|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Опубликован: 09.11.2009 | Доступ: свободный | Студентов: 4079 / 1033 | Оценка: 4.66 / 4.45 | Длительность: 54:13:00
Темы: Математика, Экономика
Специальности: Экономист
Теги:
Лекция 12:
Статистика интервальных данных
Для нахождения рационального объема выборки необходимо сделать следующее.
Этап 1. Выразить зависимость размеров и меры области рассеивания 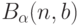 от числа опытов
от числа опытов  (см. выше).
(см. выше).
Этап 2. Ввести меру неопределенности и записать соотношение между статистической и интервальной неопределенностями.
Этап 3. По результатам этапов 1 и 2 получить выражение для рационального объема выборки.
Для выполнения этапа 1 определим область рассеивания следующим образом. Пусть доверительным множеством 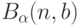 является
является  -мерный куб со сторонами длиною
-мерный куб со сторонами длиною  , для которого
, для которого
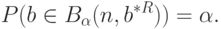
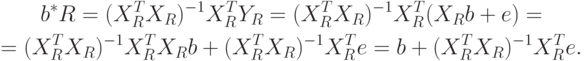
Как известно, если элементы матрицы 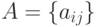 - случайные, т.е.
- случайные, т.е.  - случайная матрица, то ее математическим ожиданием является матрица, составленная из математических ожиданий ее элементов, т.е.
- случайная матрица, то ее математическим ожиданием является матрица, составленная из математических ожиданий ее элементов, т.е. 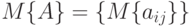 .
.
Утверждение 1. Пусть 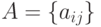 и
и  - случайные матрицы порядка
- случайные матрицы порядка 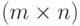 и
и 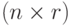 соответственно, причем любая пара их элементов
соответственно, причем любая пара их элементов 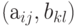 состоит из независимых случайных величин. Тогда математическое ожидание произведения матриц равно произведению математических ожиданий сомножителей, т.е.
состоит из независимых случайных величин. Тогда математическое ожидание произведения матриц равно произведению математических ожиданий сомножителей, т.е. 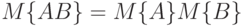 .
.
Доказательство. На основании определения математического ожидания матрицы заключаем, что
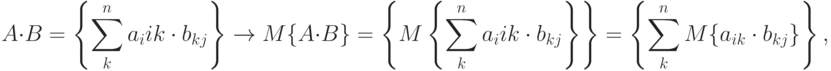
 независимы, то
независимы, то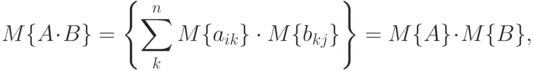
Утверждение 2. Пусть и - случайные матрицы порядка 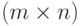 и
и 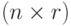 соответственно. Тогда математическое ожидание суммы матриц равно сумме математических ожиданий слагаемых, т.е.
соответственно. Тогда математическое ожидание суммы матриц равно сумме математических ожиданий слагаемых, т.е. 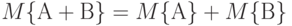 .
.
Доказательство. На основании определения математического ожидания матрицы заключаем, что
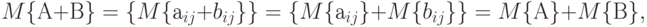
Найдем математическое ожидание и ковариационную матрицу вектора 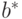 с помощью утверждений 1, 2 и выражения для
с помощью утверждений 1, 2 и выражения для 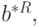 приведенного выше. Имеем
приведенного выше. Имеем
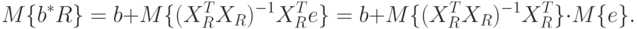
Но так как  , то
, то 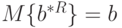 . Это означает, что оценка МНК является несмещенной.
. Это означает, что оценка МНК является несмещенной.
