|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2191 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 17:
Виды графов и их свойства
Вариации, расширения и затраты
В этом разделе мы рассмотрим несколько способов совершенствования представлений графов, которые были описаны в разделах 17.3 и 17.4. Все рассматриваемые вопросы можно разделить на три категории. Во-первых, базовые механизмы матрицы смежности и списков смежности легко расширяются для представления других видов графов. В последующих лекциях будут рассмотрены и такие расширения, и соответствующие примеры; а здесь мы дадим лишь краткий обзор. Во-вторых, мы рассмотрим структуры АТД графа с большим набором свойств, чем структура, выбранная нами в качестве базовой, и использование более развитых структур данных для построения их эффективных реализаций. В-третьих, мы подробнее изучим наш общий подход к решению задач обработки графов, разрабатывая на основе базового АТД графа классы, нацеленные на некоторые конкретные задачи.
Реализации, приведенные в программах 17.7 и 17.9, могут строить орграфы, если при вызове конструктора указать второй аргумент, равный true. Как показано на рис. 17.11, каждое ребро входит в представление графа только один раз.
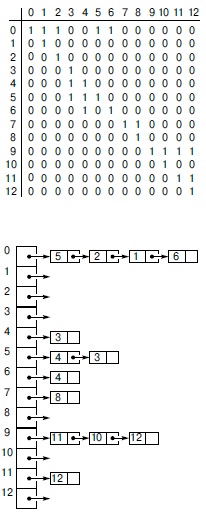
Ребро v-w в орграфе представлено единицей в элементе матрицы смежности, расположенном на пересечении строки v и столбца w или вершиной w в списке смежности вершины v в представлении графа списками смежности. Эти представления проще представлений, которые были выбраны для неориентированных графов, однако присущая им асимметрия делает их более сложными комбинаторными объектами, чем неориентированные графы, в чем мы убедимся в "Орграфы и DAG-графы" . Например, стандартное представление графа списками смежности не обеспечивает простого способа определения всех ребер, входящих в заданную вершину орграфа, и если требуется поддержка этой операции, придется использовать другие представления.
В случае взвешенных графов (weighted graph) и сетей (network) матрица смежности наполняется структурами с информацией о ребрах (включая данные об их наличии или отсутствии), которые заменяют соответствующие булевские значения; в представлении списками смежности эта информация содержится в элементах списков смежности.
В представлениях орграфа матрицей смежности и списками смежности каждое ребро представлено только один раз -это видно из представлений множества ребер, приведенного на рис. 17.1, в виде матрицы смежности (вверху) и списков смежности (внизу) и интерпретируемого как орграф (см. рис. 17.6, вверху).
Часто возникает необходимость привязывать к вершинам или ребрам графа еще больше информации, чтобы графы могли моделировать более сложные объекты. Эту дополнительную информацию можно связать с каждым ребром, расширив тип Edge из программы 17.1, а затем используя экземпляры этого типа в матрицах смежности или в узлах списков смежности. Или, поскольку именами вершин являются целые числа в диапазоне от 0 до V—1, можно воспользоваться векторами, индексированными этими именами, чтобы привязать к вершинам дополнительную информацию -возможно, с помощью соответствующих АТД. Мы рассмотрим такие АТД в лекциях 20—22 . А можно воспользоваться отдельным АТД таблицы символов для привязки дополнительной информации к каждой вершине и к каждому ребру (см. упражнение 17.48 и программу 17.15).
Для решения различных задач обработки графов мы часто определяем классы, которые содержат специальные дополнительные структуры данных, связанные с графами. Из таких структур данных чаще всего применяются векторы, индексированные именами вершин, с которыми мы уже встречались в "Введение" в связи с решением задачи связности. Векторы, индексированные именами вершин, будут часто встречаться в данной книге.
В качестве примера предположим, что нужно узнать, является ли вершина v графа изолированной. Равна ли степень вершины v нулю? При представлении графа списками смежности эту информацию можно получить немедленно, просто проверив, на равенство нулю значение adj[v]. Однако в случае представления матрицей смежности придется проверить все элементы в строке или столбце v, чтобы убедиться, что вершина не соединена ни с какой другой вершиной. А в случае представления графа вектором ребер остается только просмотреть все E ребер, чтобы проверить, содержат ли какие-либо ребра вершину v. Необходимо оградить клиенты от подобных длительных вычислений. Как было сказано в разделе 17.2, один из способов заключается в том, чтобы определить клиентский АТД для задачи, как это сделано в программе 17.11. Эта реализация после предварительной обработки графа за время, пропорциональное размеру его представления, позволит клиентам определить степень любой вершины за постоянное время. Такой способ не дает никакого выигрыша, если клиенту нужно узнать степень только одной вершины, но обеспечивает существенную экономию ресурсов тем клиентам, которые хотят определять значения степеней многих вершин. Существенное различие в производительности алгоритмов решения достаточно простой задачи характерно для обработки графов.
Для каждой задачи обработки графов, рассматриваемой в данной книге, мы инкапсулируем ее решение в аналогичных классах, с приватными данными и общедоступными функциями-членами, специфичными для каждой задачи. Клиенты создают объекты, функции-члены которых и выполняют обработку графов. Такой подход приводит к расширению интерфейса АТД графа с помощью определения набора взаимодействующих классов. Любой набор таких классов определяет интерфейс обработки графов, но каждый инкапсулирует собственные приватные данные и функции-члены.
Программа 17.11. Реализация класса для определения степеней вершин
Этот класс предоставляет способ определения степени любой заданной вершины объекта GRAPH за постоянное время после предварительной обработки в конструкторе за линейное время. Реализация основана на использовании вектора степеней вершин, индексированного именами вершин, в качестве приватного члена и перегрузки операции [] как общедоступной функции-члена. Вначале все элементы обнуляются, а затем выполняется просмотр всех ребер графа с увеличением на единицу соответствующих элементов для каждого ребра.
Подобные классы используются в данной книге при разработке объектно-ориентированных реализаций функций обработки графов как клиентов класса GRAPH.
template <class Graph>
class DEGREE
{ const Graph &G;
vector <int> degree;
public:
DEGREE(const Graph &G) : G(G), degree(G.V(), 0)
{ for (int v = 0; v < G.V(); v++)
{ typename Graph::adjIterator A(G, v);
for (int w = A.beg(); !A.end(); w = A.nxt())
degree[v]++;
}
}
int operator[](int v) const
{ return degree[v]; }
};
Существует много других способов разработки на основе интерфейсов в C++. Одно из направлений дальнейших действий состоит в простом добавлении общедоступных функций-членов (и любых других приватных данных и функций-членов, которые могут потребоваться) в определение базового АТД GRAPH. Такой подход обладает всеми достоинствами, расхваленными в "Абстрактные типы данных" , но ему свойственны и серьезные недостатки, поскольку сфера обработки графов намного шире, чем виды базовых структур данных, которые были рассмотрены в "Абстрактные типы данных" . Вот основные из этих недостатков,
- Количество подлежащих реализации функций обработки графов намного больше количества функций, которые можно аккуратно определить в одном интерфейсе.
- Для простых задач обработки графов приходится использовать те же интерфейсы, что и для сложных задач.
- Одна функция-член может обращаться к данным, предназначенным для использования другой функцией-членом, что противоречит принципу инкапсуляции, которому мы намерены следовать.
Такие интерфейсы называются " толстыми " (fat). В книге, посвященной алгоритмам обработки графов, подобные интерфейсы и в самом деле выглядят " толстыми " .
Другой подход -использование механизма наследования для определения различных типов графов, который предоставляет клиентам различные наборы задач обработки графов. Сравнение тонкостей этого подхода с более простым нашим подходом -полезное занятие при обучении проектированию программного обеспечения, однако оно еще больше отдалит нас от нашей основной цели, изучения алгоритмов обработки графов.
В таблице 17.1 показана зависимость стоимости различных простых операций обработки графов от выбранного представления графа. Эту таблицу следует внимательно изучить, прежде чем переходить к реализации более сложных операций, т.к. она поможет выработать понимание трудности выполнения различных простейших операций. Большинство значений затрат следует непосредственно из анализа программных кодов, за исключением последней строки, которая будет подробно рассмотрена в конце данного раздела.
Производительность основных операций АТД, осуществляющих обработку графов, существенно различается в зависимости от выбора представления графа, даже если рассматривать только простейшие операции. Здесь приведены затраты на выполнение операций в худших случаях (с точностью до постоянного множителя для больших значений V и E). Приведенные стоимости получены для простых реализаций, которые были описаны в предыдущих разделах. А различные модификации, которые могут повлиять на затраты, описываются в данном разделе.
| Массив ребер | Матрица смежности | Списки смежности | |
|---|---|---|---|
| Память | E | V2 | V+E |
| Инициализация пустого объекта | 1 | V2 | V |
| Копирование | E | V2 | E |
| Уничтожение | 1 | V | E |
| Вставка ребра | 1 | 1 | 1 |
| Поиск/удаление ребра | E | 1 | V |
| Вершина v изолирована? | E | V | 1 |
| Существует ли путь от u к v? | E lg*V | V2 | V+E |
Иногда удается модифицировать представление графа, чтобы повысить эффективность простых операций, но при этом нужно следить, чтобы не увеличить стоимость других простых операций. Например, значение в таблице, соответствующее строке " Уничтожение " и столбцу " Матрица смежности " , следует из выбранного нами представления двухмерной матрицы в виде вектора векторов (см. "Элементарные структуры данных" ). Эти затраты нетрудно снизить до постоянной величины (см. упражнение 17.25). Но если ребра графа представляют собой достаточно сложные структуры, для которых требуется хранение указателей в элементах матрицы, то операция уничтожить для матрицы смежности потребует затрат, пропорциональных V2.
Операции найти ребро и удалить ребро часто используются в обычных приложениях, и поэтому мы их рассматриваем более подробно. В частности, операция найти ребро нужна для удаления или блокировки добавления параллельных ребер. Как было показано в "Сбалансированные деревья" , эти операции тривиальны, если использовать представление матрицей смежности -достаточно просто проверить или изменить значение элемента матрицы, который допускает прямую индексацию. Но как обеспечить эффективную реализацию этих операций для представления списками смежности? В языке C++ можно воспользоваться библиотекой STL; здесь мы опишем базовые механизмы, чтобы получить представление о проблемах обеспечения эффективности. Один из подходов описан ниже, а другой -в упражнении 17.50. Оба подхода основаны на использовании реализаций таблицы символов. Например, если мы используем реализации динамической хеш-таблицы (см. "Хеширование" ), то оба подхода потребуют объем памяти, пропорциональный E, и позволяют выполнять обе операции за постоянное время (в среднем, амортизированный подсчет).
В частности, для реализации операции найти ребро при использовании списков смежности можно воспользоваться вспомогательной таблицей символов для ребер. Каждому ребру v-w можно назначить целочисленный ключ v*V+w и воспользоваться контейнером map из библиотеки STL или любой реализацией таблицы символов из части IV (Для неориентированных графов ребрам v-w и w-v можно присваивать одни и те же ключи.) Каждое ребро можно заносить в таблицу символов после предварительной проверки, было ли оно занесено раньше. Можно выбрать как блокировку включения параллельных ребер (см. упражнение 17.49), так и сохранение повторяющихся записей для параллельных ребер в таблице символов (см. упражнение 17.50). Сейчас эта техника интересует нас в основном тем, что она делает возможной реализацию операции найти ребро с постоянным временем выполнения для представления списками смежности.
Чтобы иметь возможность удалять ребра, в записи таблицы символов для каждого ребра необходим указатель на его представление в структуре списков смежности. Но даже этой информации недостаточно для удаления ребра за постоянное время, если только списки не являются дважды связными (см. "Элементарные структуры данных" ). А в случае неориентированных графов нельзя ограничиться лишь удалением узла из списка смежности, поскольку каждое ребро содержится в двух различных списках. Одним из решений является помещение в таблицу символов обоих указателей; другое основано на связывании двух узлов, соответствующих конкретному ребру (см. упражнение 17.46). Любое из этих решений обеспечивает удаление ребра за постоянное время.
Удаление вершин требует больших затрат. В представлении матрицей смежности придется удалить из матрицы соответствующие строку и столбец, что не менее сложно, чем построение новой матрицы смежности меньшего размера (хотя эту сложность можно уменьшить с помощью того же механизма, что и для динамических хеш-таблиц). В случае представления списками смежности понятно, что недостаточно просто удалить узлы из списка смежности данной вершины, поскольку каждый узел списка смежности указывает на другую вершину, список смежности которой необходимо просмотреть, чтобы удалить другой узел, представляющий то же ребро. Если мы хотим удалять вершины за время, пропорциональное количеству вершин V, то для этого потребуются дополнительные ссылки, как описано в предыдущем абзаце.
Мы не будем здесь останавливаться на реализации этих операций, т.к. они представляют собой простые упражнения по программированию с использованием базовых технологий из части I -поскольку библиотека STL содержит необходимые для этого реализации, поскольку сложные структуры с несколькими указателями на узел не стоит применять в обычных приложениях обработки статических графов, и поскольку мы не хотим утонуть в уровнях абстракции или в деталях использования нескольких указателей при реализации алгоритмов обработки графов. В "Потоки в сетях" мы все же рассмотрим реализации подобных структур, играющих важную роль в мощных универсальных алгоритмах, которые мы начнем изучать в данной главе.
Для ясности описания и реализаций интересующих нас алгоритмов мы воспользуемся простейшим из подходящих представлений. Обычно мы стремимся использовать структуры данных, которые непосредственно соответствуют решаемым задачам. Многие программисты придерживаются такого естественного минимализма, понимая, что поддержка целостности данных с многочисленными неравноценными компонентами серьезно усложняет задачу.
Можно также рассмотреть альтернативные реализации, которые изменяют базовые структуры данных для экономии памяти или времени выполнения при обработке больших графов (или большого количества маленьких). Например, можно существенно повысить производительность алгоритмов обработки больших статических графов, представленных списками смежности, заменив представление множества вершин, инцидентных каждой конкретной вершине, со списков смежности на векторы переменной длины. Это позволит представить граф всего лишь 2E целыми числами, что меньше V, и еще V целыми числами, что меньше V2 (см. упражнения 17.52 и 17.54). Подобные представления удобны для обработки больших статических графов.
Алгоритмы, которые мы рассматриваем, легко адаптировать ко всем изменениям, предложенным в этом разделе, поскольку они основаны на нескольких высокоуровневых абстрактных операциях, таких как " выполнить следующую операцию для каждого ребра, связанного с вершиной v " , которые поддерживаются нашим базовым АТД.
Иногда решения относительно структуры алгоритма зависят от некоторых свойств представления данных. Работа на высоком уровне абстракции может замаскировать эту зависимость. Если мы знаем, что одно представление ведет к снижению производительности, а другое нет, то рассмотрение алгоритма на неверном уровне абстракции является неоправданным риском. Как обычно, наша цель состоит в создании таких реализаций, которые позволяют дать точную оценку их производительности. По этой причине мы сохраняем отдельные типы DenseGRAPH (насыщенный граф) и SparseMultiGRAPH (разреженный мультиграф) для представления графа, соответственно, матрицей смежности и списками смежности, чтобы клиенты могли воспользоваться той реализацией, которая лучше подходит для решения их задачи.
