Московский государственный технический университет им. Н.Э. Баумана
Опубликован: 08.08.2011 | Доступ: свободный | Студентов: 2380 / 668 | Оценка: 4.53 / 4.24 | Длительность: 18:21:00
Специальности: Менеджер
Лекция 7:
Использование функций
Статистические вычисления
О статистических функциях
Статистические функции используют при анализе данных. Использование большинства функций этой категории требует знания математической статистики и теории вероятностей.
Расчет средних значений
В самом простом случае для расчета среднего арифметического значения используют функцию AVERAGE. Синтаксис функции:
AVERAGE(Число1; Число2; ...; Число30),
где: Число1...30 – список от 1 до 30 аргументов, среднее значение которых требуется найти. Аргумент может быть ячейкой, диапазоном ячеек, числом или формулой. Ссылки на пустые ячейки, текстовые или логические значения игнорируются.
Если в диапазон, для которого рассчитывают среднее значение, попадают данные, существенно отличающиеся от остальных, расчет простого среднего арифметического может привести к неправильным выводам. В этом случае следует использовать функцию TRIMMEAN. Эта функция вычисляет среднее, отбрасывая заданный процент данных с экстремальными значениями. Синтаксис функции:
TRIMMEAN(Данные; Альфа),
где: Данные – массив или диапазон данных в выборке. Альфа – доля данных с не учитываемыми экстремальными значениями.
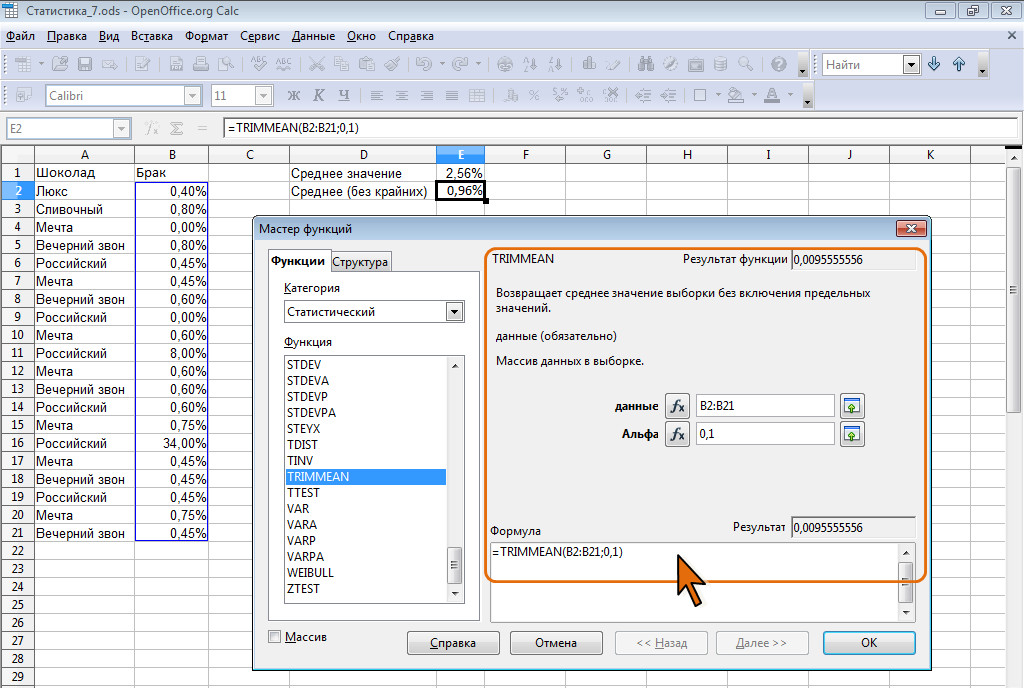
Доля данных, исключаемых из вычислений, указывается в процентах от общего числа данных. Например, доля 10 % означает, что из данных, содержащих 20 значений, отбрасываются 2 значения: одно наибольшее, другое – наименьшее. В таблице на рис. 7.6 величина брака по одному из товаров существенно отличается от остальных значений (8% и 34 %). Среднее арифметическое значение данных составляет 2,56 % (ячейка Е1 ), что дает несколько искаженную картину реальных значений. Расчет среднего значения с использованием функции TRIMMEAN (ячейка Е2 ) дает более правильное представление о средних величинах брака в партиях товаров (0,96 %).
увеличить изображение
Рис. 7.6. Расчет среднего значения с отбрасыванием заданного процента данных с экстремальными значениями
Нахождение крайних значений
Для нахождения крайних (наибольшего или наименьшего) значений в диапазоне данных используют функции MAX и MIN. Синтаксис функции MAX:
MAX(Число1; Число2; ...; Число30),
где: Число1…30 – список от 1 до 30 аргументов, среди которых требуется найти наибольшее значение. Аргумент может быть ячейкой, диапазоном ячеек, числом или формулой. Ссылки на пустые ячейки, текстовые или логические значения игнорируются. Если в диапазоне (диапазонах) ячеек не обнаружены числовые значения, и отсутствуют ошибки, результатом будет 0.
Функция MIN имеет такой же синтаксис, что и функция MAX.
Функции MAX и MIN только определяют крайние значения, но не показывают, в какой ячейке эти значения находятся.
В тех случаях, когда требуется найти не самое большое (самое маленькое) значение, а значение, занимающее определенное положение в диапазоне данных (например, второе или третье по величине), следует использовать функции LARGE или SMALL. Синтаксис функции LARGE:
LARGE(данные; К)
где: данные – список от 1 до 30 аргументов, среди которых требуется найти значение. Аргумент может быть ячейкой, диапазоном ячеек, числом или формулой. Ссылки на пустые ячейки, текстовые или логические значения игнорируются. К – позиция (начиная с наибольшей) в множестве данных. Если требуется найти второе значение по величине, то указывается позиция 2, если третье, то позиция 3 и т. д.
Функция SMALL имеет такой же синтаксис, что и функция LARGE.
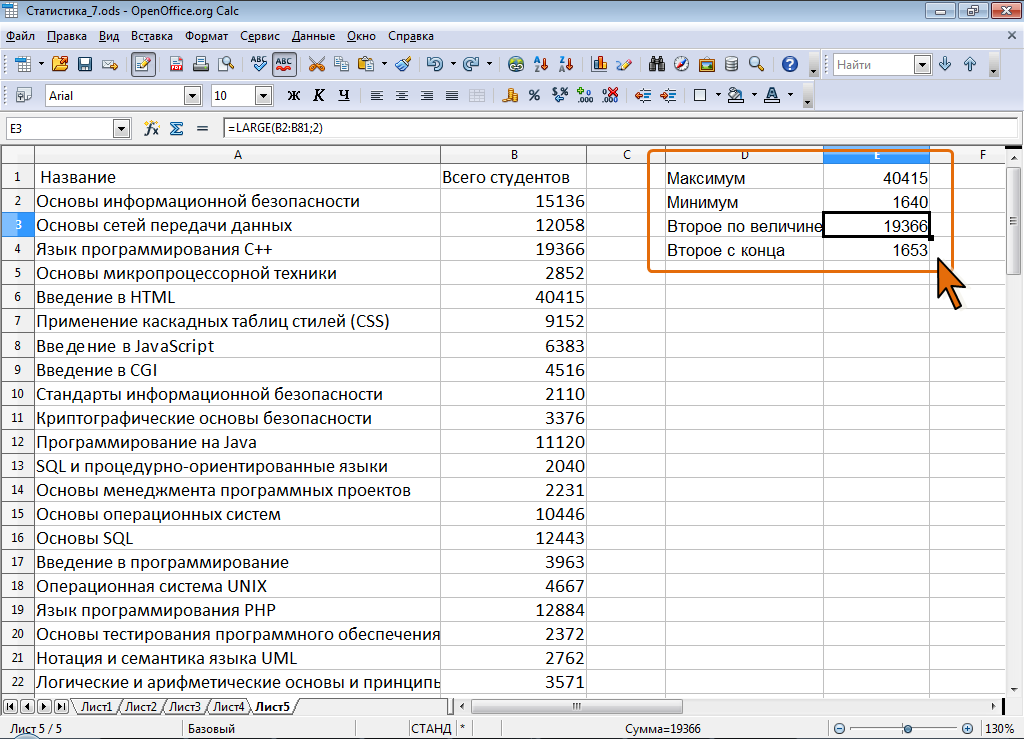
Например, для данных таблицы на рис. 7.7 максимальное значение составит 40415, а второе по величине значение составит 16501; минимальное – 1640, а второе из наименьших – 1653.
Расчет количества ячеек
Для определения количества ячеек, содержащих числовые значения, можно использовать функцию COUNT. Синтаксис функции:
COUNT(Значение1; Значение2; ...Значение30),
где: Значение1…30 – список от 1 до 30 аргументов, среди которых требуется определить количество ячеек, содержащих числовые значения. Аргумент может быть ячейкой, диапазоном ячеек, числом или формулой. Ссылки на пустые ячейки, текстовые или логические значения игнорируются.
Если требуется определить количество ячеек, содержащих любые значения (числовые, текстовые, логические), то следует использовать функцию COUNTA. Синтаксис функции:
COUNTA(Значение1; Значение2; ...Значение30),
где: Значение1…30 – список от 1 до 30 аргументов, среди которых требуется определить количество ячеек, содержащих любые значения. Аргумент может быть ячейкой, диапазоном ячеек, числом или формулой. Ссылки на пустые ячейки игнорируются.
Наоборот, если требуется определить количество пустых ячеек, следует использовать функцию COUNTBLANK. Синтаксис функции:
COUNTBLANK(Диапазон),
где: Диапазон – диапазон ячеек, среди которых требуется определить количество пустых ячеек. Элемент может быть ячейкой, диапазоном ячеек, числом или формулой. Ссылки на ячейки с нулевыми значениями игнорируются.
Можно также определять количество ячеек, отвечающих заданным условиям. Для этого используют функцию COUNTIF. Синтаксис функции:
COUNTIF (Диапазон; Критерий),
где: Диапазон – диапазон проверяемых ячеек. Критерий – условие в виде числа, выражения или символьной строки. Эти условия определяют ячейки, которые должны учитываться. Можно также ввести текст для поиска в виде регулярного выражения, например " И.* " для всех слов, начинающихся с буквы " И ". Кроме того, можно указать диапазон, содержащий условие поиска. Буквенные символы следует заключать в двойные кавычки.
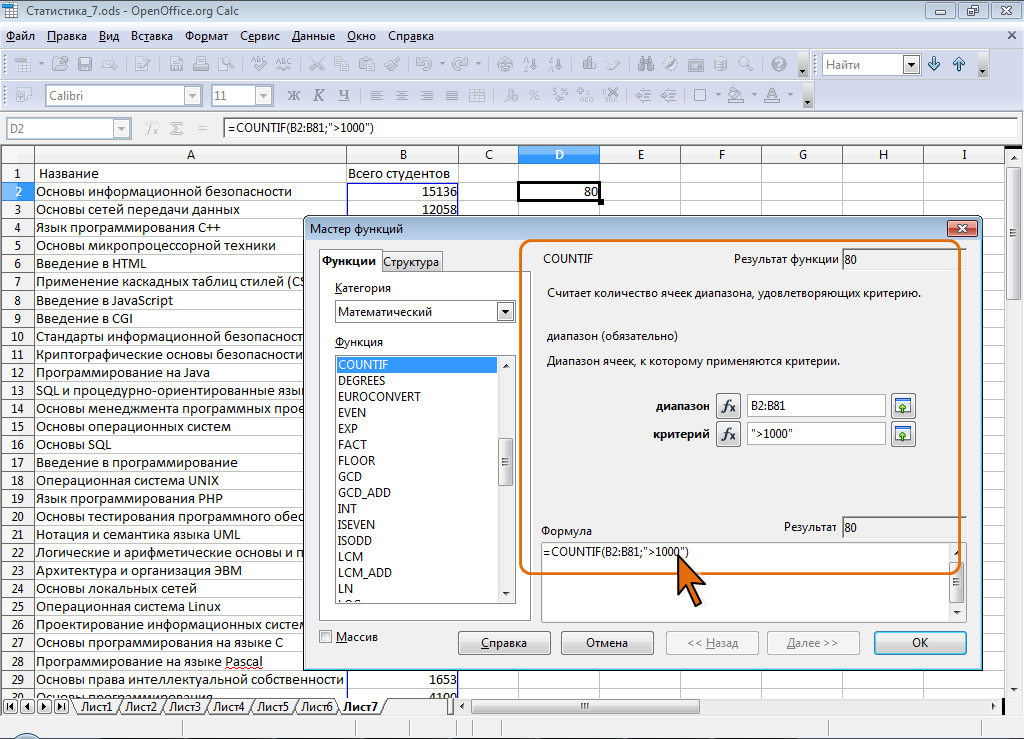
Например, в таблице на рис. 7.8 подсчитано количество курсов, которые изучают более 1000 студентов.