Найдем ковариационную матрицу:
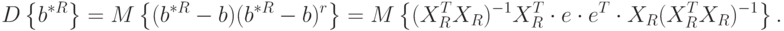
Можно доказать, что
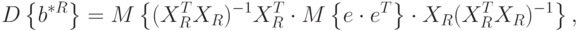
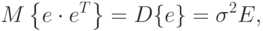

Как выяснено ранее, для достаточно большого количества опытов выполняется приближенное равенство
 |
( 51) |
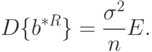
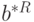 . Из выражения для , приведенного выше, и асимптотического соотношения (51) следует, что
. Из выражения для , приведенного выше, и асимптотического соотношения (51) следует, что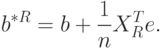
Можно утверждать, что вектор имеет асимптотически нормальное распределение, т.е.
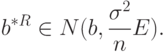
Тогда совместная функция плотности распределения вероятностей случайных величин 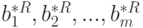 будет иметь вид:
будет иметь вид:
![f(b^{*R})=\frac{1}{(2\pi)^{m/2}\cdot(\det C)^{1/2}}\cdot\exp[-\frac12(b^{*R}-b)^T\cdot C^{-1}\cdot(b^{*R}-b)],](/sites/default/files/tex_cache/a5782360672c8452ec70f11e04c640e2.png) |
( 52) |
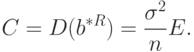
Тогда справедливы соотношения

Подставим в формулу (52), получим
![\begin{aligned}
&f(b^{*R})=\frac{1}{(2\pi)^{m/2}\cdot(\sigma^2/n)^{m/2}}\cdot\exp[-\frac{n}{2\sigma^2}(b^{*R}-b)^T\cdot C^{-1}\cdot(b^{*R}-b)]= \\
&=\frac{1}{(\sigma\sqrt{2\pi/n})^m}\exp[-\frac{n}{2\sigma^2}(b^{*R}-b)^T\cdot C^{-1}\cdot(b^{*R}-b)]= \\
&=\frac{1}{(\sigma\sqrt{2\pi/n})^m}\exp[-\frac{n}{2\sigma^2}(\beta_1^2+\beta_2^2+...+\beta_m^2)],
\end{aligned}](/sites/default/files/tex_cache/bb46901f3a1c28cffaa3815f3744349b.png)
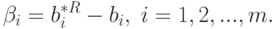
Вычислим асимптотическую вероятность попадания описывающего реальность вектора параметров  в -мерный куб с длиной стороны, равной
в -мерный куб с длиной стороны, равной 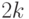 , и с центром .
, и с центром .
![\begin{gathered}
P(-k<\beta_1<k,-k<\beta_2<k,...,-k<\beta_m<k)= \\
=\frac{1}{(\sigma\sqrt{2\pi/n})^m}\{\int\limits_{-k}^k..\int\limits_{-k}^k\exp[-\frac{n}{2\sigma^2}(\beta_1^2+\beta_2^2+...+\beta_m^2)]\cdot d\beta_1...d\beta_m\}= \\
=\frac{1}{(\sigma\sqrt{2\pi/n})^m}\{\int\limits_{-k}^k\exp[-\frac{n}{2\sigma^2}\beta_1^2]d\beta_1...\int\limits_{-k}^k\exp[-\frac{n}{2\sigma^2}\beta_i^2]d\beta_i\}.
\end{gathered}](/sites/default/files/tex_cache/afa49a682a543f46bfa544be1fcea6eb.png)
Сделаем замену
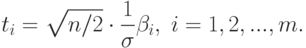
Тогда
![\begin{aligned}
&P=P(-k<\beta_1<k,-k<\bela_2<k,...,-k<\beta_m<k)= \\
&=\frac{(\sigma\sqrt{2/n})^m}{\sigma\sqrt{2\pi/n})^m}[\int\limits_{-T}^T e^{-t^2}dt]^m =
[(1/\sqrt{\pi})\int\limits_{-T}^T e^{-t^2}dt]^m]=[\Phi_0(T)]^m,
\end{aligned}](/sites/default/files/tex_cache/d0206a0a3fc51fc16cb3531e32454600.png)
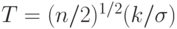 , а
, а 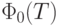 - интеграл Лапласа,
- интеграл Лапласа,
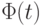 - функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1. Из последнего соотношения получаем
- функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1. Из последнего соотношения получаем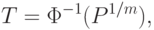
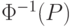 - обратная функция Лапласа. Отсюда следует, что
- обратная функция Лапласа. Отсюда следует, что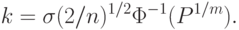 |
( 53) |
Напомним, что доверительная область - это -мерный куб, длина стороны которого равна 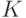 , т.е.
