
|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Спонсор: Intel
Вы можете этот курс.
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 304 / 36 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Самостоятельная работа 3: Оптимизация вычислений в задаче о разложении чисел на простые сомножители. Векторизация и балансировка нагрузки
Последовательная реализация алгоритма
Начнем реализацию алгоритма с создания файла single.cpp. Для этого можно выполнить следующую команду:
-sh-4.1$ > single.cpp
Далее созданный файл можно редактировать любым привычным редактором. Один из редакторов с дружественным интерфейсом mcedit. Для редактирования файла необходимо выполнить команду:
-sh-4.1$ mcedit ./single.cpp
В результате откроется окно редактора, в котором можно разрабатывать программную реализацию алгоритма.
Начнем разработку программы с подключения необходимых заголовочных файлов и объявления констант.
#include <iostream> #include "omp.h" #include <vector> using namespace std; // Количество факторизуемых чисел #define NUM_NUMBERS 100000 // Вектора используемые для хранения // простых сомножителей чисел vector<int> divisors[NUM_NUMBERS+1];
Далее объявим две вспомогательные функции, используемые при реализации алгоритма:
// Получение количества создаваемых потоков int testThreadCount(); // Функция факторизации чисел void factorization();
Реализация данных функций будет приведена позднее.
Далее разработаем главную функцию программы main.
int main()
{
// Обявление переменных
double time_s, time_f;
int intel_th;
// Вывод количества создаваемых потоков
intel_th = testThreadCount();
cout << "Intel CPU thread:\n" << intel_th << endl;
// Проведение вычислительного эксперимента
time_s = omp_get_wtime( );
factorization();
time_f = omp_get_wtime( );
cout<< "Calculation time : " << (time_f - time_s)
<< endl;
// Вывод простых множителей произвольных 10 чисел
for (int i = 0; i < 10; i++)
{
int randomIdx = 1 + rand() % NUM_NUMBERS;
cout << randomIdx << ":\t";
int size;
size = static_cast<int>(divisors[randomIdx].size());
for (int j = 0; j < size;j++)
{
cout << divisors[randomIdx][j] << "\t";
}
cout << endl;
}
return 0;
}
Ниже приведем код получения количества создаваемых потоков.
int testThreadCount() {
int thread_count;
#pragma omp parallel
{
#pragma omp single
thread_count = omp_get_num_threads();
}
return thread_count;
}
В финале разработаем код алгоритма факторизации чисел приведенный в виде псевдокода разделе 2.
void factorization()
{
for (int i = 1; i < NUM_NUMBERS; i++)
{
int number = i;
int idx = number;
for (int j = 2; j < idx; j++)
{
if (number == 1) break;
int r;
r = number % j;
if (r == 0)
{
number /= j;
divisors[idx].push_back(j);
j--;
}
}
}
}
Код готов.
Для проведения экспериментов в рамках вычислительных ресурсов МСЦ РАН необходимо вначале зарезервировать вычислительный узел. Сделать это можно с помощью команды salloc. Пример резервирования узла кластера представлен ниже:
-sh-4.1$ salloc -N 1 --gres=mic:1 salloc: Pending job allocation 9404 salloc: job 9404 queued and waiting for resources salloc: job 9404 has been allocated resources salloc: Granted job allocation 9404
Посмотреть имя выделенного хоста можно в переменной окружения SLURM_NODELIST.
-sh-4.1$ echo $SLURM_NODELIST node196
Перейдем на выделенный хост.
-sh-4.1$ ssh $SLURM_NODELIST -sh-4.1$ hostname node196
Далее откомпилируем код и выполним его.
-sh-4.1$ icpc -O2 -openmp single.cpp –osingle -sh-4.1$ ./single
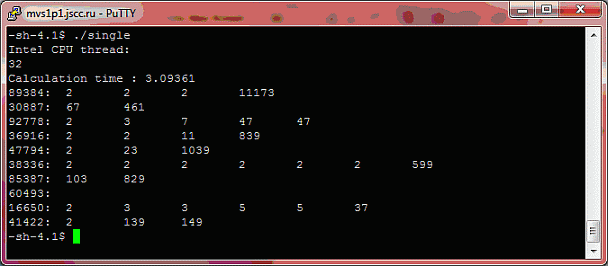
На рис. 8.1 приведен результат работы последовательной версии алгоритма.
Ниже, на рис. 8.2 приведено время работы алгоритма:
Svetlana Svetlana