Лекция 5:
Синтаксический анализ
LL(k)-грамматики
Определение. КС-грамматика  называется LL(k)-грамматикой для некоторого
фиксированного k, если из
называется LL(k)-грамматикой для некоторого
фиксированного k, если из
(1) 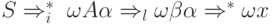
(2)  для которых
для которых
и
FIRSTk(x) = FIRSTk(y), вытекает, что  .
.
Говоря менее формально, G будет LL(k)- грамматикой,
если для данной цепочки  и первых k
символов (если они есть), выводящихся из
и первых k
символов (если они есть), выводящихся из 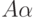 , существует
не более одного правила, которое можно применить к A,
чтобы получить вывод какой-нибудь терминальной цепочки,
, существует
не более одного правила, которое можно применить к A,
чтобы получить вывод какой-нибудь терминальной цепочки,

начинающейся с 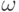 и продолжающейся упомянутыми k
терминалами.
и продолжающейся упомянутыми k
терминалами.
Грамматика называется LL(k)-грамматикой, если она LL(k)-грамматика для некоторого k.
Пример 4.7. Рассмотрим грамматику G = ({S, A, B}, {0, 1, a, b}, P, S), где P состоит из правил
S -> A | B, A -> aAb | 0, B -> aBbb | 1.
Здесь  . G не является
LL(k)-грамматикой ни для какого k. Интуитивно, если мы
начинаем с чтения достаточно длинной цепочки, состоящей из
символов a, то не знаем, какое из правил S -> A и S -> B было применено первым, пока не встретим 0 или 1.
. G не является
LL(k)-грамматикой ни для какого k. Интуитивно, если мы
начинаем с чтения достаточно длинной цепочки, состоящей из
символов a, то не знаем, какое из правил S -> A и S -> B было применено первым, пока не встретим 0 или 1.
Обращаясь к точному определению LL(k)-грамматики,
положим  и y = ak1b2k.
Тогда выводы
и y = ak1b2k.
Тогда выводы
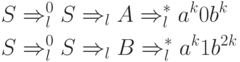
соответствуют выводам (1) и (2) определения. Первые k символов
цепочек x и y совпадают. Однако заключение ложно. Так как k здесь выбрано произвольно, то G не является LL-грамматикой.
Следствия определения LL(k)- грамматики
Теорема 4.6. КС-грамматика является LL(k)-грамматикой тогда и только тогда, когда для двух
различных правил  и
и 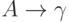 из Р пересечение
из Р пересечение  пусто при всех таких
пусто при всех таких  ,
что
,
что 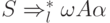 .
.
Доказательство. Необходимость. Допустим, что  и
и 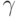 удовлетворяют условиям теоремы, а содержит x. Тогда по определению FIRST для
некоторых y и z
найдутся выводы
удовлетворяют условиям теоремы, а содержит x. Тогда по определению FIRST для
некоторых y и z
найдутся выводы

(Заметим, что здесь мы использовали тот факт, что N не
содержит бесполезных нетерминалов, как это предполагается
для всех рассматриваемых грамматик.) Если |x| < k ; то y = z = e. Так как 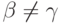 , то G не LL(k)-грамматика.
, то G не LL(k)-грамматика.
Достаточность. Допустим, что G не LL(k)-грамматика.
Тогда найдутся такие два вывода

что цепочки x и y совпадают в первых k позициях, но . Поэтому и - различные правила из P и каждое
из множеств  и
и  содержит цепочку FIRSTk(x), совпадающую с цепочкой FIRSTk(y).
содержит цепочку FIRSTk(x), совпадающую с цепочкой FIRSTk(y).
Пример 4.8. Грамматика G, состоящая из двух правил S -> aS | a, не будет LL(1)-грамматикой, так как
FIRST1(aS) = FIRST1(a) = a.
Интуитивно это можно объяснить так: видя при разборе
цепочки, начинающейся символом a, только этот первый символ,
мы не знаем, какое из правил S -> aS или S -> a надо применить
к S. С другой стороны, G - это LL(2)-грамматика. В самом деле, в
обозначениях только что представленной теоремы, если , то A = S и  . Так как для S даны только два указанных правила, то
. Так как для S даны только два указанных правила, то  и
и  . Поскольку FIRST2(aS) = aa и FIRST2(a) = a, то по последней теореме G будет LL(2)-грамматикой.
. Поскольку FIRST2(aS) = aa и FIRST2(a) = a, то по последней теореме G будет LL(2)-грамматикой.
Удаление левой рекурсии
Основная трудность при использовании предсказывающего анализа - это нахождение такой грамматики для входного языка, по которой можно построить таблицу анализа с однозначно определенными входами. Иногда с помощью некоторых простых преобразований грамматику, не являющуюся LL(1), можно привести к эквивалентной LL(1)-грамматике. Среди этих преобразований наиболее эффективными являются левая факторизация и удаление левой рекурсии. Здесь необходимо сделать два замечания. Во-первых, не всякая грамматика после этих преобразований становится LL(1), и, во-вторых, после таких преобразований получающаяся грамматика может стать менее понимаемой.
Непосредственную левую рекурсию, то есть рекурсию
вида  , можно удалить следующим способом. Сначала
группируем A -правила:
, можно удалить следующим способом. Сначала
группируем A -правила:

