
|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 304 / 36 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Самостоятельная работа 3: Оптимизация вычислений в задаче о разложении чисел на простые сомножители. Векторизация и балансировка нагрузки
Распределение вычислений с использованием динамического планировщика и подбор размера порции
Рассмотрим еще один подход к распределению нагрузки в задаче разложения чисел из диапазона от 1 до  . Суть подхода состоит в том, чтобы разделить множество факторизуемых чисел на группы и делить группы между потоками чередованием. На
рис.
8.12 показан пример распределения чисел при создании четырех потоков.
. Суть подхода состоит в том, чтобы разделить множество факторизуемых чисел на группы и делить группы между потоками чередованием. На
рис.
8.12 показан пример распределения чисел при создании четырех потоков.
Модифицируем код функции факторизации так, чтобы можно было подобрать размер порции.
void factorization(int chunk)
{
#pragma omp parallel for schedule(dynamic, chunk)
for (int i = 1; i < NUM_NUMBERS; i++)
{
int number = i;
int idx = number;
for (int j = 2; j < idx; j++)
{
if (number == 1) break;
int r;
r = number % j;
if (r == 0)
{
number /= j;
divisors[idx].push_back(j);
j--;
}
}
}
}
Дополнительно реализуем функцию очистки списков факторов чисел.
void clean()
{
for (int i = 1; i < NUM_NUMBERS; i++)
{
divisors[i].resize(0);
}
}
Модифицируем функцию main для поиска оптимального размера порции.
int main()
{
…
cout << "Calculation time : " << endl;
for (int i = 10; i < 100; i+=10)
{
#pragma offload target(mic:0)
{
clean();
}
chunk = i;
time_s = omp_get_wtime( );
#pragma offload target(mic:0)
{
factorization(chunk);
}
time_f = omp_get_wtime( );
cout << chunk << ";" << (time_f - time_s) << endl;
}
for (int i = 0; i <= 10; i++)
{
#pragma offload target(mic:0)
{
clean();
}
chunk = 100 + i * 50;
time_s = omp_get_wtime( );
#pragma offload target(mic:0)
{
factorization(chunk);
}
time_f = omp_get_wtime( );
cout << chunk << ";" << (time_f - time_s) << endl;
}
…
}
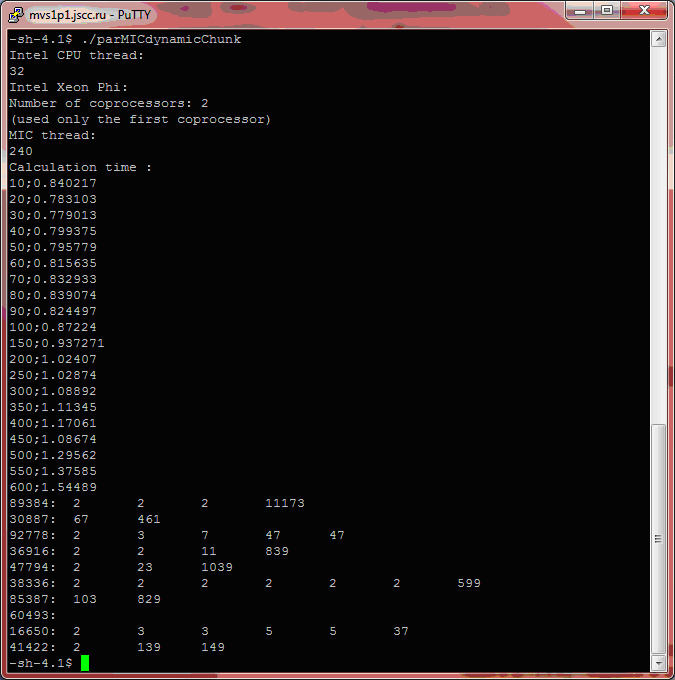
Скомпилируем и выполним код. На рис. 8.13 представлен результат выполнения программы.
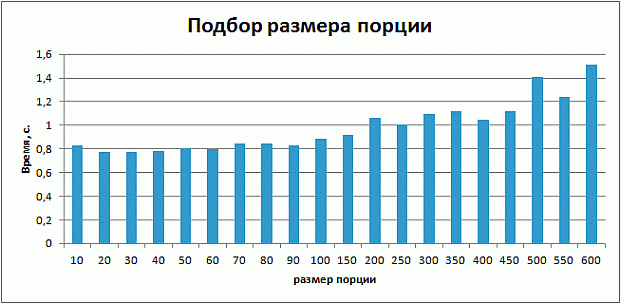
На рис. 8.14 представлен график времени выполнения алгоритма факторизации чисел, при разных размерах порции.
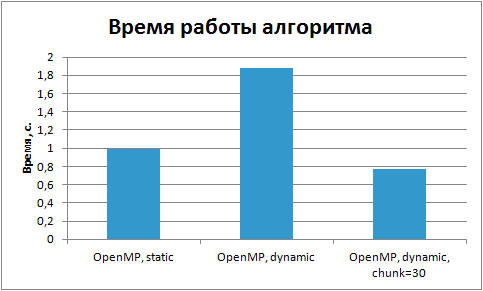
Из графика видно, что оптимальный размер порции составляет 30. На рис. 8.15 представлен график сравнения времени выполнения реализованных параллельных реализаций алгоритма факторизации чисел.
Как видно из представленного графика, динамическое планирование при правильном подборе размера порции позволило получить большее ускорение вычислений.
Применение динамического планирования не является единственным рычагом повышения производительности кода. В дополнительных заданиях предлагается попробовать ряд других оптимизаций.
Svetlana Svetlana