, т.е.

Подставляя  в формулу (53), получим
в формулу (53), получим
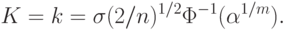 |
( 54) |
Соотношение (54) выражает зависимость размеров доверительной области (т.е. длины ребра куба ) от числа опытов , среднего квадратического отклонения 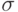 ошибки
ошибки  и доверительной вероятности
и доверительной вероятности  . Это соотношение понадобится для определения рационального объема выборки.
. Это соотношение понадобится для определения рационального объема выборки.
Переходим к этапу 2. Необходимо ввести меру разброса (неопределенности) и установить соотношение между статистической и интервальной (метрологической) неопределенностями в соответствии с ранее сформулированным общим подходом.
Пусть - некоторое измеримое множество точек в -мерном евклидовом пространстве, характеризующее неопределенность задания вектора 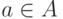 . Тогда необходимо ввести некую меру
. Тогда необходимо ввести некую меру 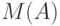 , измеряющую степень неопределенности. Такой мерой может служить -мерный объем
, измеряющую степень неопределенности. Такой мерой может служить -мерный объем 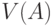 множества (т.е. его мера Лебега или Жордана),
множества (т.е. его мера Лебега или Жордана), 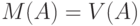 .
.
Пусть 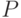 - -мерный параллелепипед, характеризующий интервальную неопределенность. Длины его сторон равны значениям нотн
- -мерный параллелепипед, характеризующий интервальную неопределенность. Длины его сторон равны значениям нотн 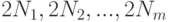 , а центр
, а центр  (точка пересечений диагоналей параллелепипеда) находится в точке . Пусть
(точка пересечений диагоналей параллелепипеда) находится в точке . Пусть 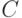 - измеримое множество точек, характеризующее общую неопределенность. В рассматриваемом случае это -мерный параллелепипед, длины сторон которого равны
- измеримое множество точек, характеризующее общую неопределенность. В рассматриваемом случае это -мерный параллелепипед, длины сторон которого равны 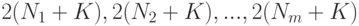 , а центр находится в точке . Тогда
, а центр находится в точке . Тогда
 |
( 55) |
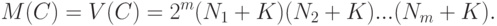 |
( 56) |
Справедливо соотношение (49), согласно которому  , где множество
, где множество 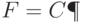 характеризует статистическую неопределенность.
характеризует статистическую неопределенность.
На этапе 3 получаем по результатам этапов 1 и 2 выражение для рационального объема выборки. Найдем то число опытов, при котором статистическая неопределенность составит 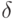 100% от общей неопределенности, т.е. согласно правилу (50)
100% от общей неопределенности, т.е. согласно правилу (50)
 |
( 57) |
 . Подставив (55) и (56) в (57), получим
. Подставив (55) и (56) в (57), получим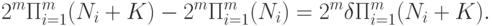
Следовательно, 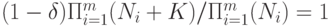 .
.
Преобразуем эту формулу:
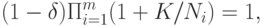

Если статистическая погрешность мала относительно метрологической, т.е. величины 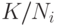 малы, то
малы, то
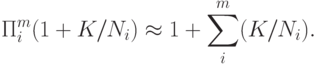
При 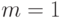 эта формула является точной. Из нее следует, что для дальнейших расчетов можно использовать соотношение
эта формула является точной. Из нее следует, что для дальнейших расчетов можно использовать соотношение

Отсюда нетрудно найти :
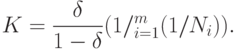 |
( 58) |
Подставив в формулу (58) зависимость 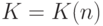 , полученную в формуле (54), находим приближенное (асимптотическое) выражение для рационального объема выборки:
, полученную в формуле (54), находим приближенное (асимптотическое) выражение для рационального объема выборки:

При эта формула также справедлива, более того, является точной.