где никакая из строк 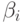 не начинается с A. Затем заменяем этот набор правил на
не начинается с A. Затем заменяем этот набор правил на

где A' - новый нетерминал. Из нетерминала A можно вывести те же цепочки, что и раньше, но теперь нет левой рекурсии. С помощью этой процедуры удаляются все непосредственные левые рекурсии, но не удаляется левая рекурсия, включающая два или более шага. Приведенный ниже алгоритм 4.8 позволяет удалить все левые рекурсии из грамматики.
Алгоритм 4.8. Удаление левой рекурсии.
Вход. КС-грамматика G без e-правил (вида A -> e ).
Выход. КС-грамматика G' без левой рекурсии, эквивалентная G.
Метод. Выполнить шаги 1 и 2.
(1) Упорядочить нетерминалы грамматики G в произвольном порядке.
(2) Выполнить следующую процедуру:

После (i-1) -й итерации внешнего цикла на шаге 2 для
любого правила вида  , где k < i, выполняется s > k.
В результате на следующей итерации (по i ) внутренний цикл
(по j ) последовательно увеличивает нижнюю границу по m в
любом правиле
, где k < i, выполняется s > k.
В результате на следующей итерации (по i ) внутренний цикл
(по j ) последовательно увеличивает нижнюю границу по m в
любом правиле  , пока не будет m >= i. Затем, после удаления непосредственной левой рекурсии для Ai -правил, m становится больше i.
, пока не будет m >= i. Затем, после удаления непосредственной левой рекурсии для Ai -правил, m становится больше i.
Алгоритм 4.8 применим, если грамматика не имеет e - правил (правил вида A -> e ). Имеющиеся в грамматике e - правила могут быть удалены предварительно. Получающаяся грамматика без левой рекурсии может иметь e -правила.
Левая факторизация
Oсновная идея левой факторизации в том, что в том случае, когда неясно, какую из двух альтернатив надо использовать для развертки нетерминала A, нужно изменить A -правила так, чтобы отложить решение до тех пор, пока не будет достаточно информации для принятия правильного решения.
Если 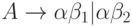 - два A -правила и входная цепочка
начинается с непустой строки, выводимой из
- два A -правила и входная цепочка
начинается с непустой строки, выводимой из 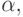 мы не знаем,
разворачивать ли по первому правилу или по второму. Можно
отложить решение, развернув
мы не знаем,
разворачивать ли по первому правилу или по второму. Можно
отложить решение, развернув  . Тогда после анализа
того, что выводимо из можно развернуть по
. Тогда после анализа
того, что выводимо из можно развернуть по  или по
или по  . Левофакторизованные правила принимают вид
. Левофакторизованные правила принимают вид


Алгоритм 4.9. Левая факторизация грамматики.
Вход. КС-грамматика G.
Выход. Левофакторизованная КС-грамматика G', эквивалентная G.
Метод. Для каждого нетерминала A найти самый
длинный префикс общий для двух или более его
альтернатив. Если  , то есть существует нетривиальный
общий префикс, заменить все A -правила
, то есть существует нетривиальный
общий префикс, заменить все A -правила
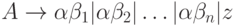 ,
,
где z обозначает все альтернативы, не начинающиеся с на


где A' - новый нетерминал. Применять это преобразование, пока никакие две альтернативы не будут иметь общего префикса.
Пример 4.9. Рассмотрим вновь грамматику условных операторов из примера 4.6:
S -> if E then S | if E then S else S | a E -> b
После левой факторизации грамматика принимает вид
S -> if E then SS' | a S' -> else S | e E -> b
К сожалению, грамматика остается неоднозначной, а значит, и не LL(1)-грамматикой.