DMX. Параметры алгоритмов интеллектуального анализа данных. Алгоритмы нейронных сетей и логистической регрессии
Как было разобрано в "Использование инструментов "HighlightExceptions" и "ScenarioAnalysis"" алгоритм MicrosoftLogisticRegression представляет собой вариант алгоритма MicrosoftNeuralNetwork, в котором не используется скрытый слой нейронной сети. Иначе говоря, параметр HIDDEN_NODE_RATIO установлен равным 0 (подробнее о параметре - см. ниже).
Поэтому параметры алгоритмов и особенности их использования во многом схожи. Модель, основанная на нейронной сети, должна содержать по крайней мере один входной и один выходной (прогнозируемый) столбец. Вложенная таблица в качестве прогнозируемого столбца использоваться не может, но допустимо использовать вложенную таблицу в как входной атрибут.
Пример кода DMX, создающего в существующей структуре vTargetMail_structure2 модель на основе нейронных сетей, приведен ниже (подробнее процесс рассматривается в "Задача классификации. Создание структуры и моделей интеллектуального анализа. Сравнение точности моделей" ).
ALTERMININGSTRUCTURE [vTargetMail_structure2]
ADDMININGMODEL [vTargetMail2_NN]
(
[Customer Key],
[Commute Distance],
[Age],
[Number Cars Owned],
[Yearly Income],
[Bike Buyer] PREDICT
)
USINGMicrosoft_Neural_Network
Если создается модель на основе алгоритма логистической регрессии, это указывается ключевыми словами USING Microsoft_Logistic_Regression.
Ниже перечислены параметры алгоритмов.
| HIDDEN_NODE_RATIO | указывает соотношение числа скрытых, входных и выходных нейронов. Следующая формула определяет начальное количество нейронов в скрытом слое:
 |
| HOLDOUT_PERCENTAGE | процент вариантов в составе обучающих данных, используемых для вычисления ошибки контрольных данных.Значение по умолчанию - 30. |
| HOLDOUT_SEED | значение, используемое генератором псевдослучайных чисел в качестве начального, когда алгоритм случайным образом задает контрольные данные. При установке данного параметра равным 0 (значение по умолчанию), алгоритм формирует начальное значение на основе имени модели интеллектуального анализа данных, что гарантирует неизменность содержимого модели при повторной обработке. |
| MAXIMUM_INPUT_ATTRIBUTES | максимальное количество входных атрибутов, которое может быть задано для алгоритма до использования процедуры выбора характеристик (для исключения наименее значимых атрибутов). Установка этого значения равным 0 отключает выбор характеристик для входных атрибутов.Значение по умолчанию - 255. |
| MAXIMUM_OUTPUT_ATTRIBUTES | максимальное количество выходных атрибутов, которое может быть задано для алгоритма до использования выбора характеристик. Установка этого значения равным 0 отключает выбор характеристик для выходных атрибутов.Значение по умолчанию - 255. |
| MAXIMUM_STATES | максимальное число дискретных состояний на один атрибут, поддерживаемое алгоритмом. Если число состояний конкретного атрибута превышает число, указанное для данного параметра, то алгоритм использует наиболее популярные состояния такого атрибута и считает остальные состояния пропущенными.Значение по умолчанию - 100. |
| SAMPLE_SIZE | верхний предел числа вариантов, которые будут использоваться для обучения модели. Алгоритм использует меньшее из двух значений - либо это число, либо заданный параметром HOLDOUT_PERCENTAGE процент от общего количества вариантов, не включенных в состав контрольных данных.Значение по умолчанию - 10000. |
Содержимое модели
Содержимое модели, основанной на алгоритме нейронных сетей, нельзя назвать "интуитивно понятным", поэтому остановимся на его рассмотрении чуть более подробно [19 ].
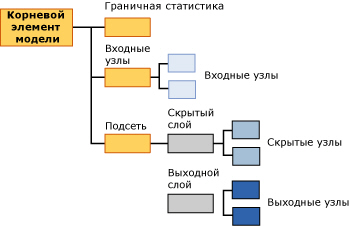
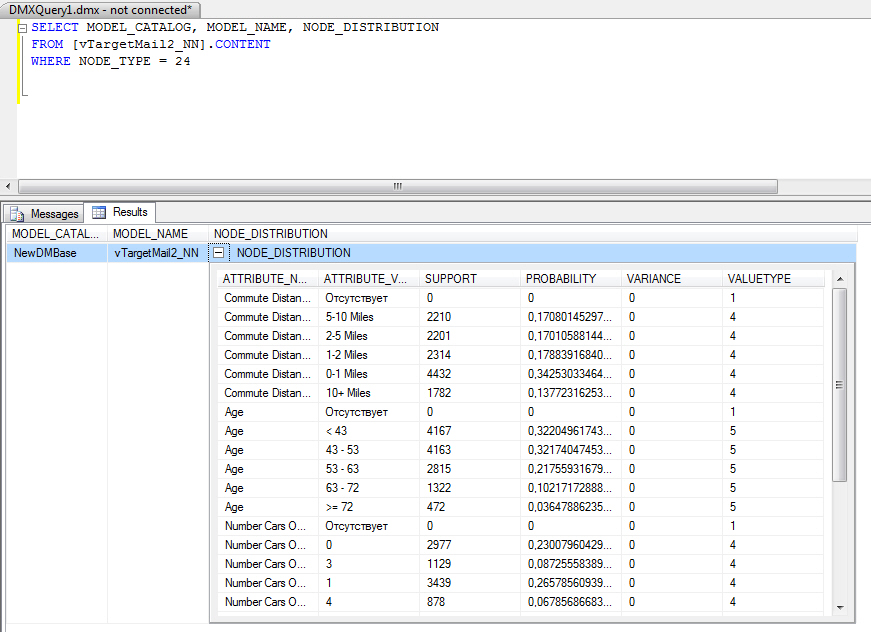
Каждая нейронная сеть имеет один родительский узел, представляющий модель и ее метаданные, а также узел граничной статистики (NODE_TYPE = 24), который содержит описательную статистику о входных атрибутах. Подробнее о доступе к ней см. ниже
Под этими двумя узлами расположено не менее двух других узлов.
Первый узел (NODE_TYPE = 18) всегда представляет верхний узел входного слоя. Под этим верхним узлом находятся входные узлы (NODE_TYPE = 21), которые содержат фактические входные атрибуты и их значения. Пример содержимого узла данного типа представлен на рис. 16.2.
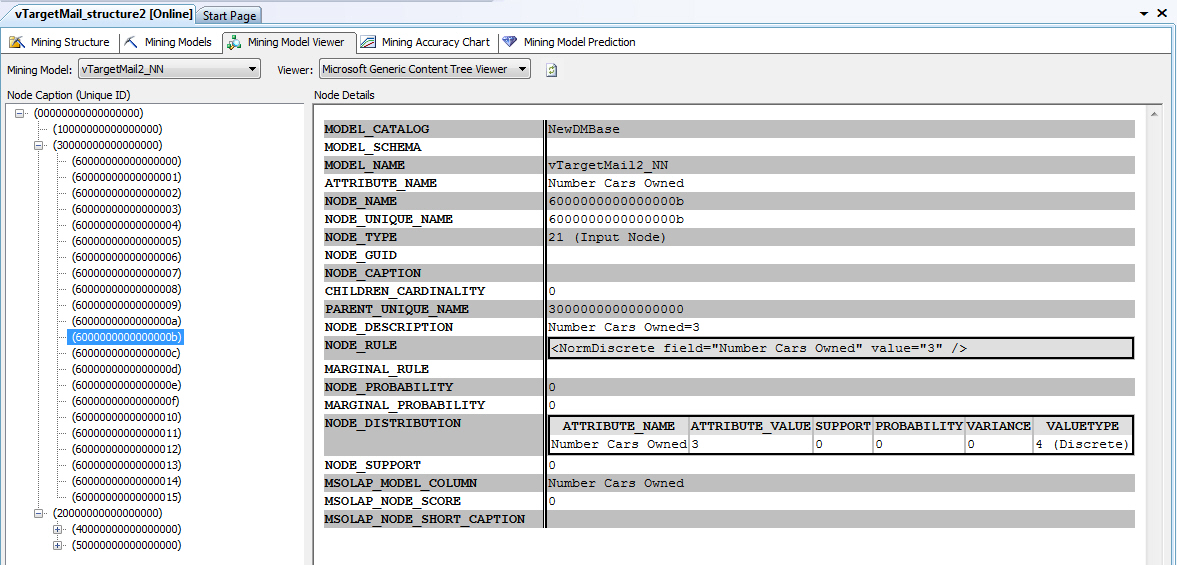
В каждом из последующих узлов содержится отдельная подсеть (NODE_TYPE = 17). Каждая подсеть всегда содержит собственный скрытый слой (NODE_TYPE = 19) и выходной слой (NODE_TYPE = 20).
Каждая подсеть (NODE_TYPE = 17) представляет анализ влияния входного слоя на отдельный прогнозируемый атрибут. Если существует несколько прогнозируемых выходов, будет создано несколько подсетей. Скрытый слой для каждой подсети содержит несколько скрытых узлов (NODE_TYPE = 22), в которых содержатся данные о весовых коэффициентах для каждого перехода, завершающегося в данном скрытом узле.
Выходной слой (NODE_TYPE = 20) содержит выходные узлы (NODE_TYPE = 23), в каждом из которых находятся уникальные значения прогнозируемого атрибута. Если прогнозируемый атрибут имеет непрерывный числовой тип данных, то для него будет только один выходной узел.
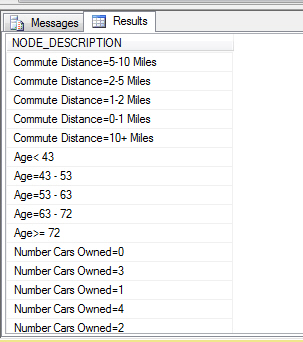
Описание узлов можно просмотреть с помощью запроса к модели следующего вида (приведен пример для входных узлов, тип 21, результат выполнения представлен на рис. 16.3):
SELECT NODE_DESCRIPTION
FROM [vTargetMail2_NN].CONTENT
WHERE NODE_TYPE = 21
Следующий запрос к узлу граничной статистики (тип 24) позволяет узнать статистику по входным атрибутам ( рис. 16.4).