Опубликован: 02.02.2011 | Доступ: свободный | Студентов: 3392 / 993 | Оценка: 4.43 / 3.57 | Длительность: 33:06:00
Тема: Программирование
Специальности: Программист
Лекция 34:
Алгоритмы обработки данных
Методы оценки ресурсной эффективности алгоритмов
Основными алгоритмическими конструкциями в процедурном программировании являются следование, ветвление и цикл. Для получения функций трудоемкости для лучшего, среднего и худшего случаев при фиксированной размерности входа необходимо учесть различия в оценке основных алгоритмических конструкций.
- Трудоемкость конструкции "Следование" есть сумма трудоемкостей блоков, следующих друг за другом: f=f1+f2+...+fn.
- Трудоемкость конструкции "Ветвление" определяется через вероятность перехода к каждой из инструкций, определяемой условием. При этом проверка условия также имеет определенную трудоемкость. Для вычисления трудоемкости худшего случая может быть выбран тот блок ветвления, который имеет большую трудоемкость, для лучшего случая – блок с меньшей трудоемкостью. fif=f1+fthenxpthen+felsex(1-pthen)
- Трудоемкость конструкции "Цикл" зависит от вида цикла. Для цикла с параметрами будет справедливой формула: ffor=1+3n+nf, где n – количество повторений тела цикла, f – трудоемкость тела цикла.
Реализация цикла с предусловием и с постусловием не меняет методики оценки его трудоемкости. На каждом проходе выполняется оценка трудоемкости условия, изменения параметров (при наличии) и тела цикла. Общие рекомендации для оценки циклов с условиями затруднительны. Так как в значительной степени зависят от исходных данных.
- В случае использования вложенных циклов их трудоемкости перемножаются.
Таким образом, для оценки трудоемкости алгоритма может быть сформулирован общий метод получения функции трудоемкости.
- Декомпозиция алгоритма предполагает выделение в алгоритме базовых конструкций и оценку их трудоемкости. При этом рассматривается следование основных алгоритмических конструкций.
- Построчный анализ трудоемкости по базовым операциям языка подразумевает либо совокупный анализ (учет всех операций), либо пооперационный анализ (учет трудоемкости каждой операции).
- Обратная композиция функции трудоемкости на основе методики анализа базовых алгоритмических конструкций для лучшего, среднего и худшего случаев.
Особенностью оценки ресурсной эффективности рекурсивных алгоритмов является необходимость учета дополнительных затрат памяти и механизма организации рекурсии. Поэтому трудоемкость рекурсивных реализаций алгоритмов связана с количеством операций, выполняемых при одном рекурсивном вызове, а также с количеством таких вызовов. Учитываются также затраты на возвращения значений и передачу управления в точку вызова. Для анализа трудоемкости механизма рекурсивного вызова-возврата будем учитывать следующие параметры: p – количество передаваемых фактических параметров, r – количество сохраняемых в стеке регистров, k – количество возвращаемых по адресной ссылке значений, l – количество локальных ячеек функции. Тогда функция трудоемкости на один вызов-возврат примет вид:
f=2(p+k+r+l+1),
где дополнительная единица учитывает операции с адресом возврата.
Оценка требуемой памяти стека может быть получена следующим образом: так как рекурсивные вызовы обрабатываются последовательно, то в конкретный момент времени в стеке хранится не фрагмент дерева рекурсии, а цепочка рекурсивных вызовов – унарный фрагмент дерева. Поэтому объем стека определяется максимально возможным числом одновременно полученных рекурсивных вызовов.
Анализ совокупной трудоемкости рекурсивного алгоритма можно выполнять разными способами в зависимости от формирования итоговой суммы базовых операций: по цепочкам рекурсивных вызовов и возвратов, по вершинам рекурсивного дерева.
Пример 1. Оценка временной сложности функции пузырьковой сортировки.
//Описание функции сортировки методом "пузырька"
void BubbleSort (int k,int x[max]) {
int i,j,buf;
for (i=k-1;i>0;i--)
for (j=0;j<i;j++)
if (x[j]>x[j+1]) {
buf=x[j];
x[j]=x[j+1];
x[j+1]=buf;
}
}Оценим временную сложность функции пузырьковой сортировки в худшем случае, т.е. когда исходные данные отсортированы в обратном порядке. В этом случае внутренний цикл для каждого i выполнится i-1 раз и произойдет 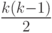 обменов. Соответственно сложность алгоритма в худшем случае составит O(k2) обменов.
обменов. Соответственно сложность алгоритма в худшем случае составит O(k2) обменов.
Оценим временную сложность алгоритма пузырьковой сортировки в среднем случае, т.е. когда исходные данные имеют произвольный порядок. В этом случае условие во внутреннем цикле может выполниться 1,2,...,i-1 раз. Складывая, получим  и, соответственно, условие во внутреннем цикле для каждого i выполнится в среднем
и, соответственно, условие во внутреннем цикле для каждого i выполнится в среднем 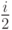 раз и произойдет
раз и произойдет 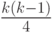 обменов. Соответственно сложность алгоритма в среднем случае составит O(k2).
обменов. Соответственно сложность алгоритма в среднем случае составит O(k2).
Пример 2. Оценка временной сложности функции вычисления биномиального коэффициента 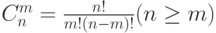 .
.
//Описание функции вычисления биномиального коэффициента
int Binom (int n,int m) {
if (m==0) return 1; //база рекурсии
return Binom(n-1,m-1)*n/m; //декомпозиция
}Оценим временную сложность функции в худшем случае, т.е. когда m=n. Будет выполнено ( n+1 ) обращений к функции, которая выполнит в n случаях три операции, а в одном возвратит значение. Функция при каждом обращении передает два параметра, не использует локальных переменных, а при возвращении ( n+1 ) раз передает управление в точку вызова. Соответственно сложность алгоритма в худшем случае составит O(n) или O(m).
Оценим временную сложность функции в среднем случае, т.е. когда m<n. При этом выполняются рассуждения, аналогичные худшему случаю, только количество рекурсивных вызовов составит ( m+1 ). Соответственно сложность алгоритма в среднем случае составит O(m).
Лучший случай достигается при m=0, когда выполняется единственный вызов функции, передача двух параметров и возвращение в точку вызова, то есть оценка лучшего случая O(1).
Базовые алгоритмы обработки данных
Базовые алгоритмы обработки данных являются результатом исследований и разработок, проводившихся на протяжении десятков лет. Но они, как и прежде, продолжают играть важную роль во все расширяющемся применении вычислительных процессов.
К базовым алгоритмам процедурного программирования можно отнести:
- Алгоритмы работы со структурами данных. Они определяют базовые принципы и методологию, используемые для реализации, анализа и сравнения алгоритмов. Позволяют получить представление о методах представления данных. К таким структурам относятся связные списки и строки, деревья, абстрактные типы данных, такие как стеки и очереди.
- Алгоритмы сортировки, предназначенные для упорядочения массивов и файлов, имеют особую важность. С алгоритмами сортировки связаны, в частности, очереди по приоритету, задачи выбора и слияния.
- Алгоритмы поиска, предназначенные для поиска конкретных элементов в больших коллекциях элементов. К ним относятся основные и расширенные методы поиска с использованием деревьев и преобразований цифровых ключей, в том числе деревья цифрового поиска, сбалансированные деревья, хеширование, а также методы, которые подходят для работы с очень крупными файлами.
- Алгоритмы на графах полезны при решении ряда сложных и важных задач. Общая стратегия поиска на графах разрабатывается и применяется к фундаментальным задачам связности, в том числе к задаче отыскания кратчайшего пути, построения минимального остовного дерева, к задаче о потоках в сетях и задаче о паросочетаниях. Унифицированный подход к этим алгоритмам показывает, что в их основе лежит одна и та же функция, и что эта функция базируется на основном абстрактном типе данных очереди по приоритету.
- Алгоритмы обработки строк включают ряд методов обработки последовательностей символов. Поиск в строке приводит к сопоставлению с эталоном, что, в свою очередь, ведет к синтаксическому анализу. К этому же классу задач можно отнести и технологии сжатия файлов.
- Геометрические алгоритмы – это методы решения задач с использованием точек и линий (и других простых геометрических объектов), которые вошли в употребление достаточно недавно. К ним относятся алгоритмы построения выпуклых оболочек, заданных набором точек, определения пересечений геометрических объектов, решения задач отыскания ближайших точек и алгоритма многомерного поиска. Многие из этих методов дополняют простые методы сортировки и поиска.
Ключевые термины
Алгоритм обработки данных – это описание метода решения задачи в компьютерных науках, который в дальнейшем возможно реализовать в выбранной среде программирования.
Анализ алгоритмов – это направление компьютерных наук, занимающееся изучением оценки эффективности алгоритмов.
Трудоемкость алгоритма – это количество элементарных операций, которые учитываются при анализе алгоритма.
Худший случай трудоемкости – это наибольшее количество операций, задаваемых алгоритмом А на всех входах D определенной размерности n.
Лучший случай трудоемкости – это наименьшее количество операций в алгоритме А на всех входах D определенной размерности n.
Средний случай трудоемкости – это среднее количество операций в алгоритме А на всех входах D определенной размерности n.
Функция трудоемкости алгоритма – это зависимость трудоемкости алгоритма А от значения параметров на входе D.
Временная сложность алгоритма – это асимптотическая оценка функции трудоемкости алгоритма для худшего случая.
Объем памяти – это максимальное количество ячеек памяти, задействованных в ходе выполнения алгоритма А для входа D.
Емкостная сложность алгоритма – это асимптотическая оценка функции объема памяти алгоритма для худшего случая.
Ресурсная сложность алгоритма в худшем, среднем и лучшем случаях – это упорядоченная пара классов функций временной и емкостной сложности, заданных асимптотическими обозначениями и соответствующих рассматриваемому случаю.
Алгоритмы работы со структурами данных – это алгоритмы, которые определяют базовые принципы и методологию, используемые для получения представление о методах обработки данных.
Алгоритмы сортировки – это алгоритмы, предназначенные для упорядочения массивов и файлов.
Алгоритмы поиска – это алгоритмы, предназначенные для поиска конкретных элементов в больших коллекциях данных.
Алгоритмы на графах – это алгоритмы, предназначенные для реализации стратегий обходов и поиска на графах.
Алгоритмы обработки строк – это алгоритмы, которые включают ряд методов обработки последовательностей символов.
Геометрические алгоритмы – это алгоритмы решения задач с использованием геометрических объектов.
Краткие итоги
- Определение ресурсной эффективности алгоритмов – необходимая составляющая этапа анализа разработанного программного обеспечения.
- Наиболее значимыми характеристиками ресурсной эффективности алгоритмов являются оценки их временной и емкостной сложности.
- Временная сложность алгоритма определяется асимптотической оценкой функции трудоемкости алгоритма для худшего случая.
- В зависимости от вида функции временной сложности алгоритма выделяют пять основных классов сложности алгоритмов.
- Емкостная сложность алгоритма определяется как асимптотическая оценка функции объема памяти алгоритма для худшего случая.
- Ресурсная сложность алгоритма в худшем, среднем и лучшем случаях определяется как упорядоченная пара классов функций временной и емкостной сложности, заданных асимптотическими обозначениями и соответствующих рассматриваемому случаю.
- Для получения функций трудоемкости для лучшего, среднего и худшего случаев при фиксированной размерности входа необходимо учесть особенности в оценке основных алгоритмических конструкций.
- Особенностью оценки ресурсной эффективности рекурсивных алгоритмов является необходимость учета дополнительных затрат памяти и механизма организации рекурсии.
- В зависимости от структур обработки данных в процедурном программировании выделяются классы базовых алгоритмов.