Эволюционные стратегии
9.4. Генетические операторы ЭС
В ЭС, как и в большинстве методов эволюционных вычислений, могут использоваться три генетических оператора: отбора, кроссинговера и мутации.
9.4.1 Операторы отбора
В ЭС отбор особей используется для: 1) выбора родителей, которые принимают участие в рекомбинации; 2) для формирования популяции следующего поколения. Для отбора  родителей оператора кроссинговера может быть использован любой из методов, рассмотренных в разделе 3.3. Часто родительские особи выбираются случайно.
родителей оператора кроссинговера может быть использован любой из методов, рассмотренных в разделе 3.3. Часто родительские особи выбираются случайно.
В каждом поколении 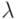 потомков генерируются из
потомков генерируются из  родителей и подвергаются мутации. После кроссинговера и мутации отбираются особи в следующее поколение. При этом применяются две основные стратегии:
родителей и подвергаются мутации. После кроссинговера и мутации отбираются особи в следующее поколение. При этом применяются две основные стратегии:
-
 -ЭС, где из родителей генерируется потомков
-ЭС, где из родителей генерируется потомков  и отбор лучших особей в следующее поколение (обычно с применением элитизма) производится среди объединенного множества ( особей) родителей и потомков;
и отбор лучших особей в следующее поколение (обычно с применением элитизма) производится среди объединенного множества ( особей) родителей и потомков; -
 -ЭС, где -особей родителей порождает -потомков, причем
-ЭС, где -особей родителей порождает -потомков, причем  и процесс выбора лучших производится только на множестве потомков.
и процесс выбора лучших производится только на множестве потомков.
Учитывая приведенные нотации, иногда используется  -ЭС обозначение. В некоторых случаях нотация -ЭС расширяется до
-ЭС обозначение. В некоторых случаях нотация -ЭС расширяется до  , где
, где  обозначает максимальную продолжительность жизни особи. Если число поколений превышает этот предел, то особь не может отбираться в следующее поколение. Заметим, что -ЭС эквивалентна
обозначает максимальную продолжительность жизни особи. Если число поколений превышает этот предел, то особь не может отбираться в следующее поколение. Заметим, что -ЭС эквивалентна  -ЭС. Выбор лучшей стратегии зависит от решаемой задачи.
-ЭС. Выбор лучшей стратегии зависит от решаемой задачи.
9.4.2. Операторы кроссинговера
В классической (1+1)-ЭС используется только оператор мутации. В последующих модификациях, начиная с (+1)-ЭС допускается применение операторов кроссинговера. При этом оператор может применяться как на уровне генотипа (векторов вещественных чисел), так и параметров и реализуется способом, отличным от других парадигм ЭВ. Реализация отличается по возможному числу родителей, участвующих в рекомбинации и по способу комбинации генетического материала и значений параметров. В общем случае нотация  используется для указания того, что родителей используется при реализации оператора кроссинговера. На основе значений этих родительских особей потомки генерируются путем применения:
используется для указания того, что родителей используется при реализации оператора кроссинговера. На основе значений этих родительских особей потомки генерируются путем применения:
- локального кроссинговера
 , где один потомок производится из двух случайно взятых родителей;
, где один потомок производится из двух случайно взятых родителей; - глобального кроссинговера
 , где более чем два родителя используются для генерации потомка. Чем больше значение , тем больше возможное разнообразие у получаемых потомков.
, где более чем два родителя используются для генерации потомка. Чем больше значение , тем больше возможное разнообразие у получаемых потомков.
Поэтому глобальный кроссинговер улучшает эксплутационные свойства ЭС.
В обоих случаях рекомбинация может выполняться следующим образом:
- Дискретная рекомбинация, значения родительских особей используются для получения значений генов потомков, как описано в разделе 3.3. Для каждой компоненты потомка берется компонента одного из родителей (как описано в разделе 3.3). Нотация
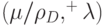 используется для обозначения дискретной рекомбинации.
используется для обозначения дискретной рекомбинации. - Промежуточная рекомбинация, где значение особи-потомка получается путем взвешенной арифметической суммы родительских особей (как описано в разделе 3.3). Нотация
 используется для обозначения промежуточной рекомбинации.
используется для обозначения промежуточной рекомбинации.
На основе приведенных выше типов рекомбинации в ЭС разработаны и применяются следующие основные пять видов рекомбинации:
-
Нет рекомбинации: Если
 - родительская особь, то она переходит в следующее поколение в качестве потомка
- родительская особь, то она переходит в следующее поколение в качестве потомка  .
. -
Локальная дискретная рекомбинация, где
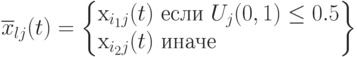 и
и 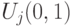 - случайное число в диапазоне (0,1).Здесь потомок
- случайное число в диапазоне (0,1).Здесь потомок  наследует свойства обоих родителей
наследует свойства обоих родителей  и
и 
-
Локальная промежуточная рекомбинация, где
 и
и 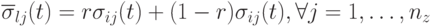 с
с 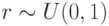 .Если используются углы вращения, то
.Если используются углы вращения, то ![\omega_{lj}=[rx_{i_1k}(t)+(1-r)\sigma_{i_2k}(t)]\mod 2\pi,\forall k=1,\dots,n_x(n_x-1)](/sites/default/files/tex_cache/c1496a3708b873dbb608a40bca0cf0eb.png) .
. -
Глобальная дискретная рекомбинация, где
 с
с  , где
, где  множество индексов родителей, отобранных для выполнения кроссинговера.
множество индексов родителей, отобранных для выполнения кроссинговера. -
Глобальная промежуточная рекомбинация походит на локальную промежуточную рекомбинацию за исключением того, что индекс
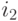 заменяется на . Есть альтернативный вариант этого оператора, когда потомок вычисляется на основе средних значений родителей .
заменяется на . Есть альтернативный вариант этого оператора, когда потомок вычисляется на основе средних значений родителей .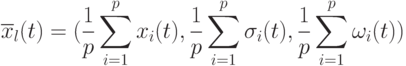
( 9.18)
В [9] предложена арифметическая рекомбинация между лучшей и средней по всем родителям особью:

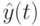 - лучшая особь текущей популяции. Этот подход применим и к построению значений параметров ЭС. Данная стратегия ведет к тому, что потомок располагается в окрестности лучшей особи.
- лучшая особь текущей популяции. Этот подход применим и к построению значений параметров ЭС. Данная стратегия ведет к тому, что потомок располагается в окрестности лучшей особи.9.4.3. Операторы мутации
После выполнения оператора кроссинговера полученные потомки с вероятностью  подвергаются мутации. Оператор мутации выполняется в два шага для каждого потомка следующим образом:
подвергаются мутации. Оператор мутации выполняется в два шага для каждого потомка следующим образом:
- На первом шаге производится самоадаптация параметров одним из методов, изложенных ранее.
- На втором шаге выполняется собственно мутация
 .
.
При этом мутируемых потомков  принимают участие в процессе отбора (наравне со своими родителями) в зависимости от того, какая стратегия - -ЭС или -ЭС используется. В данном разделе рассматривается только мутация значений генотипа, поскольку мутация и самоадаптация параметров изложены ранее.
принимают участие в процессе отбора (наравне со своими родителями) в зависимости от того, какая стратегия - -ЭС или -ЭС используется. В данном разделе рассматривается только мутация значений генотипа, поскольку мутация и самоадаптация параметров изложены ранее.
Если в качестве параметров используются только отклонения, генотип  каждого потомка мутирует в соответствии с правилами:
каждого потомка мутирует в соответствии с правилами:
- Если

- Если

- Если

Если, кроме этого, используются и углы вращения, то в предположении  приращение вычисляется согласно выражению
приращение вычисляется согласно выражению

где  - ортогональная матрица вращения
- ортогональная матрица вращения

которая является произведением  матриц вращения. Каждая матрица вращения
матриц вращения. Каждая матрица вращения  - единичная матрица, где элементы определяются следующим образом:
- единичная матрица, где элементы определяются следующим образом:  для
для  и
и  - диагональная матрица, представляющая отклонения.
- диагональная матрица, представляющая отклонения.
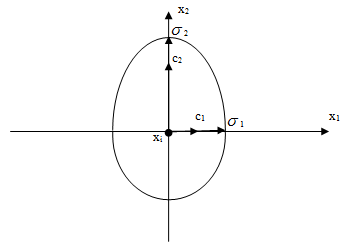
В работе [10] предложена направленная мутация, где предпочтение отдается некоторому направлению в пространстве поиска. Как показано нарис.9.2, она основана на асимметричном вероятностном распределении мутации. Здесь размер шага по оси  больше, чем по оси
больше, чем по оси  и отдается предпочтение положительным направлениям.
и отдается предпочтение положительным направлениям.
При этом каждый компонент генотипа мутирует независимо и поэтому достаточно определить одномерную асимметричную функцию плотности вероятностей, например в виде
 |
( 9.20) |
где  положительно определенная величина.
положительно определенная величина.
Метод направленной мутации использует только параметры отклонений, но ассоциирует с каждым отклонением  значение
значение 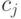 , определяющее направление. Для обеих величин
, определяющее направление. Для обеих величин 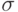 и
и  возможна само-адаптация, что дает
возможна само-адаптация, что дает  параметров. С вычислительной точки зрения это более эффективно, чем использование вектора вращения размерности и дает больше информации о предпочтительном направлении и размере шага.
параметров. С вычислительной точки зрения это более эффективно, чем использование вектора вращения размерности и дает больше информации о предпочтительном направлении и размере шага.
Если 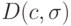 означает асимметричное распределение, то
означает асимметричное распределение, то 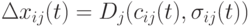
В работе [7] предложен инвариантный в системе координат оператор мутации с самоадаптацией, где генотип мутирует, используя значения отклонений и корреляций следующим образом:
 |
( 9.21) |