Переход от произведения к сумме является обоснованным при достаточно малом , т.е. при достаточно малой статистической неопределенности по сравнению с метрологической. В общем случае можно находить и затем рациональный объем выборки тем или иным численным методом.
Пример 1. Представляет интерес определение nрац для случая, когда  , поскольку простейшая линейная регрессия с
, поскольку простейшая линейная регрессия с  широко применяется. В этом случае базовое соотношение имеет вид
широко применяется. В этом случае базовое соотношение имеет вид
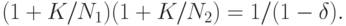
Решая это уравнение относительно , получаем
![K=0.5\{-(N_1 + N_2) + [(N_1 + N_2)^2 + 4 N_1N_2 (\delta/(1 - \delta)]^{1/2}\}.](/sites/default/files/tex_cache/008d91c66bb80aa6d18ed4a6618337f3.png)
Далее, подставив в формулу (54), получим уравнение для рационального объема выборки в случае :
![\sigma(2/n)^{1/2}\Phi^{-1}(\alpha^{1/2})=0.5\{-(N_1+N_2)+[(N_1+N_2)^2+4N_1N_2(\delta/(1-\delta)]^{1/2}\}.](/sites/default/files/tex_cache/51bcf13956d2c41ade7c7daf7783a7c0.png)
Следовательно,
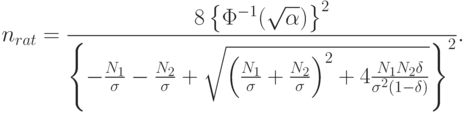
При использовании "принципа уравнивания погрешностей" согласно [
[
1.15
]
] 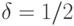 . При доверительной вероятности
. При доверительной вероятности 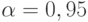 имеем
имеем 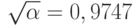 и согласно [
[
2.1
]
]
и согласно [
[
2.1
]
]  . Для этих численных значений
. Для этих численных значений
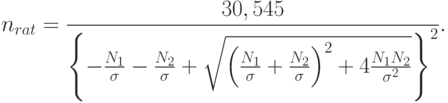
Если  то
то  . Если же
. Если же  то
то 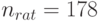 . Если первое из этих чисел превышает обычно используемые объемы выборок, то второе находится в "рабочей зоне" регрессионного анализа.
. Если первое из этих чисел превышает обычно используемые объемы выборок, то второе находится в "рабочей зоне" регрессионного анализа.
Парная регрессия. Наиболее простой и одновременно наиболее широко применяемый частный случай парной регрессии рассмотрим подробнее. Модель имеет вид

Здесь 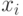 - значения фактора (независимой переменной),
- значения фактора (независимой переменной),  - значения отклика (зависимой переменной),
- значения отклика (зависимой переменной), 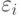 - статистические погрешности,
- статистические погрешности,  - неизвестные параметры, оцениваемые методом наименьших квадратов. Она переходит в модель (используем альтернативную запись линейной модели)
- неизвестные параметры, оцениваемые методом наименьших квадратов. Она переходит в модель (используем альтернативную запись линейной модели)


Естественно принять, что погрешности факторов описываются матрицей

В рассматриваемой модели интервального метода наименьших квадратов
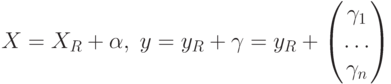
 - наблюдаемые (т.е. известные статистику) значения фактора и отклика,
- наблюдаемые (т.е. известные статистику) значения фактора и отклика,  - истинные значения переменных,
- истинные значения переменных, 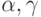 - погрешности измерений переменных. Пусть
- погрешности измерений переменных. Пусть  - оценка метода наименьших квадратов, вычисленная по наблюдаемым значениям переменных,
- оценка метода наименьших квадратов, вычисленная по наблюдаемым значениям переменных, 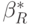 - аналогичная оценка, найденная по истинным значениям. В соответствии с ранее проведенными рассуждениями
- аналогичная оценка, найденная по истинным значениям. В соответствии с ранее проведенными рассуждениями![\beta^*-\beta=[-(X_0^TX_0)^{-1}\Delta(X_0^TX_0)^{-1}X_0^T+(X_0^TX_0)^{-1}\alpha^T]y_0+(X_0^TX_0)^{-1}X_0^T\gamma](/sites/default/files/tex_cache/2cbf4bc91d5a855a25605ba7894e0c31.png) |
( 59) |
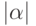 и
и  . В формуле (59) использовано обозначение
. В формуле (59) использовано обозначение 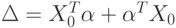 . Вычислим правую часть в (59), выделим главный линейный член и найдем нотну.
. Вычислим правую часть в (59), выделим главный линейный член и найдем нотну.Легко видеть, что
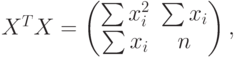 |
( 60) |
где суммирование проводится от 1 до . Для упрощения обозначений в дальнейшем до конца настоящего параграфа не будем указывать эти пределы суммирования. Из (60) вытекает, что
![(X^TX)^{-1}=
\left.
\begin{pmatrix}
n & -\sum x_i \\
-\sum x_i & \sum x_i^2
\end{pmatrix}
\right/
\left[
n\sum x_i^2-\left(\sum x_i\right)^2
\right].](/sites/default/files/tex_cache/215c7d3ff6e33c3a6daf4a3ff904f993.png) |
( 61) |
Легко подсчитать, что
 |
( 62) |
Положим
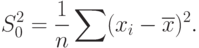
Тогда знаменатель в (61) равен 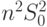 . Из (61) и (62) следует, что
. Из (61) и (62) следует, что
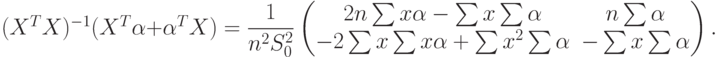 |
( 63) |
Здесь и далее опустим индекс  , по которому проводится суммирование. Это не может привести к недоразумению, поскольку всюду суммирование проводится по индексу в интервале от 1 до . Из (61) и (63) следует, что
, по которому проводится суммирование. Это не может привести к недоразумению, поскольку всюду суммирование проводится по индексу в интервале от 1 до . Из (61) и (63) следует, что
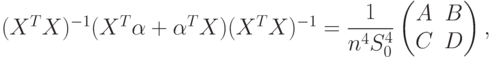 |
( 64) |
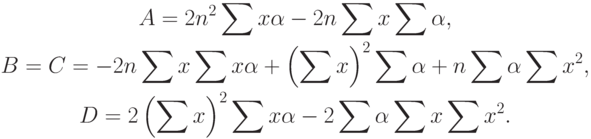
Наконец, вычисляем основной множитель в (59)
 |
( 65) |

Перейдем к вычислению второго члена с в (59). Имеем
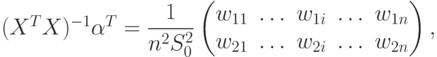 |
( 67) |
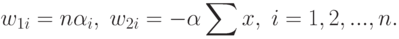
Складывая правые части (65) и (67) и умножая на  , получим окончательный вид члена с в (59):
, получим окончательный вид члена с в (59):
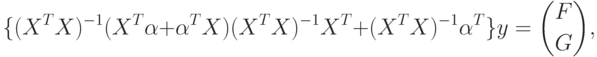 |
( 68) |
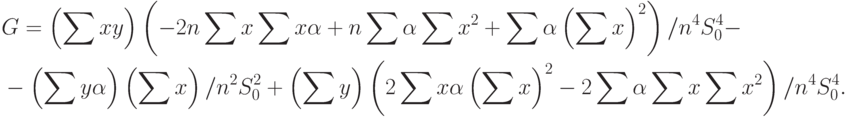
Для вычисления нотны выделим главный линейный член. Сначала найдем частные производные. Имеем
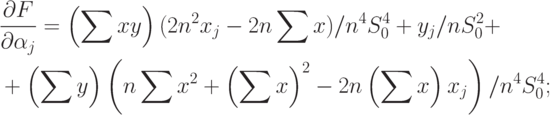 |
( 70) |
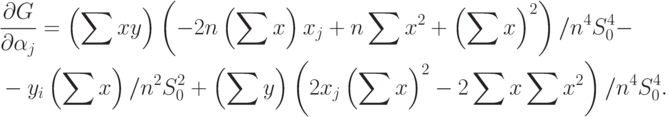
Если ограничения имеют вид
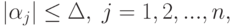
 параметра из-за погрешностей
параметра из-за погрешностей 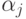 таково:
таково: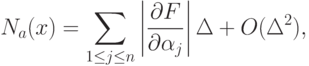
Пример 2. Пусть вектор 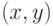 имеет двумерное нормальное распределение с нулевыми математическими ожиданиями, единичными дисперсиями и коэффициентом корреляции
имеет двумерное нормальное распределение с нулевыми математическими ожиданиями, единичными дисперсиями и коэффициентом корреляции  . Тогда
. Тогда
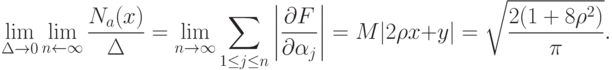 |
( 71) |
При этом
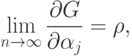 соответствует сдвиг всех в одну сторону, т.е. наличие систематической ошибки при определении
соответствует сдвиг всех в одну сторону, т.е. наличие систематической ошибки при определении  -ов. В то же время согласно (71) значения в асимптотике выбираются по правилу
-ов. В то же время согласно (71) значения в асимптотике выбираются по правилу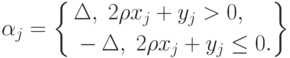
Таким образом, максимальному изменению соответствуют не те , что максимальному изменению . В этом - новое по сравнению с одномерным случаем. В зависимости от вида ограничений на возможные отклонения, в частности, от вида метрики в пространстве параметров, будут "согласовываться" отклонения по отдельным параметрам. Ситуация аналогична той, что возникает в классической математической статистике в связи с оптимальным оцениванием параметров. Если параметр одномерен, то ситуация с оцениванием достаточно прозрачна - есть понятие эффективных оценок, показателем качества оценки является средний квадрат ошибки, а при ее несмещенности - дисперсия. В случае нескольких параметров возникает необходимость соизмерить точность оценивания по разным параметрам. Есть много критериев оптимальности (см., например, [
[
12.21
]
]), но нет признанных правил выбора среди них.
Вернемся к формуле (59). Интересно, что отклонения вектора параметров, вызванные отклонениями значений факторов и отклика 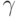 , входят в (59) аддитивно. Хотя
, входят в (59) аддитивно. Хотя
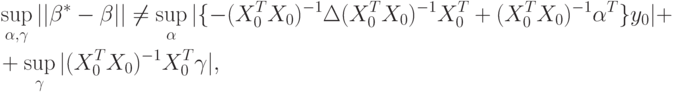
В случае парной регрессии
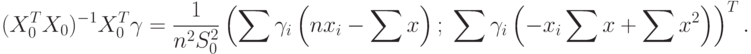 |
( 72) |
Из формул (68), (69) и (72) следует, что
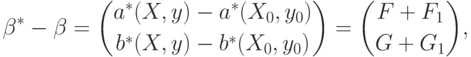
 и
и  определены в (69), а
определены в (69), а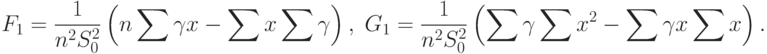
Итак, продемонстрирована возможность применения основных подходов статистики интервальных данных в регрессионном анализе. Пример практического применения этих подходов при оценивании зависимости затрат от объема выпуска продукции дан в статье: Гуськова Е.А., Орлов А.И. Интервальная линейная парная регрессия (обобщающая статья). - Журнал "Заводская лаборатория". 2005. Т.71. No.3. С.57-63.
Анастасия Маркова