Все уже рассмотренные нами операции представляют собой простые, хотя и необходимые функции обработки данных, и итогом обсуждения в данном разделе является то, что базовые алгоритмы и структуры данных из частей I—III обеспечивают их эффективную работу. По мере разработки все более сложных алгоритмов обработки графов нам будет все труднее находить лучшие представления для конкретных практических задач. Для иллюстрации рассмотрим последнюю строку таблица 17.1, где указана стоимость определения наличия пути между двумя заданными вершинами.
В худшем случае простой алгоритм выбора пути, описанный в разделе 17.7 (а также несколько других методов, которые будут рассмотрены в "Поиск на графе" ), просматривает все E ребер графа. Данные в среднем и правом столбцах нижней строки таблицы 17.1 показывают, соответственно, что этот алгоритм может проверить все V2 элементов представления матрицей смежности, либо все V ведущих узлов списков и все E узлов в списках в случае представления списками смежности. Из этого следует, что время выполнения алгоритма линейно зависит от размера представления графа, однако имеются два исключения из этого правила, в худшем случае время выполнения перестает быть линейным. Это происходит, если использовать матрицу смежности для разреженного графа или любое представление для очень разреженного графа (с большим количеством изолированных вершин). Чтобы больше не останавливаться на этих исключениях, в дальнейшем мы полагаем, что размер используемого представления графа пропорционален количеству ребер этого графа. В большинстве практических приложений это предположение весьма спорно, поскольку в них часто выполняется обработка очень больших разреженных графов и, следовательно, удобнее представление списками смежности.
Значение в нижней строке левого столбца таблицы 17.1 получено для алгоритмов объединения-поиска, описанных в "Введение" (см. упражнение 17.15). Этот метод привлекателен тем, что необходимый для него объем памяти пропорционален лишь V, однако он не способен находить пути. Этот элемент таблицы 17.1 подчеркивает важность полного и точного описания задач обработки графов.
Даже после того как все эти факторы будут учтены, остается еще одна из наиболее важных и трудных задач, с которыми нам приходится сталкиваться при разработке практических алгоритмов обработки графов -оценка того, насколько результаты анализа этих алгоритмов для худшего случая (наподобие значений в таблице 17.1) переоценивают потребность во времени и в памяти для реальных графов. В статьях по алгоритмам на графах обычно описывается производительность, гарантируемая в худшем случае. Эта информация полезна для отсеивания алгоритмов с заведомо неприемлемыми характеристиками, но она не всегда может подсказать, какая из нескольких простых программ наиболее подходит в конкретном случае. Эта ситуация усугубляется трудностями разработки полезных моделей средней производительности алгоритмов на графах, и нам остаются (без каких-либо гарантий) только эмпирическое тестирование и (возможно, слишком консервативные) гарантии производительности в худшем случае. Например, все методы поиска на графах, которые рассматриваются в "Поиск на графе" , представляют собой эффективные линейные по времени алгоритмы для поиска пути между двумя заданными вершинами, однако их характеристики производительности существенно различаются в зависимости от вида обрабатываемого графа и его представления. При использовании алгоритмов обработки графов приходится постоянно балансировать между гарантиями для худшего случая, которые можно доказать, и реальной ожидаемой производительностью. С этой темой мы будем постоянно сталкиваться на протяжении всей книги.
Упражнения
17.39. Разработайте представление матрицей смежности для насыщенных мультиграфов и напишите реализацию АТД для использующей его программы 17.1.
17.40. Почему не стоит использовать прямое представление графов (структура данных, которая точно моделирует граф с объектами-вершинами, содержащими списки смежности со ссылками на эти вершины)?
17.41. Почему программа 17.11 не увеличивает на единицу оба значения deg[v] и deg[w], когда она обнаруживает, что вершина v смежна с w?
17.42. Добавьте в класс графа на основе матрицы смежности (программа 17.7) вектор, индексированный именами вершин, который содержит степени каждой вершины. Добавьте общедоступную функцию-член degree, которая возвращает степень заданной вершины.
17.43. Выполните упражнение 17.43 для представления списками смежности.
