
|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 309 / 38 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Лекция 2:
Архитектура Intel Xeon Phi
Аннотация: В данном разделе курса описывается аппаратная архитектура и программная модель сопроцессора Intel Xeon Phi.
Ключевые слова: архитектура, программная модель, ядро, шина, компонент, производительность, хост-система , вычислительная система, операционная система, RED, hat, enterprise, server, операционная система хоста , хост, сопроцессор , программное обеспечение, операционная система сопроцессора , , запуск, PCI, декодирование, FLOPS, умножение, сложение, MMX, SSE, выборка, thread, буфер, round robin, кэш, decode, Instruction, microcode, control, операции, execution, инструкция, ALU, векторные, латентность, память, алгоритм, TLB, PAE, PSE, запись, DMA, операции передачи данных, байт
Введение
Презентацию к лекции Вы можете скачать здесь.
В данном разделе курса описывается аппаратная архитектура и программная модель сопроцессора Intel Xeon Phi. Рассматриваются основные архитектурные блоки и особенности сопроцессора: ядро, блок векторной обработки данных, встроенная высокопроизводительная двунаправленная кольцевая шина, полностью когерентные кэши L2 и принципы взаимодействия компонент. Основное внимание уделяется элементам, наиболее существенно влияющим на производительность вычислений и понимание способов оптимизации программ для архитектуры Intel Xeon Phi
Используемая терминология
Хост, хост-система, базовая система – вычислительная система на базе Intel Xeon и совместимых с ним процессоров, в которой установлен сопроцессор Intel Xeon Phi. На хосте может работать операционная система семейств Red Hat Enterprise Linux 6.x или SUSE Linux Enterprise Server SLES 11.
Операционная система хоста, ОС хоста – операционная система, установленная на хост-системе.
Сопроцессор, целевая система – сопроцессор Intel Xeon Phi и установленное на нем программное обеспечение.
uOS, Micro Operating System, операционная система сопроцессора – операционная система, установленная на сопроцессоре, базируется на ядре Linux.
MPSS, Intel Manycore Platform Software Stack – совокупность программного обеспечения системного и пользовательского уровней, обеспечивающая запуск и выполнение программ на сопроцессоре Intel Xeon Phi.
Архитектура сопроцессора Intel Xeon Phi
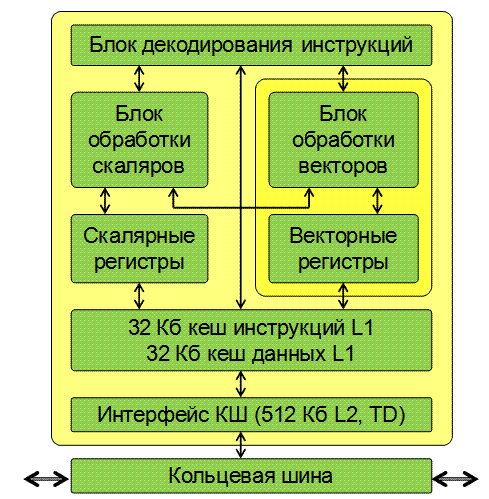
Сопроцессор Intel Xeon Phi включает до 61 процессорных ядер, соединенных высокопроизводительной встроенной кольцевой шиной. 8 контроллеров памяти обслуживают 16 каналов GDDR5, обеспечивая суммарную производительность 5,5 GT/s (миллиардов пересылок в секунду, при ширине шины 64 байта это дает пропускную способность 352 GB/s). Отдельный компонент реализует клиентскую логику PCI Express (см. рис. 2.1).
Каждое ядро является полнофункциональным и поддерживает выборку и декодирование инструкций из 4 потоков команд. Для повышения эффективности работы с памятью в сопроцессоре реализован распределенный каталог тегов кэша, позволяющий использовать более эффективный протокол для поддержания когерентности кэшей всех ядер. Контроллеры памяти обеспечивают теоретическую пропускную способность 352 гигабайта в секунду. Приведем основные характеристики компонент сопроцессора.
