


|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 309 / 38 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Дополнительный материал 3: Высокопроизводительная библиотека MPI для организации обмена сообщениями в кластерах Intel MPI Library 4.1
< Дополнительный материал 2 || Дополнительный материал 3 || Дополнительный материал 4 >
Ключевые слова: MPI, library, быстродействие, message passing, interface, программное обеспечение, пользователь, available, tools, build, verify, AND, application, this, blue, with, volume
Орингинал текста Вы можете скачать здесь.
Главные особенности
- Масштабируется до 120 тыс. процессов
- Показатели задержки - самые низкие в отрасли
- Независимость от типа межсоединений, гибкий выбор в период исполнения
- Утилита оптимизации приложений MPI по быстродействию
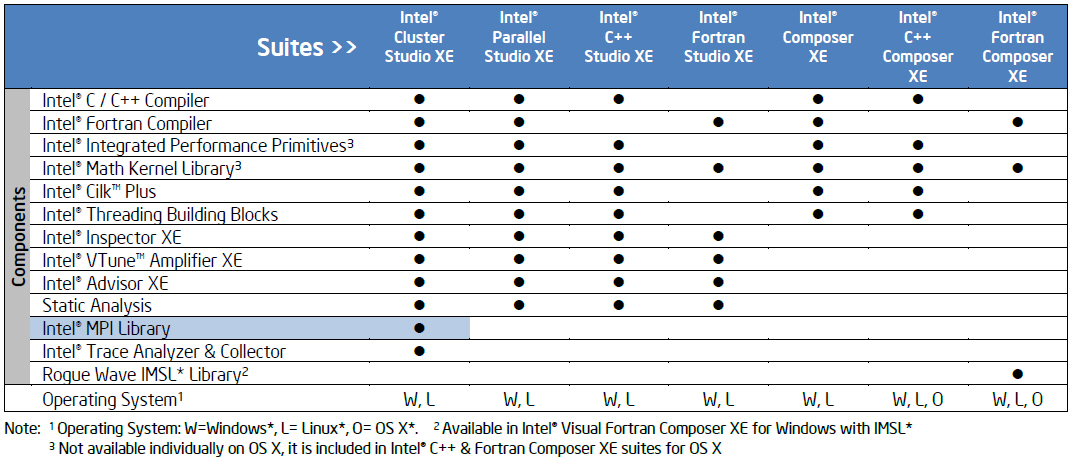
Доступность в других конфигурациях:
- Intel® Cluster Studio XE
- Intel® Cluster Studio
Интероперабельность с другими продуктами
- Intel® Composer XE
- Intel® VTune. Amplifier XE
- Intel® Inspector XE
- Intel® Math Kernel Library
- Intel® Trace Analyzer and Collector
Поддержка операционных систем:
- Windows*
- Linux*
"В компании S & I Engineering Solutions Pvt, Ltd. занимаются разработкой быстрых и точных методов решения задач вычислительной гидродинамики. Важнейшими факторами при выборе библиотек MPI для нас являются масштабируемость и эффективность. Библиотека Intel MPI Library позволяет нашим алгоритмам масштабироваться более чем до 10 тыс. ядер, обеспечивая при этом высокие эффективность и быстродействие."
Гибкий, эффективный, масштабируемый обмен сообщениями в кластерах
Библиотека Intel MPI Library позволяет повышать быстродействие приложений, работающих на кластерах архитектуры Intel. Она реализует высокопроизводительный протокол Message Passing Interface Version 2.2, поддерживая различные типы межсоединений. Библиотека позволяет быстро обеспечивать максимальное быстродействие, в том числе при замене или модернизации межсоединений; при этом не нужно вносить изменения в программное обеспечение и операционную среду.
Данную высокопроизводительную библиотеку MPI можно применять для создания приложений, работающих поверх кластерных межсоединений разных типов, выбирать которые может пользователь в период исполнения. Для продуктов, разработанных с помощью Intel MPI Library, предоставляется не требующий лицензионных отчислений комплект среды выполнения. Библиотека позволяет обеспечить превосходное быстродействие высокопроизводительным вычислительным приложениям для предприятий, подразделений, отделов, рабочих групп, а также персональным.