17.44. Добавьте в таблицу 17.1 строку для задачи определения количества изолированных вершин в графе. Дополните ответ реализациями функций для каждого из трех представлений.
17.45. Добавьте в таблицу 17.1 строку для задачи определения, содержит ли заданный орграф вершину со степенью захода V и степенью выхода 0. Дополните ответ реализациями функций для каждого из трех представлений. Примечание, значение для представления матрицей смежности должно быть равно V.
17.46. Воспользуйтесь двусвязными списками смежности с перекрестными ссылками (см. текст) для реализации функции remove, выполняющей операцию удалить ребро за постоянное время для реализации АТД графа, в которой используются списки смежности (программа 17.9).
17.47. Добавьте функцию remove, выполняющую операцию удалить вершину, в класс графа, представленного двусвязными списками смежности, из предыдущего упражнения.
17.48. Измените решение упражнения 17.16, чтобы в нем использовалась динамическая хеш-таблица (см. описание в тексте), и операции вставить ребро и удалить ребро выполнялись за постоянное (в среднем) время.
17.49. Добавьте в класс графа, в котором используются списки смежности (программа 17.9), таблицу символов для блокировки параллельных ребер, чтобы этот класс представлял простые графы, а не мультиграфы. В реализации таблицы символов используйте динамическое хеширование, чтобы полученные реализации занимали объем памяти, пропорциональный E, и выполняли вставку, поиск и удаление ребер за постоянное (в среднем) время.
17.50. Разработайте класс мультиграфа на основе представления вектором таблиц символов (по одной таблице символов на каждую вершину, содержащую список смежных ребер). В реализации таблицы символов используйте динамическое хеширование, чтобы полученные реализации занимали объем памяти, пропорциональный E, и выполняли вставку, поиск и удаление ребер за постоянное (в среднем) время.
17.51. Разработайте АТД графа, ориентированный на статические графы, в котором конструктор принимает в качестве аргумента вектор ребер и использует для построения графов базовый АТД графа. (Такая реализация может оказаться полезной для сравнения производительности с реализациями из упражнений 17.52—17.55.)
17.52. Разработайте реализацию конструктора, описанного в упражнении 17.51, которая использует компактное представление графа на основе следующих структур данных,
struct node { int cnt; vector <int> edges; };
struct graph { int V; int E; vector <node> adj; };
Граф есть совокупность счетчика вершин, счетчика ребер и вектора вершин. Вершина содержит счетчик ребер и вектор с одним индексом вершины для каждого смежного ребра.
17.53. Добавьте в решение упражнения 17.52 функцию для удаления петель и параллельных ребер, как в упражнении 17.34.
17.54. Разработайте реализацию АТД статического графа, описанного в упражнении 17.51, которая использует для представления графа только два вектора, один -вектор E вершин, второй -вектор V индексов или указателей на элементы первого вектора. Реализуйте функцию io::show для этого представления.
17.55. Добавьте в решение упражнения 17.54 функцию для удаления петель и параллельных ребер, как в упражнении 17.34.
17.56. Разработайте интерфейс АТД графа, который связывает с каждой вершиной координаты (x, y), что позволит работать с чертежами графов. Включите в интерфейс функции drawV и drawE для вычерчивания, соответственно, вершин и ребер.
17.57. Напишите клиентскую программу, которая использует интерфейс из упражнения 17.56 для вычерчивания ребер, добавляемых в небольшой граф.
17.58. Разработайте реализацию интерфейса из упражнения 17.56, генерирующую PostScript-программу для вычерчивания графов (см. "Абстрактные типы данных" ).
17.59. Найдите графический интерфейс, подходящий для реализации интерфейса из упражнения 17.56, который позволит непосредственно выводить чертежи графов в специальном окне.
17.60. Включите в решение упражнений 17.56 и 17.59 функции стирания вершин и ребер и вычерчивания их различными стилями, которые позволят писать клиентские программы для динамического графического отображения работы алгоритмов обработки графов.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |