|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Опубликован: 09.11.2009 | Доступ: свободный | Студентов: 4099 / 1043 | Оценка: 4.66 / 4.45 | Длительность: 54:13:00
Темы: Математика, Экономика
Специальности: Экономист
Лекция 11:
Статистика нечисловых данных
Основные математические задачи анализа экспертных оценок. Ясно, что при анализе мнений экспертов можно применять самые разнообразные статистические методы, описывать их - значит описывать практически всю прикладную статистику. Тем не менее можно выделить основные широко используемые в настоящее время методы математической обработки экспертных оценок - это проверка согласованности мнений экспертов (или классификация экспертов, если нет согласованности) и усреднение мнений экспертов внутри согласованной группы.
Поскольку ответы экспертов во многих процедурах экспертного опроса - не числа, а такие объекты нечисловой природы, как градации качественных признаков, ранжировки, разбиения, результаты парных сравнений, нечеткие предпочтения и т.д., то для их анализа оказываются полезными методы статистики нечисловых данных.
Почему ответы экспертов часто носят нечисловой характер? Наиболее общий ответ состоит в том, что люди не мыслят числами. В мышлении человека используются образы, слова, но не числа. Поэтому требовать от эксперта ответ в форме чисел - значит насиловать его разум. Даже в экономике менеджеры и предприниматели, принимая решения, лишь частично опираются на численные расчеты. Это видно из условного (т.е. определяемого произвольно принятыми соглашениями, обычно оформленными в виде нормативных актов и инструкций) характера балансовой прибыли, амортизационных отчислений и других экономических показателей. Поэтому фраза типа "фирма стремится к максимизации прибыли" не может иметь строго определенного смысла. Достаточно спросить: "Максимизация прибыли - за какой период?" И сразу станет ясно, что степень оптимальности принимаемых решений зависит от горизонта планирования (на экономико-математическом уровне этот сюжет рассмотрен в монографии [ [ 1.15 ] ]).
Эксперт может сравнить два объекта, сказать, какой из двух лучше (метод парных сравнений), дать им оценки типа "хороший", "приемлемый", "плохой", упорядочить несколько объектов по привлекательности, но обычно не может ответить, во сколько раз или на сколько один объект лучше другого. Другими словами, ответы эксперта обычно измерены в порядковой шкале или являются ранжировками, результатами парных сравнений и другими объектами нечисловой природы, но не числами. Распространенное заблуждение состоит в том, что ответы экспертов стараются рассматривать как числа, занимаются "оцифровкой" их мнений, приписывая этим мнениям численные значения - баллы, которые потом обрабатывают с помощью методов прикладной статистики как результаты обычных физико-технических измерений. В случае произвольности "оцифровки" выводы, полученные в результате подобной обработки данных, могут не иметь отношения к реальности. В связи с "оцифровкой" уместно вспомнить классическую притчу о человеке, который ищет потерянные ключи под фонарем, хотя потерял их в кустах. На вопрос, почему он так делает, отвечает: "Под фонарем светлее". Это, конечно, верно. Но, к сожалению, весьма малы шансы найти потерянные ключи под фонарем. Так и с "оцифровкой" нечисловых данных. Она дает возможность имитации научной деятельности, но не возможность найти истину.
Проверка согласованности мнений экспертов и классификация экспертных мнений. Ясно, что мнения разных экспертов различаются. Важно понять, насколько велико это различие. Если мало - усреднение мнений экспертов позволит выделить то общее, что есть у всех экспертов, отбросив случайные отклонения в ту или иную сторону. Если велико - усреднение является чисто формальной процедурой. Так, если представить себе, что ответы экспертов равномерно покрывают поверхность бублика, то формальное усреднение укажет на центр дырки от бублика, а такого мнения не придерживается ни один эксперт. Из сказанного ясна важность проблемы проверки согласованности мнений экспертов.
Разработан ряд методов такой проверки. Статистические методы проверки согласованности зависят от математической природы ответов экспертов. Соответствующие статистические теории весьма трудны, если эти ответы - ранжировки или разбиения, и достаточно просты, если ответы - результаты независимых парных сравнений. Отсюда вытекает рекомендация по организации экспертного опроса: не старайтесь сразу получить от эксперта ранжировку или разбиение, ему трудно это сделать, да и имеющиеся математические методы не позволяют далеко продвинуться в анализе подобных данных.
Например, рекомендуют проверять согласованность ранжировок с помощью коэффициента ранговой конкордации Кендалла-Смита. Но давайте вспомним, какая статистическая модель при этом используется. Проверяется нулевая гипотеза, согласно которой ранжировки независимы и равномерно распределены на множестве всех ранжировок. Если эта гипотеза принимается, то конечно, ни о какой согласованности мнений экспертов говорить нельзя. А если отклоняется? Тоже нельзя. Например, может быть два (или больше) центра, около которых группируются ответы экспертов. Нулевая гипотеза отклоняется. Но разве можно говорить о согласованности?
Эксперту гораздо легче на каждом шагу сравнивать только два объекта. Пусть он занимается парными сравнениями. Непараметрическая теория парных сравнений (теория люсианов) позволяет решать более сложные задачи, чем статистика ранжировок или разбиений. В частности, вместо гипотезы равномерного распределения можно рассматривать гипотезу однородности, т.е. вместо совпадения всех распределений с одним фиксированным (равномерным) можно проверять лишь совпадение распределений мнений экспертов между собой, что естественно трактовать как согласованность их мнений. Таким образом, удается избавиться от неестественного предположения равномерности.
При отсутствии согласованности экспертов естественно разбить их на группы сходных по мнению. Это можно сделать различными методами статистики объектов нечисловой природы, относящимися к кластер-анализу, предварительно введя метрику в пространство мнений экспертов. Идея американского математика Джона Кемени об аксиоматическом введении метрик нашла многочисленных продолжателей. Однако методы кластер-анализа обычно являются эвристическими. В частности, обычно невозможно с позиций статистической теории строго обосновать "законность" объединения двух кластеров в один. Имеется важное исключение - для независимых парных сравнений (люсианов) разработаны методы, позволяющие проверять возможность объединения кластеров как статистическую гипотезу. Это - еще один аргумент за то, чтобы рассматривать теорию люсианов как ядро математических методов экспертных оценок.
Нахождение итогового мнения комиссии экспертов. Пусть мнения комиссии экспертов или какой-то ее части признаны согласованными. Каково же ее итоговое (среднее, общее) мнение? Согласно идее Джона Кемени следует найти среднее мнение как решение оптимизационной задачи. А именно, надо минимизировать суммарное расстояние от кандидата в средние до мнений экспертов. Найденное таким способом среднее мнение называют "медианой Кемени".
Математическая сложность состоит в том, что мнения экспертов лежат в некотором пространстве объектов нечисловой природы. Общая теория подобного усреднения рассмотрена выше (см. 5.5). В частности, показано, что в силу закона больших чисел (в пространствах произвольной природы) среднее мнение при увеличении числа экспертов (чьи мнения независимы и одинаково распределены) приближается к некоторому пределу, который, как известно, является математическим ожиданием (случайного элемента, имеющего то же распределение, что и ответы экспертов).
В конкретных пространствах нечисловых мнений экспертов вычисление медианы Кемени может быть достаточно сложным делом. Кроме свойств пространства, велика роль конкретных метрик. Так, в пространстве ранжировок при использовании метрики, связанной с коэффициентом ранговой корреляции Кендалла, необходимо проводить достаточно сложные расчеты, в то время как применение показателя различия на основе коэффициента ранговой корреляции Спирмена приводит к упорядочению по средним арифметическим рангам.
Бинарные отношения и расстояние Кемени. Как известно, бинарное отношение  на конечном множестве
на конечном множестве 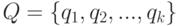 - это подмножество декартова квадрата
- это подмножество декартова квадрата 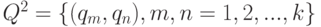 . При этом пара
. При этом пара 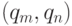 входит в тогда и только тогда, когда между
входит в тогда и только тогда, когда между 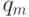 и
и  имеется рассматриваемое отношение.
имеется рассматриваемое отношение.
Напомним, что каждую кластеризованную ранжировку, как и любое бинарное отношение, можно задать квадратной матрицей 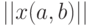 из 0 и 1 порядка
из 0 и 1 порядка  . При этом
. При этом 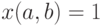 тогда и только тогда, когда
тогда и только тогда, когда 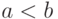 либо
либо 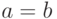 . В первом случае
. В первом случае 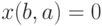 , а во втором
, а во втором 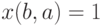 . При этом хотя бы одно из чисел
. При этом хотя бы одно из чисел 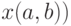 и
и 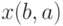 равно 1.
равно 1.
В экспертных методах используют, в частности, такие бинарные отношения, как ранжировки (упорядочения, или разбиения на группы, между которыми имеется строгий порядок), отношения эквивалентности, толерантности (отношения сходства). Как следует из сказанного выше, каждое бинарное отношение можно описать матрицей 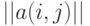 из 0 и 1, причем
из 0 и 1, причем 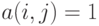 тогда и только тогда, когда
тогда и только тогда, когда  и
и 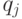 находятся в отношении , и
находятся в отношении , и 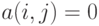 - в противном случае.
- в противном случае.
Определение. Расстоянием Кемени между бинарными отношениями и 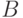 , описываемыми матрицами и
, описываемыми матрицами и 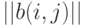 соответственно, называется число
соответственно, называется число
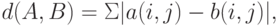
 от 1 до
от 1 до  , т.е. расстояние Кемени между бинарными отношениями равно сумме модулей разностей элементов, стоящих на одних и тех же местах в соответствующих им матрицах.
, т.е. расстояние Кемени между бинарными отношениями равно сумме модулей разностей элементов, стоящих на одних и тех же местах в соответствующих им матрицах.Легко видеть, что расстояние Кемени - это число несовпадающих элементов в матрицах 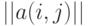 и
и 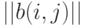 .
.
Расстояние Кемени основано на некоторой системе аксиом. Эта система аксиом и вывод из нее формулы для расстояния Кемени между упорядочениями содержится в книге [ [ 11.9 ] ]. Она сыграла большую роль в развитии в нашей стране такого научного направления, как анализ нечисловой информации (см. историю вопроса в монографиях [ [ 1.15 ] , [ 2.15 ] ]). В дальнейшем под влиянием работ Дж. Кемени были предложены различные системы аксиом для получения расстояний в тех или иных нужных для социально-экономических, технических, медицинских и иных исследований пространствах (см. 1.6).
Медиана Кемени и законы больших чисел. С помощью расстояния Кемени находят итоговое мнение комиссии экспертов. Пусть  - ответы
- ответы  экспертов, представленные в виде бинарных отношений. Для их усреднения используют медиану Кемени
экспертов, представленные в виде бинарных отношений. Для их усреднения используют медиану Кемени
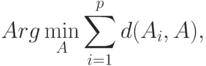
 - то или те значения , при которых достигает минимума указанная сумма расстояний Кемени от ответов экспертов до текущей переменной , по которой и проводится минимизация. Таким образом,
- то или те значения , при которых достигает минимума указанная сумма расстояний Кемени от ответов экспертов до текущей переменной , по которой и проводится минимизация. Таким образом,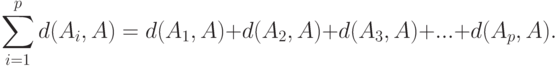
Кроме медианы Кемени, используют среднее по Кемени, в котором вместо 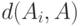 стоит
стоит 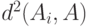 .
.
Медиана Кемени - частный случай определения эмпирического среднего в пространствах нечисловой природы. Для нее справедлив закон больших чисел, т.е. эмпирическое среднее приближается при росте числа составляющих (т.е. - числа слагаемых в сумме) к теоретическому среднему:

Здесь  - символ математического ожидания. Предполагается, что ответы экспертов
- символ математического ожидания. Предполагается, что ответы экспертов 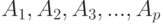 есть основания рассматривать как независимые одинаково распределенные случайные элементы (т.е. как случайную выборку) в соответствующем пространстве произвольной природы, например, в пространстве упорядочений или отношений эквивалентности. Систематически эмпирические и теоретические средние и соответствующие различные варианты законов больших чисел рассмотрены выше (см. 5.5.).
есть основания рассматривать как независимые одинаково распределенные случайные элементы (т.е. как случайную выборку) в соответствующем пространстве произвольной природы, например, в пространстве упорядочений или отношений эквивалентности. Систематически эмпирические и теоретические средние и соответствующие различные варианты законов больших чисел рассмотрены выше (см. 5.5.).
Законы больших чисел показывают, во-первых, что медиана Кемени обладает устойчивостью по отношению к незначительному изменению состава экспертной комиссии; во-вторых, при увеличении числа экспертов она приближается к некоторому пределу. Его естественно рассматривать как истинное мнение экспертов, от которого каждый из них несколько отклонялся по случайным причинам.
Вычисление медианы Кемени - задача целочисленного программирования. Для ее нахождения используются различные алгоритмы дискретной математики, в частности, основанные на методе ветвей и границ. Применяют также алгоритмы, основанные на идее случайного поиска, поскольку для каждого бинарного отношения нетрудно найти множество его соседей.
Рассмотрим упрощенный пример вычисления медианы Кемени. Пусть дана квадратная матрица (порядка 9) попарных расстояний для множества бинарных отношений из 9 элементов 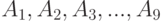 (см. табл.11.4). Пусть требуется найти в этом множестве медиану для множества из 5 элементов
(см. табл.11.4). Пусть требуется найти в этом множестве медиану для множества из 5 элементов 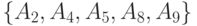 .
.
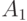 |
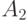 |
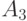 |
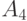 |
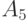 |
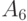 |
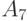 |
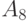 |
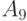 |
|
|
0 | 2 | 13 | 1 | 7 | 4 | 10 | 3 | 11 |
|
2 | 0 | 5 | 6 | 1 | 3 | 2 | 5 | 1 |
|
13 | 5 | 0 | 2 | 2 | 7 | 6 | 5 | 7 |
|
1 | 6 | 2 | 0 | 5 | 4 | 3 | 8 | 8 |
|
7 | 1 | 2 | 5 | 0 | 10 | 1 | 3 | 7 |
|
4 | 3 | 7 | 4 | 10 | 0 | 2 | 1 | 5 |
|
10 | 2 | 6 | 3 | 1 | 2 | 0 | 6 | 3 |
|
3 | 5 | 5 | 8 | 3 | 1 | 6 | 0 | 9 |
|
11 | 1 | 7 | 8 | 7 | 5 | 3 | 9 | 0 |
В соответствии с определением медианы Кемени следует ввести в рассмотрение функцию
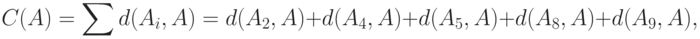
 и выбрать наименьшее. Проведем расчеты:
и выбрать наименьшее. Проведем расчеты: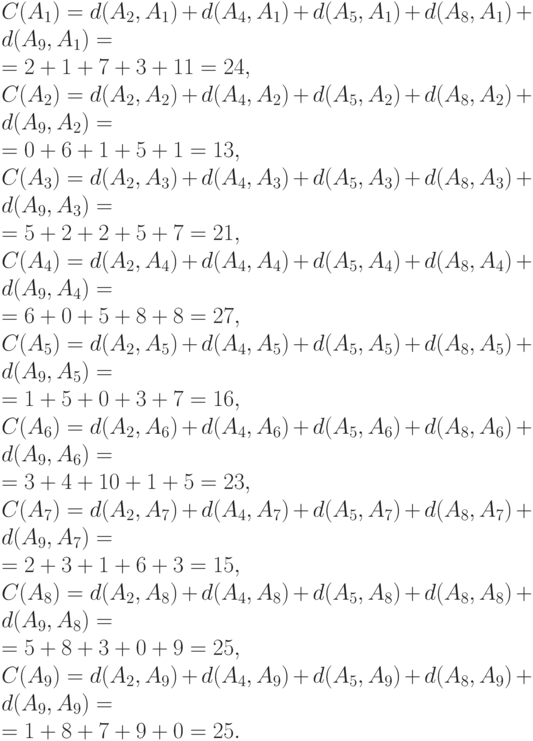
Из всех вычисленных сумм наименьшая равна 13, и достигается она при 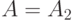 , следовательно, медиана Кемени - это множество
, следовательно, медиана Кемени - это множество  , состоящее из одного элемента .
, состоящее из одного элемента .
Анастасия Маркова