|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2187 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 2:
Принципы анализа алгоритмов
Гарантии, предсказания и ограничения
Время выполнения большинства алгоритмов зависит от входных данных. Обычно нашей целью при анализе алгоритмов является устранение каким-либо образом этой зависимости: необходимо иметь возможность сказать что-то о производительности наших программ, что почти не зависит от входных данных, так как в общем случае неизвестно, какими будут входные данные при каждом новом запуске программы. Примеры из раздела 2.6 иллюстрируют два основных подхода, которые применяются в этом случае: анализ производительности в худшем случае и анализ производительности в среднем.
Изучение производительности алгоритмов в худшем случае привлекательно тем, что оно позволяет гарантированно сказать что-либо о времени выполнения программ. Мы говорим, что количество выполнений определенных абстрактных операций меньше, чем определенная функция от объема входных данных, независимо от значений этих данных. Например, лемма 2.3 представляет собой пример такой гарантии для бинарного поиска, а лемма 1.3 - для взвешенного быстрого объединения. Если гарантированное время мало, как в случае с бинарным поиском, то это хорошо: значит, удалось устранить ситуации, когда программа работает медленно. Поэтому программы с хорошими характеристиками в худшем случае являются основной целью разработки алгоритмов.
Однако при анализе производительности в худшем случае существуют и некоторые трудности. Для некоторых алгоритмов может существовать весомая разница между временем, необходимым для решения задачи в случае худших входных данных, и временем, необходимым для данных, которые обычно встречаются на практике. Например, быстрое объединение в худшем случае требует времени выполнения, пропорционального  , но лишь
, но лишь  для обычных данных. Часто не удается доказать, что существуют входные данные, для которых время выполнения алгоритма достигает определенного предельного значения; можно лишь доказать, что время выполнения наверняка ниже этого предела. Более того, для некоторых задач алгоритмы с хорошей производительностью в худшем случае гораздо сложнее других алгоритмов. Часто бывает так, что алгоритм с хорошими характеристиками в худшем случае при работе с обычными данными оказывается медленнее, чем более простые алгоритмы, или же при незначительном выигрыше в скорости он требует дополнительных усилий для достижения хороших характеристик в худшем случае. Для многих приложений другие качества - переносимость и надежность - более важны, чем гарантии для худшего случая. Например, как было показано в
"Введение"
, взвешенное быстрое объединение со сжатием пути обеспечивает лучшую гарантированную производительность, чем взвешенное быстрое объединение, но для типичных данных, встречающихся на практике, эти алгоритмы имеют примерно одинаковое время выполнения.
для обычных данных. Часто не удается доказать, что существуют входные данные, для которых время выполнения алгоритма достигает определенного предельного значения; можно лишь доказать, что время выполнения наверняка ниже этого предела. Более того, для некоторых задач алгоритмы с хорошей производительностью в худшем случае гораздо сложнее других алгоритмов. Часто бывает так, что алгоритм с хорошими характеристиками в худшем случае при работе с обычными данными оказывается медленнее, чем более простые алгоритмы, или же при незначительном выигрыше в скорости он требует дополнительных усилий для достижения хороших характеристик в худшем случае. Для многих приложений другие качества - переносимость и надежность - более важны, чем гарантии для худшего случая. Например, как было показано в
"Введение"
, взвешенное быстрое объединение со сжатием пути обеспечивает лучшую гарантированную производительность, чем взвешенное быстрое объединение, но для типичных данных, встречающихся на практике, эти алгоритмы имеют примерно одинаковое время выполнения.
Изучение средней производительности алгоритмов привлекательно тем, что оно позволяет делать предположения о времени выполнения программ. В простейшем случае можно точно охарактеризовать входные данные алгоритма; например, алгоритм сортировки может выполняться для массива из случайных целых чисел или геометрический алгоритм может обрабатывать набор из случайных точек на плоскости с координатами между 0 и 1. Затем можно подсчитать, сколько раз в среднем выполняется каждая инструкция, и вычислить среднее время выполнения программы, умножив частоту выполнения каждой инструкции на время ее выполнения и просуммировав по всем инструкциям.
