Использование алгоритма MicrosoftTimeSeries для прогнозирования значений временных рядов
На практике мы часто сталкиваемся с временными рядами: биржевые котировки ценных бумаг, объемы выпуска товаров по месяцам, среднесуточные значения температуры воздуха - все это примеры подобных последовательностей. В общем случае, временной ряд - это набор числовых значений, собранных в последовательные моменты времени (в большинстве случаев - через равные промежутки времени). При работе с временными рядами часто возникает желание выявить зависимости между текущим значением и предшествующими ему, и использовать их для прогнозирования будущих значений. Подобную задачу можно решить с использованием алгоритма MicrosoftTimeSeries, входящего в набор стандартных алгоритмов аналитических служб SQLServer 2008.
Для анализа будем использовать данные из учебной базы AdventureWorksDW. Представление (view) dbo.vTimeSeries формирует временной ряд, содержащий результаты продаж различных моделей велосипедов по месяцам ( рис. 32.1).

Рассматриваемый набор данных представляет собой пример чередующегося ряда: в нем есть несколько записей соответствующих одной дате, содержащих данные для разных моделей велосипеда. Другой вариант представления - столбчатый формат - иллюстрируется таблицей 32.1.
| Дата | M200 | R200 | … |
|---|---|---|---|
| 200101 | 100 | 50 | |
| 200102 | 120 | 20 | |
| … | …. | …. |
Но вернемся к нашей задаче. Источник данных, указывающий на базу AdventureWorks DW, у нас уже создан. Следующий шаг - создать в среде BIDevStudio представление источника данных, включающее vTimeSeries. Процесс создания подробно разбирался в "DMX. Параметры алгоритмов интеллектуального анализа данных. Алгоритмы нейронных сетей и логистической регрессии" .Назовем созданное представление источника данных TimeSeries_dsv.
Далее потребуется создатьв среде BIDevStudio модель для прогнозирования рядов. Начало создания модели: использовать будем данные из реляционной БД, алгоритм - MicrosoftTimeSeries(Алгоритм временных рядов Microsoft), представление источника данных - TimeSeries_dsv, таблица с данными - vTimeSeries. Теперь определимся, какие атрибуты потребуются для прогноза. Мы имеем дело с чередующимся временным рядом, и чтобы идентифицировать один его элемент, надо указать отметку времени и название модели. Значит и ключевых атрибутов будет два - DateSeries(отметка времени) и ModelRegion. Прогнозировать будем значения объема продаж в денежном эквиваленте (Amount>) и количество проданных велосипедов (Quantity). Эти атрибуты также будут рассматриваться и в качестве входных( рис. 32.2).
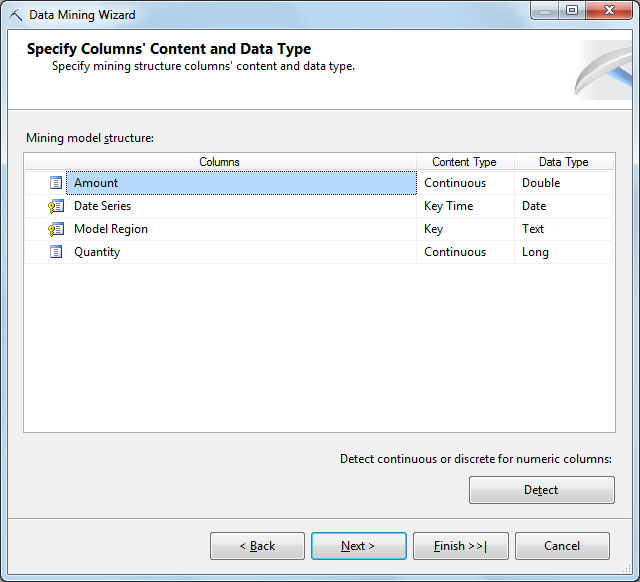
Следующий шаг - определение типов данных и содержимого для выбранных атрибутов. Здесь можно согласиться с автоматически подобранными значениями ( рис. 32.3).Стоит обратить внимание на тип содержимого KeyTime выбранный для столбца [DateSeries]. Столбец с таким типом обязательно должен присутствовать, если будет использоваться алгоритм интеллектуального анализа MicrosoftTimeSeries.
Назовем создаваемую структуру vTimeSeries_TS_Structure, а модель - vTimeSeries_TS ( рис. 32.4).


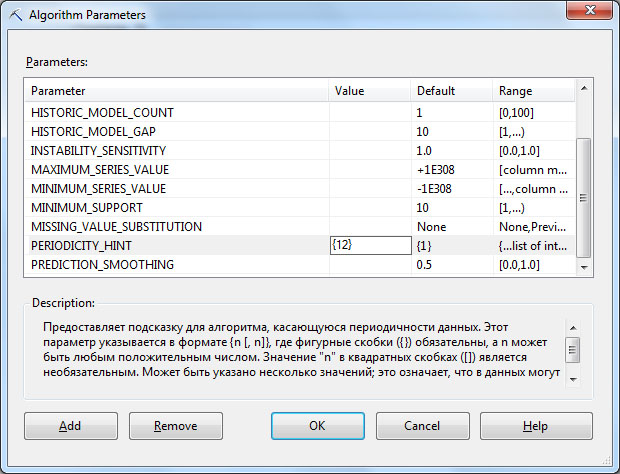
После создания структуры и модели интеллектуального анализа можно более точно настроить параметры. В частности, в свойствах модели можно явно указать, что во временном ряде ожидается периодичность 12 (число месяцев в году, т.к. у нас данные с продажами по месяцам). Подобное изменение настроек показано на рис. 32.5. После этого надо провести полную обработку модели, и на вкладке MiningModelViewer появится возможность просмотреть результаты ( рис. 32.6). Непрерывной линией изображены фактические данные, пунктиром - прогнозируемые результаты.Поле Predictionsteps позволяет указать, на сколько шагов вперед предсказывается значение ряда, а выпадающий список под ним - выбрать значения, для которых строятся графики.