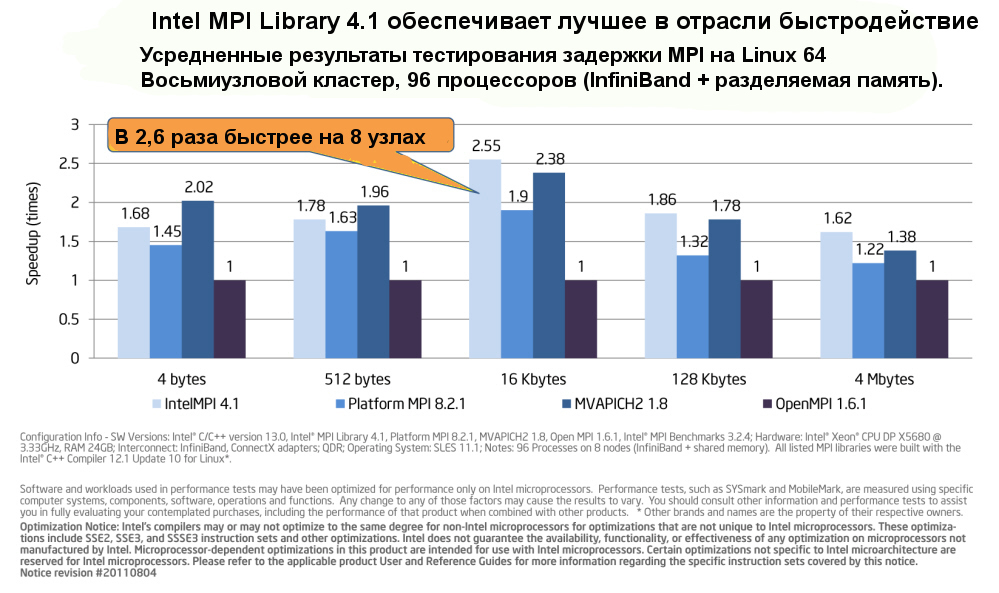
увеличить изображение
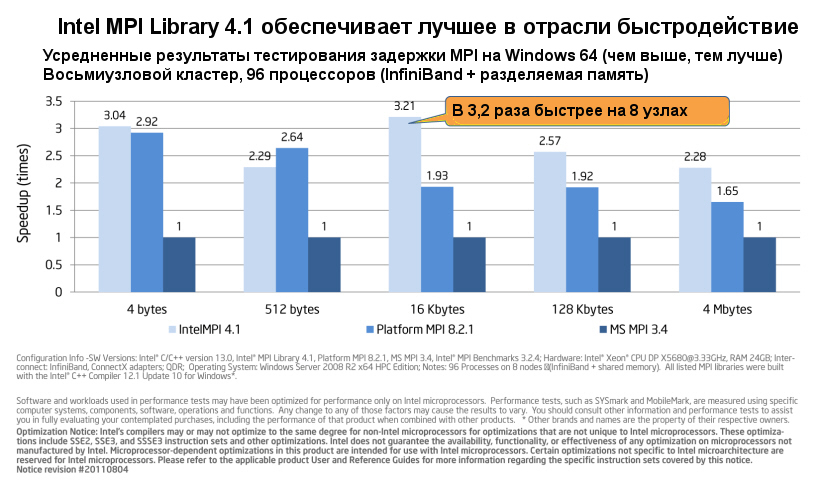
Intel MPI Library (Intel MPI) уменьшает задержку MPI, способствуя тем самым повышению пропускной способности.
Главные особенности
Масштабируемость
|
|
Быстродействие
|
|
Независимость от типа межсоединений и гибкость выбора протокола в период выполнения
|
Подробности
Масштабируемость
Intel MPI Library 4.1 для Windows и Linux реализует отличающуюся высокой производительностью версию 2.2 спецификации MPI-2 для различных типов межсоединений. Назначение библиотеки - повышать быстродействие приложений на кластерах архитектуры IA. Intel MPI Library позволяет быстро обеспечить максимальный уровень быстродействия приложениям конечных пользователей, в том числе при замене или модернизации межсоединений; при этом не понадобится вносить серьезные изменения в ПО или операционную среду. Intel также предоставляет бесплатный комплект среды выполнения для программных продуктов, разработанных с использованием Intel MPI Library
Быстродействие
Оптимизированный интерфейс разделяемой памяти обеспечивает увеличенную пропускную способность и снижает задержку. Дополнительно ее уменьшению способствует нативный интерфейс InfiniBand (OFED Verbs). Благодаря многоканальной передаче данных обеспечивается повышение пропускной способности и ускорение межпроцессной связи, а поддержка Tag Matching Interface (TMI) увеличивает производительность при использовании межсоединений Qlogic* PSM и Myricom* MX.
Intel MPI Library поддерживает многие сетевые технологии
Intel MPI Library поддерживает TCP-сокеты, разделяемую память и различные межсоединения на основе удаленного прямого доступа к памяти (RDMA). Библиотека реализует универсальный слой поддержки межсоединений разного типа посредством методологий Direct Access Programming Library (DAPL*) и Open Fabrics Association (OFA*). Разрабатывая код для MPI, можно быть уверенным, что он будет эффективно работать независимо от того, какой тип межсоединений пользователь выбрал в период выполнения.
Кроме того, Intel MPI Library обеспечивает высокие быстродействие и гибкость для приложений за счет улучшенной поддержки интерфейсов межсоединений Myrinet* MX и QLogic* PSM, более быстрого обмена сообщениями на узлах и механизма оптимизации, адаптирующегося в зависимости от архитектуры кластера и структуры приложения.
Intel MPI Library динамически устанавливает соединение, но только по мере необходимости, за счет чего уменьшается расход памяти. Кроме того, библиотека автоматически выбирает самый быстрый из доступных транспортных протоколов. Потребности в памяти снижаются с применением нескольких методов, в том числе с помощью механизма двухэтапного увеличения коммуникационного буфера, резервирующего в точности требуемый объем памяти.
Что нового
| Особенность | Преимущество |
|---|---|
| Повышение быстродействия MPI | Новый диспетчер соединений и механизмы автовыбора улучшают масштабируемость при использовании межсоединений на основе RDMA. Улучшенная поддержка приложений NUMA и новые развитые средства управления привязкой процессов позволяют разрабатывать и развертывать приложения с расчетом на дальнейший рост мощности высокопроизводительных вычислительных систем. |
| Улучшенная масштабируемость в Windows | Высокомасштабируемый диспетчер процессов Hydra теперь доступен в экспериментальной реализации для кластеров под Windows. |
| Поддержка самых новых процессоров - Haswell, Ivy Bridge и сопроцессоров Intel® Xeon Phi™ | В Intel неизменно первыми выпускают инструменты, пользующиеся усовершенствованиями самых новых продуктов корпорации, сохраняя при этом совместимость с предыдущими процессорами Intel и аналогами. Библиотека MPI поддерживает характеристики шин перечисленных процессоров и реализует новые алгоритмы копирования и доступа к памяти. |
Варианты приобретения: пакеты для одного языка
Several suites are available combining the tools to build, verify and tune your application. The products covered in this product brief are highlighted in blue. Named-user or multi-user licenses along with volume, academic, and student discounts are available.
Технические характеристики
| Коротко о характеристиках | |
|---|---|
| Поддержка процессоров | Библиотека аттестована на совместимость с несколькими поколениями процессоров Intel и аналогов, в том числе с Intel Core 2 второго поколения, Intel Core 2, Intel Core, Intel Xeon, Intel Core и сопроцессором Intel Xeon Phi. |
| Операционные системы | Windows* и Linux* |
| Языки прогаммирования | Нативная поддержка C и Fortran |
| Системные требования | Подробные требования к аппаратному и программному обеспечению доступны по ссылке www.intel.com/software/products/systemrequirements/ for details on hardware and software requirements. |
| Поддержка | Для приложений, разработанных с помощью Intel MPI Library, доступен бесплатный комплект периода исполнения. Обновления продукта, услуги Intel Premier Support и доступ к форумам поддержки Intel предоставляются в течение одного года. Служба Intel Premier Support позволяет получать защищенные веб-консультации от инженеров Intel. |
Чтобы узнать больше о Intel MPI Library,
|
Скачайте бесплатную 30-дневную пробную версию
|
| Optimization Notice | Notice revision #20110804 |
| Оптимизации, не рассчитанные исключительно на микропроцессоры Intel, на процессорах других производителей могут быть менее эффективными. В частности, это касается оптимизаций наборов команд SSE2, SSE3, SSSE3, а также других. Intel не гарантирует доступность, функциональность и эффективность любой оптимизации на микропроцессорах, выпущенных другими производителями. Оптимизации перечисленных в документе продуктов, зависящие от микропроцессоров, предназначены для микропроцессоров Intel. Некоторые оптимизации, не характерные для микроархитектуры Intel, резервируются только для микропроцессоров Intel. Дополнительную информацию о конкретных наборах инструкций, к которым относится данное уведомление, можно получить из соответствующих руководств пользователя и справочников. | |
< Дополнительный материал 2 || Дополнительный материал 3 || Дополнительный материал 4 >
Svetlana Svetlana