|
Здравствуйте! 4 июня я записалась на курс Прикладная статистика. Заплатила за получение сертификата. Изучала лекции, прошла Тест 1. Сегодня вижу, что я вне курса! Почему так произошло? |
Опубликован: 09.11.2009 | Доступ: свободный | Студентов: 4094 / 1041 | Оценка: 4.66 / 4.45 | Длительность: 54:13:00
Темы: Математика, Экономика
Специальности: Экономист
Лекция 3:
Выборочные исследования
В настоящее время нет необходимости вычислять функцию стандартного нормального распределения и ее плотность по приведенным выше формулам, поскольку давно составлены подробные таблицы (см., например, [ [ 2.1 ] ]), а распространенные программные продукты содержат алгоритмы нахождения этих функций.
С помощью теоремы Муавра-Лапласа могут быть построены доверительные интервалы для неизвестной эконометрику вероятности. Сначала заметим, что из этой теоремы непосредственно следует, что

Поскольку функция стандартного нормального распределения симметрична относительно 0, т.е.  то
то 
Зададим доверительную вероятность 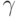 . Пусть
. Пусть  удовлетворяет условию
удовлетворяет условию

Из последнего предельного соотношения следует, что

К сожалению, это соотношение нельзя непосредственно использовать для доверительного оценивания, поскольку верхняя и нижняя границы зависят от неизвестной вероятности. Однако с помощью метода наследования сходимости (см. "Теоретическая база прикладной статистики" или [ [ 1.15 ] , п.2.4]) можно доказать, что