Однако и в анализе средней производительности существуют трудности. Во-первых, модель входных данных может неточно характеризовать данные, встречающиеся на практике, или же естественная модель входных данных может вообще не существовать. Мало кто будет возражать против использования таких моделей входных данных, как "случайно упорядоченный файл" для алгоритма сортировки или "множество случайных точек" для геометрического алгоритма, и для таких моделей можно получить математические результаты, которые будут точно предсказывать производительность программ в реальных приложениях. Но как можно характеризовать входные данные для программы, которая обрабатывает текст на английском языке? Даже для алгоритмов сортировки в определенных приложениях рассматриваются модели, отличные от случайно упорядоченных данных. Во-вторых, анализ может требовать глубоких математических выкладок. Например, сложно выполнить анализ средней производительности для алгоритмов объединение-поиск. Хотя вывод таких результатов обычно выходит за рамки этой книги, мы будем иллюстрировать их природу некоторыми классическими примерами, а также, при необходимости, будем ссылаться на важные результаты (к счастью, анализ большинства алгоритмов можно найти в исследовательской литературе). В третьих, знания среднего значения времени выполнения не всегда достаточно: может понадобиться среднеквадратичное отклонение или другие сведения о распределении времени выполнения, вывод которых может оказаться еще более трудным. В частности, нас будет часто интересовать вероятность того, что алгоритм будет работать значительно медленнее, нежели ожидается.
Во многих случаях на первое возражение можно ответить превращением случайности в достоинство. Например, если случайным образом "взболтать" массив перед сортировкой, то предположение о случайном порядке элементов массива будет выполнено. Для таких алгоритмов, которые называются рандомизированными (randomized), анализ средней производительности приводит к ожидаемому времени выполнения в строгом вероятностном смысле. Более того, часто можно доказать, что вероятность медленной работы такого алгоритма пренебрежимо мала. К подобным алгоритмам относятся быстрая сортировка ( "Очереди с приоритетами и пирамидальная сортировка" ), рандомизированные BST ( "Сбалансированные деревья" ) и хеширование ( "Хеширование" ).
Вычислительная сложность - это направление анализа алгоритмов, где рассматриваются фундаментальные ограничения, которые могут возникнуть при анализе алгоритмов. Общая цель заключается в определении времени выполнения в худшем случае лучшего алгоритма для данной задачи с точностью до постоянного множителя. Эта функция называется сложностью задачи.
Анализ производительности в худшем случае с использованием О-нотации освобождает аналитика от необходимости включать в рассмотрение характеристики конкретной машины. Выражение "время выполнения алгоритма равно Of(N))" не зависит от входных данных, полезно для распределения алгоритмов по категориям вне зависимости от входных данных и деталей реализации и таким образом отделяет анализ алгоритма от любой конкретной его реализации. В анализе мы, как правило, отбрасываем постоянные множители. В большинстве случаев, если нужно знать, чему пропорционально время выполнения алгоритма - или - не имеет значения, где будет выполняться алгоритм: на небольшом компьютере или на суперкомпьютере. Не имеет значения даже то, хорошо или плохо реализован внутренний цикл алгоритма.
Когда можно доказать, что время выполнения алгоритма в худшем случае равно 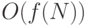 , то говорят, что
, то говорят, что 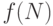 является верхней границей сложности задачи. Другими словами, время выполнения лучшего алгоритма не больше, чем время любого другого алгоритма для данной задачи.
является верхней границей сложности задачи. Другими словами, время выполнения лучшего алгоритма не больше, чем время любого другого алгоритма для данной задачи.
