Московский государственный университет имени М.В.Ломоносова
Опубликован: 30.04.2008 | Доступ: свободный | Студентов: 1624 / 256 | Оценка: 4.24 / 3.92 | Длительность: 14:56:00
Тема: Компьютерная графика
Специальности: Математик
Лекция 2:
Классификация на основе байесовской теории решений
2.2. Ошибка классификации
Определение. Вероятность  называется ошибкой классификации,
называется ошибкой классификации,

 .
.Теорема. Байесовский классификатор является оптимальным по отношению к минимизации вероятности ошибки классификации.
Доказательство. Рассмотрим ошибку классификации:

Учитывая формулу Байеса:


 .
. 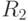 выбирается из остальных точек.
выбирается из остальных точек.Данная теорема была доказана для двух классов 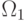 и
и 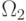 .
Обобщим ее на
.
Обобщим ее на  классов.
классов.
Пусть вектор признаков  относится к классу
относится к классу 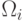 ,
если
,
если 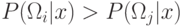 , при
, при  .
Соответственно необходимо доказать, что данное правило минимизирует
вероятность ошибки классификации. Для доказательства следует
воспользоваться формулой правильной классификации
.
Соответственно необходимо доказать, что данное правило минимизирует
вероятность ошибки классификации. Для доказательства следует
воспользоваться формулой правильной классификации 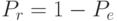 .
.
Доказательство. Воспользуемся формулой правильной классификации .
![\begin{gathered}
P_r=P(x\in R_1,\Omega_1)+P(x\in R_2,\Omega_2)+\ldots+P(x\in R_i,\Omega_i)= \\
=\sum_{i=1}^l P(x\in R_i|\Omega_i)P(\Omega_i)= \\
=\sum_{i=1}^l P(\Omega_i)\int\limits_{R_i}p(x|\Omega_i)dx= \\
=P(\Omega_1)\left(1-\sum_{i=2}^l\int\limits_{R_i}p(x|\Omega_1)dx \right)+\sum_{i=2}^l P(\Omega_i)\int\limits_{R_i}p(x|\Omega_i)dx= \\
=P(\Omega_1)-\sum_{i=2}^l\left[P(\Omega_1)\int\limits_{R_i}p(x|\Omega_1)dx-P(\Omega_i)\int\limits_{R_i}p(x|\Omega_i)dx\right]=
\end{gathered}](/sites/default/files/tex_cache/f09710b46a93fd40b98690cb68ab2d63.png)
 , получим:
, получим:![\begin{gathered}
=P(\Omega_1)-\sum_{i=2}^l\left[P(\Omega_1)\int\limits_{R_i}\frac{P(\Omega_1|x)p(x)}{P(\Omega_1)}dx-
P(\Omega_1)\int\limits_{R_i}\frac{P(\Omega_i|x)p(x)}{P(\Omega_i)}dx\right]=\\
=P(\Omega_1)-\sum_{i=2}^l\left[\int\limits_{R_i}P(\Omega_1|x)p(x)dx-\int\limits_{R_i}P(\Omega_1|x)p(x)dx\right]=\\
=P(\Omega_1)-\sum_{i=2}^l\int\limits_{R_i}p(x)\left[P(\Omega_1|x)-P(\Omega_i|x) \right]dx
\end{gathered}](/sites/default/files/tex_cache/10df69da331af775343ca79efbd68b42.png)
 .
Аналогично для всех
.
Аналогично для всех  максимум достигается, когда
максимум достигается, когда  .
.