
|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 304 / 36 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Самостоятельная работа 3: Оптимизация вычислений в задаче о разложении чисел на простые сомножители. Векторизация и балансировка нагрузки
Перенос вычислений на сопроцессор Intel Xeon Phi
В качестве следующего шага перенесем вычисления последовательного кода на сопроцессор Intel Xeon Phi. Для этого воспользуемся директивой #pragma offload target(mic:0).
time_s = omp_get_wtime( );
#pragma offload target(mic:0)
{
factorization();
}
time_f = omp_get_wtime( );
Далее проведем попытку скомпилировать полученный код. Получим следующий вывод компилятора с ошибками:
./singleMIC.cpp(44): error: function "factorization" called in offload region must have been declared
with compatible "target" attribute
factorization();
Intel Xeon Phi имеет свои операционную систему и окружение. Код, исполняемый на MIC, должен быть скомпилирован отдельно. В программной реализации алгоритма факторизации чисел не было указаний компилятору дополнительно скомпилировать для MIC функцию факторизации, что и привело к появлению ошибки. Чтобы исправить данную ошибку, необходимо объявление функций и сами функции обернуть директивами, как показано ниже:
#pragma offload_attribute(push, target(mic))
#include <iostream>
#include "omp.h"
#include <vector>
using namespace std;
#define NUM_NUMBERS 100000
vector<int> divisors[NUM_NUMBERS+1];
void factorization(int chunk);
int testThreadCount();
#pragma offload_attribute(pop)
…
#pragma offload_attribute(push, target(mic))
int testThreadCount() {
int thread_count;
#pragma omp parallel
{
#pragma omp single
thread_count = omp_get_num_threads();
}
return thread_count;
}
void factorization()
{…}
#pragma offload_attribute(pop)
Попробуем скомпилировать программу. Программа должна откомпилироваться без ошибок.
Для того чтобы убедится, что вычисления производятся на сопроцессоре, и узнать его параметры (количество создаваемых потоков), дополнительно модифицируем функцию main.
int main()
{
double time_s, time_f;
int intel_th, mic_th;
intel_th = testThreadCount();
cout << "Intel CPU thread:\n" << intel_th << endl;
int number_of_coprocessors = _Offload_number_of_devices();
if(number_of_coprocessors < 1)
{
cout << "for the program to need at least one Intel Xeon Phi coprocessor \n";
return -1;
}
cout << "Intel Xeon Phi:\n";
cout << "Number of coprocessors: " << number_of_coprocessors << endl;
cout << "(used only the first coprocessor)" << endl;
#pragma offload target(mic:0)
{
mic_th = testThreadCount();
}
cout << "MIC thread:\n" << mic_th << endl;
time_s = omp_get_wtime( );
#pragma offload target(mic:0)
{
factorization();
}
time_f = omp_get_wtime( );
…
}
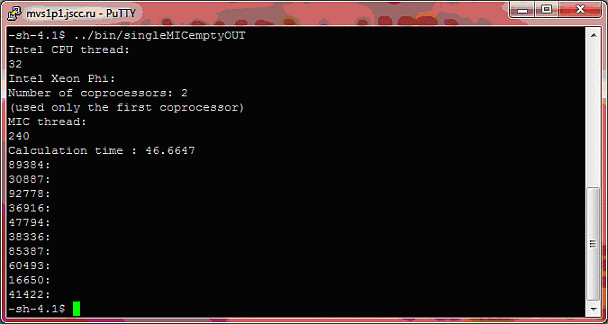
Откомпилируем и запустим программу. Результат выполнения программы представлен на рис. 8.3.
Как вы думаете, почему в результате вычислений не отобразились факторы чисел?
Правильный ответ – память центрального процессора и сопроцессора не являются общими. Как следствие при объявлении глобальных данных, память под хранения данных выделяется как на центральном процессоре, так и на сопроцессоре. Изменение данных на сопроцессоре не влечет изменение данных на центральном процессоре.
Разработаем дополнительно две функции, которые позволят получить данные с сопроцессора.
Первая функция получает на вход количество изымаемых чисел и их номера. Последним параметром передается массив размера на единицу больше количества получаемых чисел. Каждых элемент массива – сумма размеров длин векторов для изымаемых факторов чисел начиная с первого и до текущего. Последний элемент массива – общее количество чисел фактора, которое необходимо получить на центральном процессоре. Ниже приведен код функции:
void getSizeVector(int count, int * num, int *size)
{
int sum = 0;
int i = 0;
for (i = 0; i < count; i++)
{
int Idx = num[i];
size[i] = sum ;
sum += static_cast<int>(divisors[Idx].size());
}
size[i] = sum;
}
Вторая функция также получает на вход количество изымаемых чисел и их номера. Возвращает функция последовательно записанные в вектор факторы чисел. Ниже приведен код второй функции:
void getVector(int count, int * num, int *pn)
{
int i = 0;
int size = 0;
int k = 0;
for (i = 0; i < count; i++)
{
int Idx = num[i];
size = static_cast<int>(divisors[Idx].size());
for (int j = 0; j < size;j++)
{
pn[k] = divisors[Idx][j];
k++;
}
}
}
Модифицируем код функции main так, чтобы факторы чисел выводились корректно.
int main()
{
…
time_s = omp_get_wtime( );
#pragma offload target(mic:0)
{
factorization();
}
time_f = omp_get_wtime( );
cout<< "Calculation time : " << (time_f - time_s)
<< endl;
// Получаем количество простых сомножителей
int num[10], countNum[11], * pn, sum;
for (int i = 0; i < 10; i++)
{
int randomIdx = 1 + rand() % NUM_NUMBERS;
num[i] = randomIdx;
}
#pragma offload target(mic:0)
in(num[0:10]) out(countNum[0:11])
{
getSizeVector(10, num, countNum);
}
sum = countNum[10];
pn = new int [sum];
#pragma offload target(mic:0)
in(num[0:10]) out(pn[0:sum])
{
getVector(10, num, pn);
}
// Вывод простых сомножителей произвольных 10 чисел
for (int i = 0; i < 10; i++)
{
cout << num[i] << ":\t";
for (int j = countNum[i]; j < countNum[i + 1];j++)
{
cout << pn[j] << "\t";
}
cout << endl;
}
delete []pn;
return 0;
}
Скомпилируем и выполним полученный код. На рис. 8.4 приведен результат выполнения программы.
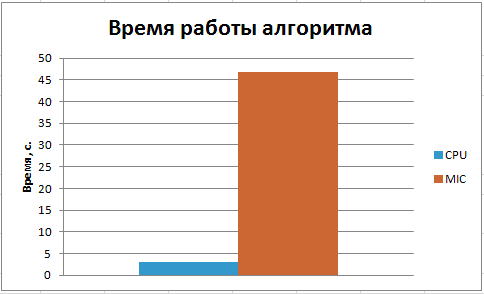
На рис. 8.5 приведен график сравнения производительности кода, запущенного на центральном процессоре и на Intel Xeon Phi.
Как видно из графика, центральный процессор приблизительно в пятнадцать раз обогнал сопроцессор Intel Xeon Phi. Причина заключается в том, что ядра сопроцессора гораздо более простые (с точки зрения архитектуры) и обладают меньшей тактовой частотой, чем ядра центрального процессора. Основное преимущество Intel Xeon Phi в том, что ядер, пусть и простых, очень много. У сопроцессора Intel Xeon Phi 60 ядер против 8 центрального процессора. Также каждое ядро Intel Xeon Phi поддерживает четыре потока. Итого на ускорителе может выполняться 240 потоков. Следует учитывать, что для эффективного использования ядер сопроцессора необходимо, чтобы код был векторизован.
Svetlana Svetlana