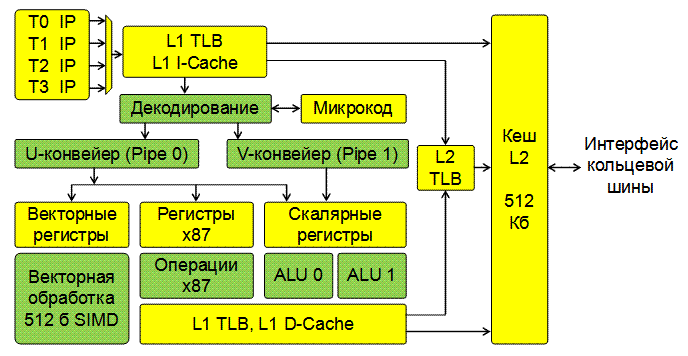
- Исполнительное ядро (Core) выполняет выборку и декодирование инструкций 4 аппаратных потоков. Поддерживается выполнение 32- и 64-битного кода, совместимого с архитектурой Intel64. Ядро содержит 2 конвейера (U-конвейер и V-конвейер) и может выполнять 2 инструкции за такт. V-конвейер способен выполнять не все типы инструкций, возможность параллельного выполнения команд на U- и V-конвейерах задается набором правил. Внеочередное выполнение инструкций не поддерживается, также не реализованы команды Intel Streaming SIMD Extensions (SSE), MMX и Advanced Vector Extensions (AVX). Ядро включает по 32 Кб 8-канальных множественно-ассоциативных кэшей инструкций и данных (L1 I-Cache и L1 D-Cache).
Ядро сопроцессора Intel Xeon Phi содержит следующие компоненты (см. рис. 2.2).
- 512-битный блок векторных вычислений (vector processor unit, VPU) включает расширенный блок математических вычислений (extended math unit, EMU) и способен посылать на выполнение по одной векторной операции на каждом такте (то есть обработать 16 чисел с плавающей точкой одинарной точности или 16 32-битных целых чисел или 8 чисел с плавающей точкой двойной точности). Для операций "умножение и сложение" (multiply-add, FMA) это дает выполнение 32 операций над числами с плавающей точкой за такт. Блок векторных вычислений содержит 32 512-битных регистра (zmm0-zmm31) и дополнительно обеспечивает выполнение операций заполнения и перестановки содержимого векторного регистра, вычисление для вещественных чисел одинарной точности степеней 2 (2x) и двоичного логарифма (log2x), обратного значения (1/x) и обратного квадратного корня (1/sqrt(x)). При выполнении операций один из аргументов может считываться из оперативной памяти с выполнением при необходимости преобразования типа.
- Интерфейс кольцевой шины (Core-Ring Interface, CRI/L2) обеспечивает подключение ядра к высокопроизводительному встроенному интерконнекту сопроцессора – кольцевой шине, а также включает 512 Кб 8-канального множественно-ассоциативного кэша L2, усовершенствованный программируемый контроллер прерываний (advanced programmable interrupt controller, APIC) и каталог тегов (Tag Directory, TD).
Каталог тегов (Tag Directory, TD) является частью распределенного каталога, обеспечивающего отслеживание всех адресов памяти, по которым происходило изменение данных всеми ядрами сопроцессора, и когерентность кэшей L2 всех ядер. Каждый тег содержит адрес, состояние и идентификатор владельца (кэша L2 какого-либо ядра) строки данных кэша. Пространство адресов оперативной памяти поровну разделено между каталогами тегов различных ядер, и ядро, на котором отсутствуют нужные данные, посылает запрос к соответствующему каталогу тегов через кольцевую шину.
- Контроллер памяти (GBOX, GDDR MC на рис. 2.1) включает три основных компонента: интерфейс кольцевой шины (FBOX), планировщик запросов (MBOX) и интерфейс к устройствам GDDR. Каждый контроллер памяти включает два независимых канала доступа к памяти. Все контроллеры памяти сопроцессора действуют независимо друг от друга.
- Компонент SBOX реализует клиентскую логику PCI Express, включая механизм прямого доступа к памяти (Direct Memory Access, DMA) и ограниченные возможности по управлению питанием.
- Двунаправленная кольцевая шина обеспечивает передачу данных между компонентами сопроцессора.
Сопроцессор Intel Xeon Phi содержит 61 ядро, но он исполняет собственную операционную систему, и одно ядро выделено для исполнения кода ОС, обслуживания прерываний и т.п. Поэтому в расчетах производительности предполагается, что для вычислений используется 60 ядер из имеющихся 61.
Теоретическая производительность сопроцессора Intel Xeon Phi с 60 ядрами и частотой 1,1 ГГц может быть вычислена следующим образом [2.1]:
- 16 (длина вектора) * 2 flops(FMA) * 1.1 (GHZ) * 60 (число ядер) = 2112 GFLOPS – для вещественных чисел одинарной точности
- 8 (длина вектора) * 2 flops (FMA) * 1.1 (GHZ) * 60 (число ядер) = 1056 GFLOPS – для вещественных чисел двойной точности.
2 flops за такт удается получить благодаря использованию инструкции "умножение и сложение" (multiply-add, FMA).
Конвейер ядра Intel Xeon Phi
Ядра Intel Xeon Phi обеспечивают выполнение 32- и 64-битного кода, совместимого с архитектурой Intel64 без поддержки расширений MMX, AVX и SSE (всех версий). Блок векторных вычислений, содержащийся в каждом ядре, дополнительно реализует набор операций над 512-битными векторами.
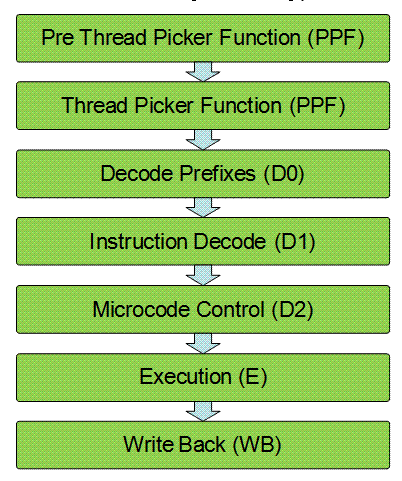
Конвейер ядра Intel Xeon Phi содержит 7 этапов, блок векторных вычислений также имеет конвейерную структуру и состоит из 6 этапов (см. рис. 2.3). Все этапы основного конвейера кроме последнего (WB), поддерживают спекулятивное выполнение. Каждое ядро может выполнять инструкции 4 потоков, что позволяет уменьшить потери из-за латентности доступа к памяти, выполнения векторных инструкций и т.д.
Выборка команд разбита на 2 этапа – PPF (pre thread picker) и PF (thread picker). На этапе PPF выполняется чтение инструкций потока исполнения в буфер предвыборки. На этапе PF производится выбор потока, инструкции которого будут выполняться, и передача пары инструкций для декодирования. Для каждого из четырех исполняющихся на ядре потоков имеется буфер предварительной выборки, который может содержать 2 инструкции для выполнения на U- и V-конвейерах ядра. Выбор инструкции для исполнения производится из заполненных буферов предвыборки согласно простому циклическому алгоритму (round robin).
Реализация выборки команд накладывает ограничение на выполнение потоков – на двух последовательных тактах не могут выбираться инструкции одного и того же потока. Таким образом, для полной загрузки ядра необходимо выполнять на нем по крайней мере два потока одновременно, а при работе только одного потока выборка инструкций будет выполняться через такт, что приведет к потере половины производительности. Для полной загрузки ядра достаточно выполнения на нем 2 потоков, однако, с учетом того, что заполнение буфера предварительной выборки требует 4-5 тактов при попадании в кэш инструкций и значительно больше при промахе, для обеспечения полной загрузки может потребоваться 3-4 потока.
После выбора пары инструкций для исполнения они отправляются на декодирование, состоящее из двух этапов – декодирование префиксов (Decode prefixes, D0) и декодирование инструкции (Instruction decode, D1), – которые выполняют декодирование двух инструкций за такт. На этапе D0 выполняется декодирование префиксов со штрафом от 0 до 2 тактов (для префиксов, унаследованных от старых архитектур). На этапе D1 выполняется декодирование инструкций с учетом результата декодирования префиксов. Далее следует этап управляемого выполнения микрокоманд (Microcode control, D2), на котором производятся операции чтения данных из регистров общего назначения, вычисления адреса и поиска и чтения данных из кэша.
Декодированные инструкции отправляются на этап исполнения (Execution, E), реализованный в виде двух конвейеров – U и V. Первая инструкция всегда отправляется на U-конвейер, для второй инструкции проверяется возможность одновременного выполнения с первой согласно набору правил парного выполнения команд, и в случае положительного решения она отправляется на V-конвейер. Скалярные целочисленные операции выполняются арифметико-логическими устройствами (ALU), для скалярных и векторных операций с вещественными числами используется дополнительный 6-стадийный конвейер. Векторные инструкции выполняются в основном на U-конвейере.
Большинство инструкций с целыми числами и масками имеют латентность 1, большинство векторных инструкций – 4 или более при использовании операций чтения/записи с заполнением или перестановкой.
Svetlana Svetlana