Следовательно, нижняя доверительная граница имеет вид


Наиболее распространенным (в прикладных исследованиях) значением доверительной вероятности является  . Иногда употребляют термин "95% доверительный интервал". Тогда
. Иногда употребляют термин "95% доверительный интервал". Тогда  .
.
Пример 1. Пусть  . Тогда
. Тогда 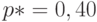 . Найдем доверительный интервал для :
. Найдем доверительный интервал для :
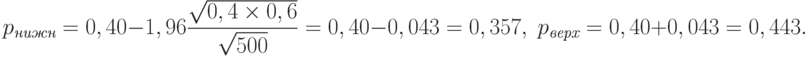
Таким образом, хотя в достаточно большой выборке 40% респондентов говорят "да", можно утверждать лишь, что во всей генеральной совокупности таких от 35,7 до 44,3% - крайние значения отличаются на 8,6%.
Замечание. С достаточной для практики точностью можно заменить 1,96 на 2.
Удобные для использования в практической работе специалиста по выборочным исследованиям, маркетолога и социолога таблицы точности оценивания разработаны во ВЦИОМ (Всероссийском центре по изучению общественного мнения). Приведем здесь несколько модифицированный вариант одной из них (табл.3.5).
Доля 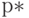 \ Объем группы \ Объем группы |
1000 | 750 | 600 | 400 | 200 | 100 |
|---|---|---|---|---|---|---|
| Около 10% или 90% | 2 | 3 | 3 | 4 | 5 | 7 |
| Около 20% или 80% | 3 | 4 | 4 | 5 | 7 | 9 |
| Около 30% или 70% | 4 | 4 | 4 | 6 | 9 | 10 |
| Около 40% или 60% | 4 | 4 | 5 | 6 | 8 | 11 |
| Около 50% | 4 | 4 | 5 | 6 | 8 | 11 |
В условиях рассмотренного выше примера надо взять вторую снизу строку. Объема выборки 500 нет в таблице, но есть объемы 400 и 600, которым соответствуют ошибки в 6% и 5% соответственно. Следовательно, в условиях примера целесообразно оценить ошибку как [(5+6)/2]% = 5,5%. Эта величина несколько больше, чем рассчитанная выше (4,3%). С чем связано это различие? Дело в том, что таблица ВЦИОМ связана не с доверительной вероятностью , а с доверительной вероятностью 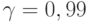 которой соответствует множитель
которой соответствует множитель  . Расчет ошибки по приведенным выше формулам дает 5,65%, что практически совпадает со значением, найденным по табл.3.5.
. Расчет ошибки по приведенным выше формулам дает 5,65%, что практически совпадает со значением, найденным по табл.3.5.
Минимальный из обычно используемых объемов выборки  в маркетинговых или социологических исследованиях - 100, максимальный - до 5000 (обычно в исследованиях, охватывающих ряд регионов страны, т.е. фактически разбивающихся на ряд отдельных исследований - как в ряде исследований ВЦИОМ). По данным Института социологии Российской академии наук [
[
3.2
]
], среднее число анкет в социологическом исследовании не превышает 700. Поскольку стоимость исследования растет по крайней мере как линейная функция объема выборки, а точность повышается как квадратный корень из этого объема, то верхняя граница объема выборки определяется обычно из экономических соображений. Объемы пилотных исследований (т.е. проводящихся впервые, предварительно или как первые в сериях подобных) обычно ниже, чем объемы исследований по обкатанной программе.
в маркетинговых или социологических исследованиях - 100, максимальный - до 5000 (обычно в исследованиях, охватывающих ряд регионов страны, т.е. фактически разбивающихся на ряд отдельных исследований - как в ряде исследований ВЦИОМ). По данным Института социологии Российской академии наук [
[
3.2
]
], среднее число анкет в социологическом исследовании не превышает 700. Поскольку стоимость исследования растет по крайней мере как линейная функция объема выборки, а точность повышается как квадратный корень из этого объема, то верхняя граница объема выборки определяется обычно из экономических соображений. Объемы пилотных исследований (т.е. проводящихся впервые, предварительно или как первые в сериях подобных) обычно ниже, чем объемы исследований по обкатанной программе.
Нижняя граница определяется тем, что в минимальной по численности анализируемой подгруппе должно быть несколько десятков человек (не менее 30), поскольку по ответам попавших в эту подгруппу необходимо сделать обоснованные заключения о предпочтениях соответствующей подгруппы в совокупности всех потребителей растворимого кофе. Учитывая деление опрашиваемых на продавцов и покупателей, на мужчин и женщин, на четыре градации по возрасту и восемь - по роду занятий, наличие 5 - 6 подсказок во многих вопросах, приходим к выводу о том, что в рассматриваемом проекте объем выборки должен быть не менее 400 - 500. Вместе с тем существенное превышение этого объема нецелесообразно, поскольку исследование является пилотным.
Поэтому в проекте "Потребители растворимого кофе" объем выборки был выбран равным 500. Анализ полученных результатов (см. ниже) позволяет утверждать, что в соответствии с целями исследования выборку следует считать репрезентативной.
Организация опроса. Интервьерами работали молодые люди - студенты первого курса экономико-математического факультета Московского государственного института электроники и математики (технического университета), проходившие обучение по экономике, всего 40 человек, имеющих специальную подготовку по изучению рынка и проведению маркетинговых опросов потребителей и продавцов (в объеме 8 часов). Опрос продавцов проводился на рынках г. Москвы, действующих в Лужниках, у Киевского вокзала и в других местах. Опрос покупателей проводился на рынках, в магазинах, на улицах около киосков и ларьков, а также в домашней и служебной обстановке.
Большое внимание уделялось качеству заполнения анкет. Интервьюеры были разбиты на шесть бригад, бригадиры персонально отвечали за качество заполнения анкет. Второй уровень контроля осуществляла специально созданная "группа организации опроса", третий происходил при вводе информации в базу данных. Каждая анкета была заверена подписями интервьюера и бригадира, на ней указывалось место и время интервьюирования. Поэтому необходимо признать высокую достоверность собранных анкет.
Обработка данных. В соответствии с целью исследования основной метод первичной обработки данных - построение частотных таблиц для ответов на отдельные вопросы. Кроме того, проводилось сравнение различных групп потребителей и продавцов, выделенных по социально-демографическим данным, с помощью критериев проверки однородности выборок (см. ниже). При более углубленном анализе применялись различные методы статистики объектов нечисловой природы (более 90% маркетинговых и социологических данных имеют нечисловую природу [ [ 3.4 ] ]). Использовались средства графического представления данных.
Подведем итоги. Итак, по заданию одной из торговых фирм были изучены предпочтения покупателей и мелкооптовых продавцов растворимого кофе. Совместно с представителями заказчика был составлен опросный лист (анкета типа социологической) из 16 основных вопросов и 4 дополнительных, посвященных социально-демографической информации. Опрос проводился в форме интервью с 500 покупателями и продавцами кофе. Места опроса - рынки, лотки, киоски, продуктовые и специализированные магазины. Другими словами, были охвачены все виды мест продаж кофе. Интервью проводили более 40 специально подготовленных (примерно по 8-часовой программе) студентов, разбитых на 7 бригад. После тщательной проверки бригадирами и группой обработки информация была введена в специально созданную базу данных. Затем проводилась разнообразная статистическая обработка, строились таблицы и диаграммы, проверялись статистические гипотезы и т.д. Заключительный этап - осмысление и интерпретация данных, подготовка итогового отчета и предложений для заказчиков.
Анастасия Маркова