Мы постоянно стремимся улучшать алгоритмы, но однажды наступает момент, когда никакое изменение не может снизить время выполнения. Для каждой задачи желательно знать, где необходимо остановиться в улучшении алгоритма - то есть мы ищем нижнюю границу сложности. Для многих задач можно доказать, что любой алгоритм решения задачи должен использовать определенное количество фундаментальных операций. Доказательство существования нижней границы - сложное дело, связанное с тщательным созданием модели машины и разработкой замысловатых теоретических конструкций входных данных, которые трудны для любого алгоритма. Мы редко затрагиваем вопрос о нахождении нижних границ, но они представляют собой вычислительные барьеры при разработке алгоритмов, и при необходимости мы будем о них упоминать.
Когда изучение сложности задачи показывает, что верхняя и нижняя границы алгоритма совпадают, тогда можно быть уверенным в том, что нет смысла пытаться разработать алгоритм, который был бы существенно быстрее, чем наилучший из известных. В этом случае остается сконцентрировать внимание на реализации. Например, бинарный поиск является оптимальным в том смысле, что никакой алгоритм, использующий только сравнения, не сможет в худшем случае обойтись меньшим их количеством, чем бинарный поиск.
Верхняя и нижняя границы совпадают также и для алгоритмов объединение-поиск, использующих указатели. В 1975 г. Тарьян (Tarjan) показал, что алгоритм взвешенного быстрого объединения со сжатием пути требует менее чем  переходов по указателям в худшем случае, и что любой алгоритм с указателями должен перейти более чем по постоянному числу указателей в худшем случае. Другими словами, нет смысла в поиске какого-либо нового улучшения, которое гарантировало бы решение задачи линейным числом операций
переходов по указателям в худшем случае, и что любой алгоритм с указателями должен перейти более чем по постоянному числу указателей в худшем случае. Другими словами, нет смысла в поиске какого-либо нового улучшения, которое гарантировало бы решение задачи линейным числом операций ![i=a[i]](/sites/default/files/tex_cache/f6ba3a82ea1e02287edb45a5c6761129.png) . На практике эта разница едва ощутима, поскольку
. На практике эта разница едва ощутима, поскольку  очень мало, однако поиск простого линейного алгоритма для этой задачи был темой исследований в течение долгого времени, и найденная Тарьяном нижняя граница направила усилия исследователей на другие задачи. Более того, оказывается, нельзя обойти функции вроде довольно сложной функции
очень мало, однако поиск простого линейного алгоритма для этой задачи был темой исследований в течение долгого времени, и найденная Тарьяном нижняя граница направила усилия исследователей на другие задачи. Более того, оказывается, нельзя обойти функции вроде довольно сложной функции  , поскольку они присущи самой задаче.
, поскольку они присущи самой задаче.
Многие алгоритмы в этой книге были предметом глубокого математического и эмпирического анализа, слишком сложного, чтобы обсуждать его здесь. Но именно на основе этих исследований мы рекомендуем многие из тех алгоритмов, которые описаны далее.
Не все алгоритмы стоят такого тщательного рассмотрения; ведь при создании алгоритмов желательно работать с приближенными признаками производительности, чтобы не усложнять процесс разработки излишними деталями. По мере усложнения разработки то же самое должно происходить и с анализом, с привлечением более сложных математических инструментов. Часто процесс создания алгоритма приводит к детальному изучению сложности, которые, в свою очередь, ведут к таким теоретическим алгоритмам, которые далеки от каких-либо практических приложений. Распространенная ошибка - считать, что грубый анализ исследований сложности сразу же приведет к эффективному и удобному алгоритму. Такие ожидания завершаются неприятными сюрпризами. С другой стороны, вычислительная сложность - это мощный инструмент, который помогает определить границы производительности при разработке алгоритма и может послужить отправной точкой для сужения промежутка между верхней и нижней границами.
В этой книге мы придерживаемся точки зрения, что разработка алгоритма, тщательная его реализация, математический анализ, теоретические исследования и эмпирический анализ все вместе вносят важный вклад в создание элегантных и эффективных программ. Мы стремимся получить информацию о свойствах программ всеми доступными средствами, а затем, на основе полученной информации, модифицировать их или разработать новые программы. У нас нет возможности выполнять тщательное тестирование и анализ каждого алгоритма во всех программных средах на любой возможной машине, но мы можем воспользоваться известными эффективными реализациями алгоритмов, а затем улучшать и сравнивать их, если потребуется высокая производительность. При необходимости мы будем достаточно подробно рассматриваться наиболее важные методы, чтобы понять, почему они работают так хорошо.
Упражнение
2.51. Известно, что временная сложность одной задачи равна N*log N, а другой - N3. Что следует из данного утверждения об относительной производительности алгоритмов, которые решают эти задачи?
Ссылки к части I
Существует множество начальных учебников по программированию. Стандартный справочник по языку C++ - книга Страуструпа (Stroustup), а наилучшим источником конкретных сведений о C с примерами программ, многие из которых верны и для C++ и написаны в том же духе, что и программы в этой книге, является книга Кернигана и Ричи (Kernigan, Ritchie).
Несколько вариантов алгоритмов для задачи объединение-поиск из "Введение" собраны и объяснены в статье Ван Левена и Тарьяна (van Leewen, Tarjan).
В книгах Бентли (Bentley) описаны в том же стиле, что и изложенный здесь материал, несколько подробных примеров использования различных подходов при разработке и реализации алгоритмов для решения различных интересных задач.
Классический справочник по анализу алгоритмов на основе измерений асимптотической производительности в худшем случае - это книга Ахо, Хопкрофта и Ульмана (Aho, Hopcroft, Ullman). Книги Кнута (Knuth) содержат более полный анализ средней производительности и являются заслуживающим доверия описанием конкретных свойств многих алгоритмов. Более современные работы - книги Гонне, Баеса-Ятеса (Gonnet, Baeza-Yates) и Кормена, Лейзерсона, Ривеста (Cormen, Leiserson, Rivest). Обе они содержат обширные списки ссылок на исследовательскую литературу.
Книга Грэма, Кнута, Паташника (Graham, Knuth, Patashnik) рассказывает о разделах математики, которые обычно встречаются при анализе алгоритмов; этот же материал разбросан и в упомянутых ранее книгах Кнута. Книга Седжвика и Флажоле (Sedgewick and Flajolet) представляет собой исчерпывающее введение в предмет.
1. A.V Aho, J.E. Hopcroft, and J.D. Ullman, The Design and Analysis of Algorithms, Addison-Wesley, Reading, MA, 1975.
2. J.L. Bentley, Programming Pearls, Addison-Wesley, Reading, MA, 1985; More Programming Pearls, Addison-Wesley, Reading, MA, 1988.
3. R. Baeza-Yates and G.H. Gonnet, Handbook of Algorithms and Data Stru^ures, second edition, Addison-Wesley, Reading,MA, 1984.
4. Томас Х. Кормен, Чарльз И. Лейзерсон, Рональд Л. Ривест, Клиффорд Штайн, Алгоритмы: построение и анализ, 2-е издание, ИД "Вильямс", 2009 г.
5. R.L. Graham, D.E. Knuth, and O. Patashnik, Con^ete Mathemattes, Addison-Wesley, Reading, MA, 1988.
6. Брайан У. Керниган, Деннис М. Ритчи, Язык программирования C (Си), 2-е издание, ИД "Вильямс", 2008 г.
7. Д.Э. Кнут, Искусство программирования, том 1: Основные алгоритмы, 3-е издание, ИД "Вильямс", 2008 г.; Д.Э. Кнут, Искусство программирования, том 2: Получисленные алгоритмы, 3-е издание, ИД "Вильямс", 2008 г.; Д.Э. Кнут, Искусство программирования, том 3. Сортировка и поиск, 2-е издание, ИД "Вильямс", 2008 г.
8. R. Sedgewick and P. Flajolet, An Introdu^on to the Analysis of Algorithms, Addison-Wesley, Reading, MA, 1996.
9. B. Stroustrup, The C+ + Programming Language, third edition, Addison-Wesley, Reading MA, 1997.
10. J. van Leeuwen and R.E. Tarjan, "Worst-case analysis of set-union algorithms", Journal of the ACM, 1984.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |