминантной функции. Следующая модель - такая, в которой распознаваемый вектор  также известен с ошибкой. Далее, константа может появляться в модели различными способами: задаваться априори абсолютно точно; задаваться с какой-то ошибкой, не связанной с ошибками, вызванными конечностью обучающих выборок; рассчитываться по обучающим выборкам, например, с целью уравнять ошибки классификации, т.е. провести плоскость дискриминации через середину отрезка, соединяющего центры классов. Итак - целый спектр моделей ошибок.
также известен с ошибкой. Далее, константа может появляться в модели различными способами: задаваться априори абсолютно точно; задаваться с какой-то ошибкой, не связанной с ошибками, вызванными конечностью обучающих выборок; рассчитываться по обучающим выборкам, например, с целью уравнять ошибки классификации, т.е. провести плоскость дискриминации через середину отрезка, соединяющего центры классов. Итак - целый спектр моделей ошибок.
На какие статистические процедуры влияют ошибки в исходных данных? Здесь тоже много постановок. Можно изучать влияние погрешностей измерений на значения дискриминантной функции  , например, в той точке, куда попадает вновь поступающий объект . Очевидно, случайная величина имеет некоторое распределение, определяемое распределениями обучающих выборок. Выше описана модель Р.Фишера с нормально распределенными совокупностями. Однако реальные данные, как правило, не подчиняются нормальному распределению [
[
12.38
]
]. Тем не менее линейный статистический анализ имеет смысл и для распределений, не являющихся нормальными (при этом вместо свойств многомерного нормального распределения приходится опираться на многомерную Центральную предельную теорему и теорему о наследовании сходимости [
[
1.15
]
]).
В частности, приравняв метрологическую ошибку, вызванную погрешностями исходных данных, и статистическую ошибку, получим условие, определяющее рациональность объемов выборок. Здесь два объема выборок, а не один, как в большинстве рассмотренных постановок статистики интервальных данных. С подобным мы сталкивались ранее при рассмотрении двухвыборочного критерия Смирнова.
, например, в той точке, куда попадает вновь поступающий объект . Очевидно, случайная величина имеет некоторое распределение, определяемое распределениями обучающих выборок. Выше описана модель Р.Фишера с нормально распределенными совокупностями. Однако реальные данные, как правило, не подчиняются нормальному распределению [
[
12.38
]
]. Тем не менее линейный статистический анализ имеет смысл и для распределений, не являющихся нормальными (при этом вместо свойств многомерного нормального распределения приходится опираться на многомерную Центральную предельную теорему и теорему о наследовании сходимости [
[
1.15
]
]).
В частности, приравняв метрологическую ошибку, вызванную погрешностями исходных данных, и статистическую ошибку, получим условие, определяющее рациональность объемов выборок. Здесь два объема выборок, а не один, как в большинстве рассмотренных постановок статистики интервальных данных. С подобным мы сталкивались ранее при рассмотрении двухвыборочного критерия Смирнова.
Естественно изучать влияние погрешностей исходных данных не при конкретном , а для правила принятия решений в целом. Может представлять интерес изучение характеристик этого правила по всем или по какой-либо области возможных значений . Более интересно рассмотреть показатель качества классификации, связанный с пересчетом на модель линейного дискриминантного анализа [
[
12.38
]
].
Математический аппарат изучения перечисленных моделей развит выше в предыдущих пунктах настоящей главы. Некоторые результаты приведены в [ [ 2.18 ] ]. Из-за большого объема выкладок ограничимся приведенными здесь замечаниями.
Анастасия Маркова