Задача классификации. Создание структуры и моделей интеллектуального анализа. Сравнение точности моделей
Пусть, используя имеющиеся данные компании AdventureWorks, необходимо определить, купит ли новый клиент велосипед или нет. Это пример задачи классификации,которую можно решить с помощью разных алгоритмов: упрощенного алгоритма Байеса, нейронных сетей, деревьев решений. Рассмотрим, как для одной структуры можно создать несколько моделей и оценить качество формируемого ими прогноза.
По аналогии с заданиями предыдущей лабораторной создадим структуру интеллектуального анализа и модель, использующую упрощенного алгоритма Байеса. Назовем структуру - vTargetMail_structure2, модель на основе алгоритма NaiveBayes (упрощенный алгоритм Байеса) - vTargetMail_NB. Данные будем брать, как и раньше, из представления vTargetMail, используя созданные в предыдущих лабораторных источник данных (DataSource) и представление источника данных (DataSourceView).
При определении структуры и модели в перечне столбцов отметим ключевой атрибут - CustomerKey и предсказываемое (Predictable) значение - BikeBuyer (1 - признак того, что клиент купил велосипед; 0 - не купил). Чтобы определить, какие атрибуты оказывают на него влияние, воспользуемся кнопкой Suggest и отметим предлагаемые столбцы, в наибольшей степени влияющие на целевой. Наши знания о предметной области подсказывают, что адрес и имя стоит исключить, а включив в cписок EnglishEducation, можно исключить FrenchEducationиSpanishEducation, т.к. это то же самое, только на другом языке. Таким образом, в качестве входных (Input) атрибутов будем использовать:
- Age (возрастклиента);
- NumberCarsOwned (числомашинвсобственности);
- TotalChildren (общее число детей);
- EnglishEducation (образование);
- CommuteDistance (расстояниедоработыилидругих "регулярных" поездок);
- NumberChildrenAtHome (числодетейдома, т.е. требующихприсмотра);
- YearlyIncome (годовой доход);
- Region (регион проживания).

На рис. 29.2 представлены типы данных, автоматически установленные для столбцов. Обратите внимание, что для некоторых столбцов установлен тип содержимого Discretized. Связано это с тем, что выбранный для модели упрощенный алгоритм Байеса не работает с числовыми атрибутами с типом содержимого Continuous и для этих столбцов будет проведена дискретизация (разбиение на интервалы) значений. Такой тип содержимого корректен в случае атрибутов Age и YearlyIncome. Но, NumberCarsOwned, NumberChildrenAtHome, TotalChildren надо сменить тип на Discrete - мы знаем, что множество возможных значений этих атрибутов невелико.
Для целей тестирования в соответствии с установкой по умолчанию резервируем 30% записей.
Таким образом, мы создали структуру интеллектуального анализа данных. Если открыть структуру в редакторе и перейти на вкладку MiningModels можно удостовериться, что создана и модель ( рис. 29.3). Обратите внимание, что атрибут BikeBuyer отмечен как предсказываемый (PredictOnly). Раскрывающийся список напротив названия столбца позволяет сменить данную настройку. Если какой-то атрибут надо исключить из рассмотрения при обучении модели, смените значения Input на Ignore (игнорировать).

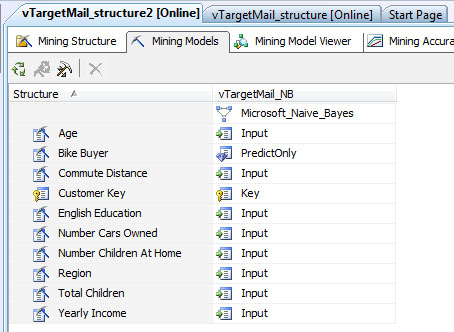
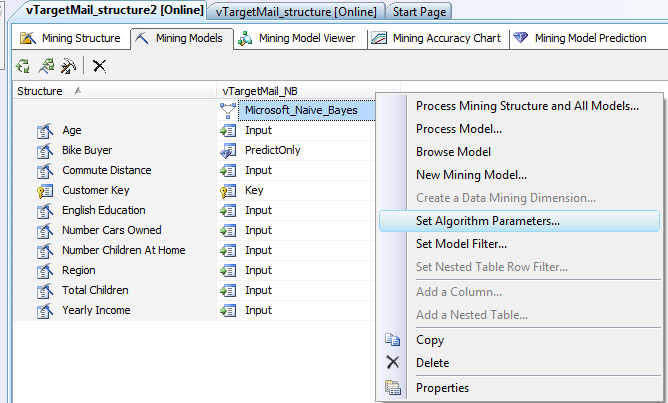
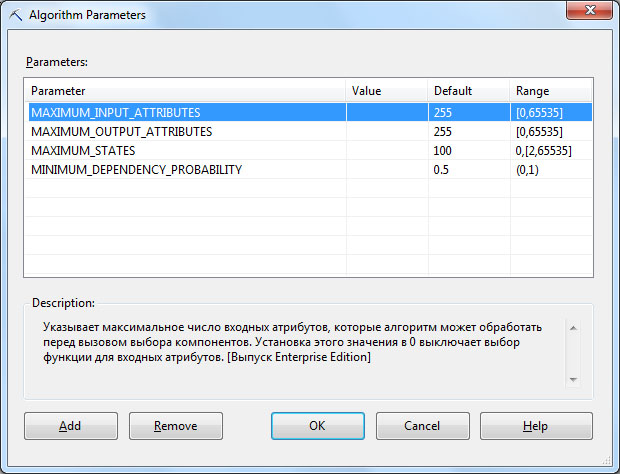
Воспользовавшись контекстным меню ( рис. 29.4) можно получить доступ к параметрам используемого моделью алгоритма ( рис. 29.5). Также можно настроить фильтр (пункт SetModelFilter…), тогда для анализа будут использоваться только варианты, соответствующие условиям фильтрации. Например, это позволяет исключить из рассмотрения клиентов из какого-то региона, который, как мы считаем, существенно отличается от остальных.
увеличить изображение
Рис. 29.4. Контекстное меню позволяет просмотреть и изменить параметры алгоритма
Воспользовавшись пунктом NewMiningModel… контекстного меню ( рис. 29.4) можно создавать аналогичные по набору атрибутов модели, основанные на других алгоритмах интеллектуального анализа.

После того, как структура и модели созданы и обработаны, хотелось бы выяснить, какая из трех моделей дает более точный прогноз. Для этого можно использовать диаграммы точности (MiningAccuracyChart) и зарезервированное в ходе создания структуры множество вариантов для тестирования (эти данные не использовались при обучении модели).
Перейдем на вкладку Mining Accuracy Chart ( рис. 29.7). Там можно отметить, для каких моделей будут строиться диаграммы, и какие данные будут использоваться в процессе тестирования. Можно использовать набор данных, зарезервированный в модели или в структуре, а также внешний набор данных. Первые два варианта будут отличаться, если при создании модели задавался фильтр вариантов. Проверочный набор в модели будет включать только варианты, соответствующие фильтру, а проверочный набор в структуре фильтр не учитывает. В нашем случае фильтрация не использовалась, так что эти варианты равнозначны.
Кроме того, для дискретного целевого атрибута можно выбрать предсказываемое значение (PredictValue, рис. 29.7). В рассматриваемом примере нам более интересна 1, т.е. клиент, который сделает покупку.

Выбираем тестовый набор для структуры, PredictValue = 1, и переходим на вкладку LiftChart. Стандартная диаграмма точности, называемая диаграммой роста (LiftChart) будет выглядеть, как представлено на рис. 29.8. Зеленая линия изображает идеальную модель, синяя - случайный выбор. У нас в тестовом наборе примерно 50% вариантов имеют значение BikeBuyer равное 1. И можно представить, что каждая модель согласно своему прогнозу формирует упорядоченный по степени близости к искомому значению список вариантов. Так вот, у идеальной модели искомые варианты будут в первых 50% позиций списка. У случайной модели - в первой половине списка будет только 50% клиентов, сделавших покупку. Чем ближе результат к идеальной модели, тем точнее прогноз. В нашем примере наилучший результат дает модель, использующая алгоритм деревьев принятия решений (DecisionTrees).


Если не указывать целевое значение(т.е. на рис. 29.7 не ставить PredictValue = 1), то диаграмма точности будет выглядеть, как представлено на рис. 29.9. На ней тоже видно, что модель vTargetMail_DT дает более точный прогноз.
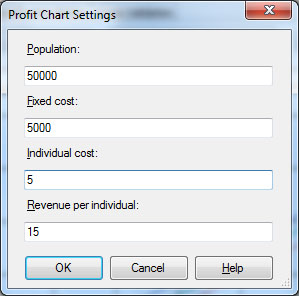
Чтобы получить стоимостную оценку качества модели, можно использовать диаграмму роста прибыли (на рис. 29.8 - ProfitChart). BIDevStudio запросит данные об общем числе вариантов - Population (например, это число клиентов, которым собираемся провести рассылку), ограничении на суммарную стоимость - FixedCost (например бюджет рекламной рассылки), затратах на единицу - IndividualCost (например стоимость отправки одного письма с рекламным предложением), выручке от одного покупателя - RevenueperIndividual ( рис. 29.10).
Полученная диаграмма позволяет понять какое число предложений надо разослать для получения максимально прибыли. Будем считать, что на основе прогнозов каждой модели сформирован список клиентов, упорядоченный по убыванию прогнозируемой вероятности покупки клиентом велосипеда. На рис. 29.11, максимум прибыли будет достигнут, когда при использовании модели vTargetMail_DT, предложения будут отправлены примерно 64% клиентов, начиная с верхней части списка.