|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2177 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 12:
Таблицы символов и деревья бинарного поиска
Индексные реализации таблиц символов
Во многих приложениях необходимо выполнять поиск в структуре, чтобы просто найти элемент, но не перемещать его. Например, может существовать массив элементов с ключами, для которого требуется метод поиска, определяющий индекс элемента в массиве, который соответствует заданному ключу. Может также требоваться удаление элемента с данным индексом из структуры поиска, но с сохранением в массиве для какого-либо другого применения. В "Очереди с приоритетами и пирамидальная сортировка" были рассмотрены преимущества обработки индексированных элементов в очередях с приоритетами, где выполняется косвенное обращение к данным клиентского массива. Применительно к таблицам символов эта же концепция приводит к уже знакомым индексам - внешней по отношению к набору элементов поисковой структуре, которая обеспечивает быстрый доступ к элементам с данным ключом. В "Внешний поиск" будет рассматриваться случай, когда элементы и, возможно, даже индексы хранятся во внешней памяти; в этом разделе мы кратко ознакомимся со случаем, когда и элементы, и индексы находятся в оперативной памяти.
Деревья бинарного поиска можно определить таким образом, чтобы индексы строились в точности так же, как при обеспечении косвенной сортировки в "Элементарные методы сортировки" и для пирамидальных деревьев в "Очереди с приоритетами и пирамидальная сортировка" : мы используем оболочку Index для определения элементов BST-дерева и обеспечим извлечение ключей из элементов, как обычно, через функцию-член key. А для ссылок можно задействовать параллельный массив, как это было сделано для связных списков в "Элементарные структуры данных" . Мы будем использовать три массива: для элементов, левых ссылок и правых ссылок. Ссылки являются (целочисленными) индексами массивов, и обращения вроде
x = x->l
во всем коде заменяются на обращения
x = l[x]
Этот подход устраняет затраты на динамическое распределение памяти для каждого узла - элементы занимают массив независимо от функции поиска, и для хранения ссылок дерева заранее выделены два целочисленных значения на каждый элемент. Память под ссылки используется не всегда, но она готова для использования подпрограммой поиска, не требуя дополнительного времени на выделение. Другая важная особенность этого подхода заключается в том, что здесь возможно добавление добавочных массивов (содержащих дополнительную связанную с каждым узлом информацию) без какого-либо изменения кода работы с деревом. Когда подпрограмма поиска возвращает индекс элемента, она предоставляет способ немедленного доступа ко всей информации, связанной с этим элементом - ведь этого индекса достаточно для доступа к соответствующему массиву.
Такой способ реализации BST-деревьев как средства упрощения поиска в больших массивах элементов иногда весьма полезен, поскольку исключает дополнительные затраты на копирование элементов во внутреннее представление АТД и излишние действия по их размещению и созданию операцией new. Использование массивов не годится, когда объем памяти играет первостепенную роль, а таблица символов увеличивается и уменьшается в значительных пределах. В особенности это актуально, если заранее трудно оценить максимальный размер таблицы символов. В таком случае неиспользуемые ссылки в массиве элементов могут привести к напрасному расходу памяти.
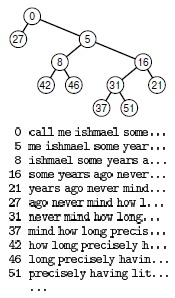
Важное применение концепции индексирования - поиск ключевых слов в строке текста (см. рис. 12.11). Программа 12.11 является примером такого приложения. Она считывает текстовую строку из внешнего файла, а затем, считая, что каждая позиция в этой строке определяет строковый ключ, начинающийся с данной позиции и до конца строки, она вставляет все такие ключи в таблицу символов, используя указатели на строки. Подобное применение строковых ключей отличается от определения типа строкового элемента (например, как в упражнении 12.2), поскольку никакое выделение памяти не выполняется. Используемые ключи имеют произвольную длину, но мы работаем только с указателями на них и просматриваем лишь то количество символов, которое необходимо для определения, какая из двух строк должна следовать первой. Никакие две строки не совпадают (например, все они имеют различную длину), но если изменить операцию ==, чтобы считать строки равными, когда одна из них является префиксом второй, то можно воспользоваться простым вызовом search для таблицы символов, чтобы выяснить, присутствует ли данная строка в тексте.
Программа 12.11. Пример индексирования текстовой строки
В этой программе считается, что в файле Item.cxx определены представление данных char* для строковых ключей в элементах, перегруженная операция <, которая использует функцию strcmp, перегруженная операция ==, которая использует функцию strncmp, и оператор преобразования из Item в char* (см. текст). Главная программа считывает текстовую строку из указанного файла и использует таблицу символов для построения индекса из строк, начинающихся в каждой позиции текстовой строки. Затем она считывает из стандартного ввода запрашиваемые строки и выводит позицию, в которой они найдены в тексте (или выводит строку не найдено). При реализации таблицы символов на основе BST-дерева поиск выполняется быстро даже для очень больших строк.
#include <iostream.h>
#include <fstream.h>
#include "Item.cxx"
#include "ST.cxx"
static char text[maxN];
int main(int argc, char *argv[])
{ int N = 0; char t;
ifstream corpus; corpus.open(*++argv);
while (N < maxN && corpus.get(t)) text[N++] = t;
text[N] = 0;
ST<Item, Key> st(maxN);
for (int i = 0; i < N; i++) st.insert(&text[i]);
char query[maxQ]; Item x, v(query);
while (cin.getline(query, maxQ))
if ((x = st.search(v.key())).null())
cout << "не найдено: " << query << endl;
else
cout << x-text << ": " << query << endl;
}
В этом примере индекса строки строковый ключ определен так, чтобы он начинался с каждого слова в тексте; затем строится BST-дерево с помощью обращения к ключам по их индексам в строке. В принципе, ключи имеют произвольную длину, но на практике обычно просматриваются только несколько начальных символов. Например, для определения того, встречается ли в этом тексте фраза never mind, она сравнивается с call... в корне (индекс 0), затем с me... в правом дочернем узле корня (индекс 5), затем с some... в правом дочернем узле этого узла (индекс 16), а затем в левом дочернем узле предпоследнего узла (индекс 31) обнаруживается и never mind.
Программа 12.11 последовательно считывает запросы из стандартного ввода, вызывает функцию search для определения присутствия запрашиваемых строк в тексте и выводит позицию первого совпадения с запросом. Если таблица символов реализована на основе BST-дерева, то в соответствии с леммой 12.6 можно ожидать, что для поиска потребуется порядка 2NlnN сравнений. Например, после построения индекса любую фразу в тексте, состоящем приблизительно из 1 миллиона символов, можно найти с помощью около 30 операций сравнения строк. Это приложение равносильно индексированию, поскольку указатели C-строк являются индексами массива символов: если x указывает на text[i], то разность двух указателей x-text равна i.
При построении индексов в реальных приложениях потребуется учесть и множество других моментов. Существует немало способов, использующих конкретные преимущества строковых ключей для ускорения работы алгоритмов. Более сложным методам поиска строк и создания индексов с дополнительными полезными возможностями в основном посвящена часть 5.
В таблица 12.2 сведены результаты экспериментальных исследований, подтверждающие приведенные аналитические рассуждения и демонстрирующие применение деревьев бинарного поиска для работы с динамическими таблицами символов со случайными ключами.
В этой таблице приведены относительные времена создания таблицы символов и затем поиска каждого ключа в таблице. Деревья бинарного поиска обеспечивают быстрые реализации поиска и вставки; при использовании всех других методов для выполнения одной из этих двух задач требуется квадратичное время. Обычно бинарный поиск выполняется несколько быстрее поиска в BST-дереве, но он неприменим к очень большим файлам, если только таблицу нельзя предварительно отсортировать. Стандартная реализация BST-дерева выделяет память для каждого узла дерева, а реализация с использованием индексов предварительно выделяет память для всего дерева (что ускоряет создание), и вместо указателей использует индексы массивов (что замедляет поиск).
| N | Создание | Успешный поиск | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| A | L | B | T | T* | A | L | B | T | T* | |
| 1250 | 1 | 5 | 6 | 1 | 0 | 6 | 13 | 0 | 1 | 1 |
| 2500 | 0 | 21 | 24 | 2 | 1 | 27 | 52 | 1 | 1 | 1 |
| 5000 | 0 | 87 | 101 | 4 | 3 | 111 | 211 | 2 | 2 | 3 |
| 12500 | 645 | 732 | 12 | 9 | 709 | 1398 | 7 | 8 | 9 | |
| 25000 | 2551 | 2917 | 24 | 20 | 2859 | 5881 | 15 | 21 | ||
| 50000 | 61 | 50 | 38 | 48 | ||||||
| 100000 | 154 | 122 | 104 | 122 | ||||||
| 200000 | 321 | 275 | 200 | 272 | ||||||
| Обозначения: | |
| A | Неупорядоченный массив (упражнение 12.20) |
| L | Упорядоченный связный список (упражнение 12.21) |
| B | Бинарный поиск (программа 12.7) |
| T | Дерево бинарного поиска, стандартное (программа 12.8) |
| T* | Индексное дерево бинарного поиска (упражнение 12.67) |
Упражнения
12.66. Измените реализацию BST-дерева из программы 12.8, чтобы использовать индексированный массив элементов, а не выделенную память. Сравните производительность полученной программы с производительностью стандартной реализации, воспользовавшись драйвером из упражнения 12.23 или упражнения 12.24.
12.67. Измените реализацию BST-дерева из программы 12.8, чтобы она поддерживала АТД символьной таблицы с клиентскими дескрипторами элементов (см. упражнение 12.7), используя параллельные массивы. Сравните производительность полученной программы с производительностью стандартной реализации, воспользовавшись драйвером из упражнения 12.23 или упражнения 12.24.
12.68. Измените реализацию BST-дерева из программы 12.8 следующим образом: используйте массив элементов с ключами и массив ссылок (по одной для каждого элемента) в узлах дерева. Левая ссылка в BST-дереве соответствует перемещению в следующую позицию в массиве в узле дерева, а правая ссылка в BST-дереве соответствует перемещению в другой узел дерева.
12.69. Приведите пример текстовой строки, где количество строковых сравнений для этапа создания индекса в программе 12.11 квадратично зависит от длины строки.
12.70. Измените реализацию индексирования строки (программа 12.11), чтобы для построения индекса использовались только ключи, начинающиеся на границах слов (см. рис. 12.11). (Для книги " Моби Дик " это изменение уменьшает размер индекса более чем в пять раз.)
12.71. Реализуйте версию программы 12.11, в которой используется бинарный поиск в массиве указателей на строки с помощью реализации из упражнения 12.38.
12.72. Сравните время выполнения вашей реализации из упражнения 12.71 с программой 12.11 при построении индекса для случайной текстовой строки из N символов, для N = 103, 104, 105 и 106, и при выполнении 1000 (неудачных) поисков для случайных ключей в каждом индексе.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |