Краткий обзор алгоритмов интеллектуального анализа данных. Алгоритмы нейронных сетей и логистической регрессии
Некоторые задачи интеллектуального анализа данных, в частности, задача классификации, могут решаться с помощью различных алгоритмов. В случае наличия в данных сложных зависимостей между атрибутами, "быстрые" алгоритмы интеллектуального анализа, такие как упрощённый алгоритм Байеса, могут давать недостаточно точный результат. Улучшить ситуацию может применение нейросетевых алгоритмов.
Нейронные сети - это класс моделей, построенных по аналогии с работой человеческого мозга. Существуют различные типы сетей, в частности, в SQLServer алгоритм нейронной сети использует сеть в виде многослойного перцептрона, в состав которой может входить до трех слоев нейронов, или перцептронов. Такими слоями являются входной слой, необязательный скрытый слой и выходной слой ( рис. 12.1).

Рис. 12.1. Пример схемы нейронной сети: входной слой - зеленые узлы, скрытый слой - голубые, выходной - желтый
Каждый нейрон получает одно или несколько входных значений (входов)и создает выходное значение (один или несколько одинаковых выходов). Каждый выход является простой нелинейной функцией суммы входов, полученных нейроном. Входы передаются в прямом направлении от узлов во входном слое к узлам в скрытом слое, а оттуда передаются на выходной слой. Нейроны в составе слоя не соединены друг с другом. Скрытый слой может отсутствовать (в частности, это используется алгоритмом логистической регрессии).
Имеющий более двух состояний дискретный входной атрибут модели интеллектуального анализа приводит к созданию одного входного нейрона для каждого состояния и одного входного нейрона для отсутствующего состояния (если обучающие данные содержат какие-либо значения NULL). Непрерывный входной атрибут "создает" два входных нейрона: один нейрон для отсутствующего состояния и один нейрон для значения самого непрерывного атрибута. Входные нейроны обеспечивают входы для одного или нескольких скрытых нейронов.
Выходные нейроны представляют значения прогнозируемых атрибутов для модели интеллектуального анализа данных. Дискретный прогнозируемый атрибут, имеющий более двух состояний, "создает" один выходной нейрон для каждого состояния и один выходной нейрон для отсутствующего или существующего состояния. Непрерывные прогнозируемые столбцы "создают" два выходных нейрона: один нейрон для отсутствующего или существующего состояния и один нейрон для значения самого непрерывного столбца.
Нейрон получает входы от других нейронов или из других данных, в зависимости от того, в каком слое сети он находится. Входной нейрон получает входы от исходных данных. Скрытые нейроны и выходные нейроны получают входы из выхода других нейронов нейронной сети. Входы устанавливают связи между нейронами, и эти связи являются путем, по которому производится анализ для конкретного набора вариантов.
Каждому входу присвоено значение, именуемое весом, которое описывает релевантность или важность конкретного входа для скрытого или выходного нейрона. Чем больше вес, присвоенный входу, тем более релевантным или важным является значение этого входа. Значения веса могут быть отрицательными; это означает, что вход может подавлять, а не активировать конкретный нейрон. Чтобы выделить важность входа для конкретного нейрона, значение входа умножается на вес. В случае отрицательных весов умножение значения на вес служит для уменьшения важности входа. Схематично это представлено на
рис.
12.2, где 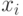 - вход,
- вход, 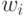 - соответствующий ему вес.Каждому нейрону сопоставлена простая нелинейная функция, называемая функцией активации, которая описывает релевантность или важность определенного нейрона для этого слоя нейронной сети.
В качестве функции активации в алгоритме MicrosoftNeuralNetwork скрытые нейроны используют функцию гиперболического тангенса (tanh), а выходные нейроны - сигмоидальную (логистическую) функцию. Обе функции являются нелинейнымии непрерывными, позволяющими нейронной сети моделировать нелинейные связи между входными и выходными нейронами.
- соответствующий ему вес.Каждому нейрону сопоставлена простая нелинейная функция, называемая функцией активации, которая описывает релевантность или важность определенного нейрона для этого слоя нейронной сети.
В качестве функции активации в алгоритме MicrosoftNeuralNetwork скрытые нейроны используют функцию гиперболического тангенса (tanh), а выходные нейроны - сигмоидальную (логистическую) функцию. Обе функции являются нелинейнымии непрерывными, позволяющими нейронной сети моделировать нелинейные связи между входными и выходными нейронами.

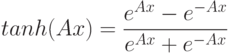

Обучение модели интеллектуального анализа данных производится по следующей схеме. Алгоритм сначала оценивает обучающие данные и резервирует определенный процент из них для использования при определении точности сети.
Затем алгоритм определяет количество и сложность сетей, включаемых в модель интеллектуального анализа данных. Определяется число нейронов в каждом слое. Процесс обучения строится по следующей схеме [1]:
- На начальной стадии случайным образом присваиваются значения всем весам всех входов в сети. Значения обычно берутся из интервала (-1,1).
- Для каждого обучающего варианта вычисляются выходы.
- Вычисляются ошибки выходов. В качестве функции ошибки может использоваться квадрат остатка (квадрат разности между спрогнозированым и фактическим значением).
- Шаги 2,3 повторяются для всех вариантов, используемых в качестве образцов. После этого веса в сети обновляются таким образом, чтобы минимизировать ошибки.
В процессе обучения может выполняться несколько итераций. После прекращения роста точности модели обучение завершается.
Теперь перейдем к алгоритму логистической регрессии.
Логистическая регрессия является известным статистическим методом для определения влияния нескольких факторов на логическую пару результатов. Например, задача может быть следующей. Предположим, что прогнозируемый столбец содержит только два состояния, и необходимо провести регрессионный анализ, сопоставляя входные столбцы с вероятностью того, что прогнозируемый столбец будет содержать конкретное состояние[18]. Результаты, полученные методами линейной и логистической регрессии представлены на рис. 12.3a и 12.3b соответственно. Линейная регрессия не ограничивает значения функции диапазоном от 0 до 1, несмотря на то, что они должны являться минимальным и максимальным значениями этого столбца. Кривая, формируемая алгоритмом логистической регрессии, в этом случае более точно описывает исследуемую характеристику.

В реализации Майкрософт, для моделирования связей между входными и выходными атрибутами применяется видоизмененная нейронная сеть, в которой отсутствует скрытый слой. Измеряется вклад каждого входного атрибута, и в законченной модели различные входы снабжаются весовыми коэффициентами. Название "логистическая регрессия" отражает тот факт, что кривая данных сжимается путем применения логистического преобразования, чтобы снизить эффект экстремальных значений.