Опубликован: 02.02.2011 | Доступ: свободный | Студентов: 3407 / 1001 | Оценка: 4.43 / 3.57 | Длительность: 33:06:00
Тема: Программирование
Специальности: Программист
Лекция 34:
Алгоритмы обработки данных
Аннотация: В лекции рассматривается понятие ресурсной эффективности алгоритмов посредством анализа асимптотических функций временной и емкостной сложности, приводится классификация алгоритмов на основе функции временной сложности, рассматриваются общие методы оценки трудоемкости алгоритмов.
Ключевые слова: входные данные, разбиение, алгоритм, Visual Studio, функция, сортировка массива, переносимость, адаптация, эффективность алгоритма, определение, Емкостная сложность, анализ, параметр, время выполнения, класс, запись, константы, входной параметр, процедурное программирование, ветвление, вероятности перехода, тело цикла, цикл с предусловием, постусловие, вложенные циклы, декомпозиция, композиция функций, затраты, фактический параметр, единица, операции, пузырьковая сортировка, биномиальные коэффициенты, обращение к функции, значение, вызов функции, сбалансированное дерево, хеширование, связность, кратчайший путь, остовное дерево, Паросочетание, синтаксический анализ, выпуклая оболочка, представление, стратегия обхода, переполнение, делитель, алгоритм Евклида
Цель лекции: изучить понятие и классификации алгоритмов обработки данных, трудоемкости алгоритмов и методов ее оценки, научиться выработке критериев и оценке трудоемкости алгоритмов с учетом критериев на примере реализаций и задач на языке C++.
Понятие "алгоритм обработки данных" в компьютерных науках используется для описания метода решения задачи, который в дальнейшем возможно реализовать в выбранной среде программирования. Тщательная разработка алгоритма является весьма эффективной частью процесса решения задачи в любой области применения. При разработке алгоритма для реальной задачи значительные усилия должны быть потрачены на осознание степени ее сложности, выяснение ограничений на входные данные, разбиение задачи на менее трудоемкие подзадачи.
Алгоритм не должен быть привязан к конкретной реализации. В силу разнообразия используемых средств программирования, их требований к аппаратным ресурсам и платформенной зависимости сходные по структуре, но различные в реализации, алгоритмы могут выдавать отличающиеся по эффективности результаты. При этом некоторые среды программирования содержат встроенные библиотечные функции, реализующие базовые алгоритмы обработки данных (например, в MS Visual Studio 2010 в библиотеки С++ входит функция быстрой сортировки массивов данных). Чтобы решения были переносимыми и оставались актуальными, не рекомендуется их ориентировать на процедурную реализацию среды. Поэтому главным в рассматриваемом подходе является выбор метода решения с учетом специфики задачи. Адаптация к среде осуществляется позднее.
Выбор того или иного метода обработки данных определяется не только сложностью задачи. Учитывать необходимо и массовость применения разработанного кода: при однократном или редком обращении к реализации предпочтительнее бывают простые алгоритмы, которые несложны в разработке. При этом, однако, допускается возможным увеличение времени работы программы.
Массовое использование алгоритмов обработки данных требует поиска наилучшего алгоритма решения. Такой процесс бывает весьма сложен, так как требует выработки критериев оценки и применения математических методов для получения количественных характеристик. Направление компьютерных наук, занимающееся изучением оценки эффективности алгоритмов, называется анализом алгоритмов.
Ресурсная эффективность алгоритмов
Определение ресурсной эффективности алгоритмов – необходимая составляющая этапа анализа разработанного программного обеспечения. Повышение ресурсной эффективности вычислительных алгоритмов актуально при обработке больших объемов данных, когда аппаратных и/или программных ресурсов может быть недостаточно для корректного завершения работы программного кода.
Наиболее значимыми характеристиками ресурсной эффективности алгоритмов являются оценки временной и емкостной сложности, отражающие ресурсы процессора, оперативной памяти, а также внешних носителей данных (при использовании).
Под трудоемкостью алгоритма А на входе D будем понимать количество элементарных операций, которые учитываются при анализе алгоритма. Под худшим случаем трудоемкости понимают наибольшее количество операций, задаваемых алгоритмом А на всех входах D определенной размерности n. Определим лучший случай трудоемкости, как наименьшее количество операций в аналогичном алгоритме и при той же размерности входа. Средний случай трудоемкости определяется средним количеством операций рассматриваемого алгоритма и входных данных. Зависимость трудоемкости алгоритма А от значения параметров на входе D определяет функцию трудоемкости алгоритма А для входа D.
Классический анализ алгоритмов в данном контексте связан, прежде всего, с оценкой временной сложности. Большинство алгоритмов имеют основной параметр, который в значительной степени влияет на время выполнения операций. Если же определяющих параметров несколько, то, как правило, один их них выражается как функция от остальных. Иногда используют и такой подход: рассматривают только один параметр, считая остальные константами.
Результатом анализа является асимптотическая оценка выполняемых алгоритмом операций в зависимости от длины входа, которая указывает порядок роста функции и результаты сравнения работы алгоритмов для больших данных. При этом оценка на реальных данных отличается от асимптотической тем, что она ориентирована на конкретные длины входов и число выполняемых алгоритмом операций.
Временная сложность алгоритма определяется асимптотической оценкой функции трудоемкости алгоритма для худшего случая, обозначается O(f(n)) и читается как "О большое" или "О-нотация". Асимптотический класс функций О включает в себя как средний, так и лучший случай, потому что запись O(f(n)) обозначает класс функций, скорость роста которых не более, чем f(n) с точностью до некоторой положительной константы. В зависимости от вида функции f(n) выделяют следующие классы сложности алгоритмов.
| Вид f(n) | Характеристика класса алгоритмов |
|---|---|
| 1 | Большинство инструкций большинства функций запускается один или несколько раз. Если все инструкции программы обладают таким свойством, то время выполнения программы постоянно. |
| log N | Когда время выполнения программы является логарифмическим, программа становится медленнее с ростом N. Такое время выполнения обычно присуще программам, которые сводят большую задачу к набору меньших подзадач, уменьшая на каждом шаге размер задачи на некоторый постоянный фактор. Будем рассматривать время выполнения, являющееся небольшой по величине константой. Изменение основания не сильно сказывается на изменении значения логарифма: при N=1 000, log N = 3, если основание равно 10, или порядка 10, если основание равно 2; когда N=1 000 000, значения log N увеличивается в два раза. При удвоении значения параметра log N растет на постоянную величину, а удваивается лишь тогда, когда N достигает N2. |
| N | Когда время выполнения программы является линейным, это обычно значит, что каждый входной элемент подвергается небольшой обработке. Когда N равно миллиону, таким же и является время выполнения. Когда N удваивается, то же происходит и со временем выполнения. Эта ситуация оптимальна для алгоритма, который должен обработать N вводов (или произвести N выводов). |
| N log N | Время выполнения, пропорциональное N log N, возникает тогда, когда алгоритм решает задачу, разбивая ее на меньшие подзадачи, решая их независимо и затем объединяя решения. Время выполнения такого алгоритма равно N log N. Когда N=1 000 000, 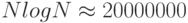 . Когда N удваивается, тогда время выполнения более чем удваивается. . Когда N удваивается, тогда время выполнения более чем удваивается. |
| N2 | Когда время выполнения алгоритма является квадратичным, он полезен для практического использования при решении относительно небольших задач. Квадратичное время выполнения обычно появляется в алгоритмах, которые обрабатывают все пары элементов данных (возможно, в цикле двойного уровня вложенности). Когда N=1 000, время выполнения равно одному миллиону. Когда N удваивается, время выполнения увеличивается вчетверо. |
| N3 | Похожий алгоритм, который обрабатывает тройки элементов данных (возможно, в цикле тройного уровня вложенности), имеет кубическое время выполнения и практически применим лишь для малых задач. Когда N=100, время выполнения равно одному миллиону. Когда N удваивается, время выполнения увеличивается в восемь раз. |
| 2N | Лишь несколько алгоритмов с экспоненциальным временем выполнения имеет практическое применение, хотя такие алгоритмы возникают естественным образом при попытках прямого решения задачи, например полного перебора. Когда N=20, время выполнения имеет порядок одного миллиона. Когда N удваивается, время выполнения увеличивается экспоненциально. |
На основании математических методов исследования асимптотических функций трудоемкости на бесконечности выделены пять классов алгоритмов.
Класс 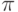 0 – это класс быстрых алгоритмов с постоянным временем выполнения, их функция трудоемкости O(1). Промежуточное состояние занимают алгоритмы со сложностью O(log N), которые также относят к данному классу.
0 – это класс быстрых алгоритмов с постоянным временем выполнения, их функция трудоемкости O(1). Промежуточное состояние занимают алгоритмы со сложностью O(log N), которые также относят к данному классу.
Класс Р – это класс рациональных или полиномиальных алгоритмов, функция трудоемкости которых определяется полиномиально от входных параметров. Например, O(N), O(N2), O(N3).
Класс L – это класс субэкспоненциальных алгоритмов со степенью трудоемкости O(N log N).
Класс E – это класс собственно экспоненциальных алгоритмов со степенью трудоемкости O(2N).
Класс F – это класс собственно надэкспоненциальных алгоритмов. Существуют алгоритмы с факториальной трудоемкостью, но они в основном не имеют практического применения.
Состояние памяти при выполнении алгоритма определяется значениями, требующими для размещения определенных участков. При этом в ходе решения задачи может быть задействовано дополнительное количество ячеек. Под объемом памяти, требуемым алгоритмом А для входа D, понимаем максимальное количество ячеек памяти, задействованных в ходе выполнения алгоритма. Емкостная сложность алгоритма определяется как асимптотическая оценка функции объема памяти алгоритма для худшего случая.
Таким образом, ресурсная сложность алгоритма в худшем, среднем и лучшем случаях определяется как упорядоченная пара классов функций временной и емкостной сложности, заданных асимптотическими обозначениями и соответствующих рассматриваемому случаю.