|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Опубликован: 09.11.2009 | Доступ: свободный | Студентов: 4093 / 1040 | Оценка: 4.66 / 4.45 | Длительность: 54:13:00
Темы: Математика, Экономика
Специальности: Экономист
Теги:
Лекция 6:
Оценивание
6.4. Робастность статистических процедур
Термин "робастность" ( robustnes ) образован от англ. robust - крепкий, грубый. Сравните с названием одного из сортов кофе - robusta. Имеется в виду, что робастные статистические процедуры должны "выдерживать" ошибки, которые теми или иными способами могут попадать в исходные данные или искажать предпосылки используемых вероятностно-статистических моделей.
Термин "робастный" стал популярным в нашей стране в 1970-е годы. Сначала он использовался фактически как сужение термина "устойчивый" на алгоритмы статистического анализа данных классического типа (не включая теорию измерений, статистику нечисловых и интервальных данных). Затем реальная сфера его применения сузилась.
Пусть исходные данные - это выборка, т.е. совокупность независимых одинаково распределенных случайных величин с одной и той же функцией распределения 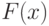 . Наиболее простая модель изучения устойчивости - это модель засорения
. Наиболее простая модель изучения устойчивости - это модель засорения
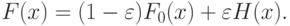 |
( 1) |
Эта модель именуется также моделью Тьюки-Хубера. (Джон Тьюки - американский исследователь, П. Хубер или Хьюбер - швейцарский ученый.) Модель (1) показывает, что с близкой к 1 вероятностью, а именно, с вероятностью  наблюдения берутся из совокупности с функцией распределения
наблюдения берутся из совокупности с функцией распределения 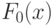 которая предполагается обладающей "хорошими" свойствами. Например, она имеет известный статистику вид (хотя бы с точностью до параметров), у нее существуют все моменты, и т.д. Но с малой вероятностью
которая предполагается обладающей "хорошими" свойствами. Например, она имеет известный статистику вид (хотя бы с точностью до параметров), у нее существуют все моменты, и т.д. Но с малой вероятностью 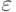 появляются наблюдения из совокупности с "плохим" распределением, например, взятые из распределения Коши, не имеющего математического ожидания, резко выделяющиеся аномальные наблюдения, выбросы.
появляются наблюдения из совокупности с "плохим" распределением, например, взятые из распределения Коши, не имеющего математического ожидания, резко выделяющиеся аномальные наблюдения, выбросы.
Актуальность модели (1) не вызывает сомнений. Наличие засорений (выбросов) может сильно исказить результаты эконометрического анализа данных. Ясно, что если функция распределения элементов выборки имеет вид (1), где первое слагаемое соответствует случайной величине с конечным математическим ожиданием, а второе - такой, для которого математического ожидания не существует (например, если 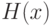 - функция распределения Коши), то для итоговой функции распределения (1) также не существует математического ожидания. Исследователя обычно интересуют характеристики первого слагаемого, но найти их, т.е. освободиться от влияния засорения, не так-то просто. Например, среднее арифметическое результатов наблюдений не будет иметь никакого предела (это - строгое математическое утверждение, вытекающее из того, что математическое ожидание не существует [
[
2.3
]
]).
- функция распределения Коши), то для итоговой функции распределения (1) также не существует математического ожидания. Исследователя обычно интересуют характеристики первого слагаемого, но найти их, т.е. освободиться от влияния засорения, не так-то просто. Например, среднее арифметическое результатов наблюдений не будет иметь никакого предела (это - строгое математическое утверждение, вытекающее из того, что математическое ожидание не существует [
[
2.3
]
]).
Существуют различные способы борьбы с засорением. Эмпирическое правило "борьбы с засорениями" при подведении итогов работы команды судей найдено в фигурном катании: наибольшая и наименьшая оценки отбрасываются, а по остальным рассчитывается средняя арифметическая. Ясно, что единичное "засорение" окажется среди отброшенных оценок.
Оценивать характеристики и параметры, проверять статистические гипотезы, вообще осуществлять статистический анализ данных все чаще рекомендуют на основе эмпирических квантилей (другими словами, порядковых статистик, членов вариационного ряда), отделенных от концов вариационного ряда. Речь идет об использовании статистик вида
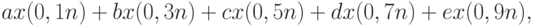
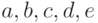 - заданные числа,
- заданные числа, 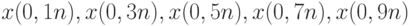 - члены вариационного ряда с номерами, наиболее близкими к числам, указанным в скобках. Так ценой небольшой потери в эффективности избавляемся от засоренности, подобно описанной в модели (1).
- члены вариационного ряда с номерами, наиболее близкими к числам, указанным в скобках. Так ценой небольшой потери в эффективности избавляемся от засоренности, подобно описанной в модели (1).Вариантом этого подхода является переход к сгруппированным данным. Отрезок прямой, содержащий основную часть наблюдений, разбивается на интервалы, и вместо количественных значений статистик подсчитывает лишь, сколько наблюдений попало в те или иные интервалы. Особое значение приобретают крайние интервалы - к ним относят все наблюдения, которые больше некоторого верхнего порога и меньше некоторого нижнего порога. Любым методам анализа сгруппированных данных резко выделяющиеся наблюдения не страшны.
Можно поставить под сомнение и саму опасность засорения. Дело в том, что практически все реальные величины ограничены. Все они лежат на каком-то интервале - от и до. Это совершенно ясно, если речь идет о физическом измерении - все результаты измерений укладываются в шкалу прибора. По-видимому, и для иных статистических измерений наибольшие сложности создают не сверхбольшие помехи, а те засорения, что находятся "на грани" между "интуитивно возможным" и "интуитивно невозможным".
Что же это означает для практики статистического анализа данных? Если элементы выборки по абсолютной величине не превосходят числа  , то все засорение может сдвинуть среднее арифметическое на величину
, то все засорение может сдвинуть среднее арифметическое на величину 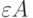 . Если засорение невелико, то и сдвиг мал.
. Если засорение невелико, то и сдвиг мал.
Построена достаточно обширная и развитая теория, посвященная разработке и изучению методов анализа данных в модели (1). С ней можно познакомиться по монографиям [ 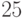 -
- 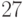 ]. К сожалению, в теории обычно предполагается известной степень засорения , а на практике эта величина неизвестна. Кроме того, теория обычно направлена на защиту от воздействий, якобы угрожающих из бесконечности (например, отсутствием математического ожидания), а на самом деле реальные данные финитны (сосредоточены на конечных отрезках). Все это объясняет, почему теория робастности, исходящая из модели (1), популярна среди теоретиков, но мало интересна тем, кто анализирует реальные технические, экономические, медицинские и иные статистические данные.
]. К сожалению, в теории обычно предполагается известной степень засорения , а на практике эта величина неизвестна. Кроме того, теория обычно направлена на защиту от воздействий, якобы угрожающих из бесконечности (например, отсутствием математического ожидания), а на самом деле реальные данные финитны (сосредоточены на конечных отрезках). Все это объясняет, почему теория робастности, исходящая из модели (1), популярна среди теоретиков, но мало интересна тем, кто анализирует реальные технические, экономические, медицинские и иные статистические данные.
Рассмотрим несколько более сложную модель. Пусть наблюдаются реализации  независимых случайных величин с функциями распределения
независимых случайных величин с функциями распределения  соответственно. Эта модель соответствует гипотезе о том, что в процессе наблюдения (измерения) условия несколько менялись. Естественной представляется модель малых отклонений функций распределений наблюдаемых случайных величин от некоторой "базовой" функции распределения . Множество возможных значений функций распределений наблюдаемых случайных величин (т.е. совокупность допустимых отклонений согласно общей схеме устойчивости, рассмотренной в
"Теоретическая база прикладной статистики"
) описывается следующим образом:
соответственно. Эта модель соответствует гипотезе о том, что в процессе наблюдения (измерения) условия несколько менялись. Естественной представляется модель малых отклонений функций распределений наблюдаемых случайных величин от некоторой "базовой" функции распределения . Множество возможных значений функций распределений наблюдаемых случайных величин (т.е. совокупность допустимых отклонений согласно общей схеме устойчивости, рассмотренной в
"Теоретическая база прикладной статистики"
) описывается следующим образом:
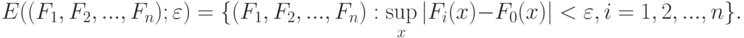
Следующий тип моделей - это введение малой (т.е. слабой) зависимости между рассматриваемыми случайными величинами (см., например, монографию [
[
6.28
]
]). Ограничения на взаимную зависимость можно задать разными способами. Пусть 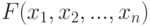 - совместная функция распределения
- совместная функция распределения  -мерного случайного вектора,
-мерного случайного вектора, 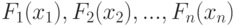 - функции распределения его координат. Если все координаты независимы, то
- функции распределения его координат. Если все координаты независимы, то 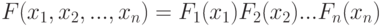 . Пусть
. Пусть 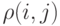 коэффициент корреляции между
коэффициент корреляции между  -ой и
-ой и  -ой случайными величинами - координатами вектора. Множество возможных совместных функций распределения (т.е. совокупность допустимых отклонений согласно общей схеме устойчивости, рассмотренной в
"Теоретическая база прикладной статистики"
) описывается следующим образом:
-ой случайными величинами - координатами вектора. Множество возможных совместных функций распределения (т.е. совокупность допустимых отклонений согласно общей схеме устойчивости, рассмотренной в
"Теоретическая база прикладной статистики"
) описывается следующим образом:
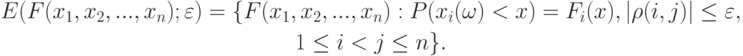
Таким образом, фиксируются функции распределения координат, а коэффициенты корреляции предполагаются малыми (по абсолютной величине).
Есть еще целый ряд постановок задач робастности. Если накладывать погрешности непосредственно на результаты наблюдений (измерений) и предполагать лишь, что эти погрешности не превосходят (по абсолютной величине) заданных величин, то получаем постановки задач статистики интервальных данных (см. "Статистика интервальных данных" ). При этом каждый результат наблюдения превращается в интервал - исходное значение плюс-минус максимально возможная погрешность.
Разработано много вариантов робастных методов анализа статистических данных (см. монографии [  , 25-28]). Иногда говорят, что робастные методы позволяют использовать информацию о том, что реальные наблюдения лежат "около" тех или иных параметрических семейств, например, нормальных. В этом, дескать, их преимущество по сравнению с непараметрическими методами, которые предназначены для анализа данных, распределенных согласно произвольной непрерывной функции распределения. Однако количественных подтверждений этих уверений любителей робастных методов обычно не удается найти. В основном потому, что термин "около" трудно формализовать.
, 25-28]). Иногда говорят, что робастные методы позволяют использовать информацию о том, что реальные наблюдения лежат "около" тех или иных параметрических семейств, например, нормальных. В этом, дескать, их преимущество по сравнению с непараметрическими методами, которые предназначены для анализа данных, распределенных согласно произвольной непрерывной функции распределения. Однако количественных подтверждений этих уверений любителей робастных методов обычно не удается найти. В основном потому, что термин "около" трудно формализовать.
На примере различных подходов к изучению робастности статистических процедур оценивания и проверки гипотез видны сложности, связанные с изучением устойчивости. Дело в том, что для каждой конкретной статистической задачи можно самыми разными способами задать совокупность допустимых отклонений. Так, выше кратко рассмотрены четыре такие совокупности, соответствующие модели засорения Тьюки-Хубера, модели малых отклонений функций распределения, модели слабых связей и модели интервальных данных.
В каждой из этих моделей общая схема устойчивости ( "Теоретическая база прикладной статистики" ) предлагает для решения целый спектр задач устойчивости. Кроме изучения свойств робастности известных статистических процедур можно в каждой из постановок находить оптимальные процедуры. Однако практическая ценность этих оптимальных процедур, как правило, невелика, поскольку в других постановках оптимальными будут уже другие процедуры.
Контрольные вопросы и задачи
- Чем задачи оценивания параметров распределения отличаются от задач оценивания характеристик распределения?
- С помощью метода линеаризации обоснуйте вид асимптотических дисперсий оценок метода моментов для параметров гамма-распределения (табл.6.3 в 6.1).
- Почему одношаговые оценки предпочтительнее оценок максимального правдоподобия?
- Как связаны законы больших чисел в пространствах произвольной природы и утверждения об асимптотическом поведении решений экстремальных статистических задач?
- Как соотносятся параметрическая и непараметрическая регрессии?
- Сопоставьте различные постановки задач изучения робастности статистических процедур.
Темы докладов, рефератов, исследовательских работ
- Квантильные оценки.
- Минимизация расстояния как способ построения оценок параметров.
- Одношаговые оценки параметров распределения Вейбулла-Гнеденко.
- Оптимизационные постановки основных задач прикладной статистики.
- Роль функции влияния при изучении робастности в модели засорения Тьюки-Хубера.
- На основе четырех указанных в настоящем учебнике моделей сформулируйте новые постановки задач устойчивости статистических процедур.
Анастасия Маркова