Объектная модель DOM XML
Структурный анализ (парсинг) XML
Все современные браузеры имеют встроенные XML анализаторы (парсеры) для чтения и обработки XML. Анализатор считывает XML документ, размещает его в памяти и преобразует в XML DOM объект, доступный для языков программирования. В данной лекции все примеры приведены на JavaScript.
Имеются некоторые отличия между анализаторами в Microsoft и в других браузерах. Первый поддерживает как загрузку XML файлов, так и текстовых строк, содержащих XML код, в то время как в других браузерах используются раздельные анализаторы. При этом все анализаторы имеют функции для перемещения по дереву XML документа, доступа, вставки и удаления узлов в дереве.
Рассмотрим пример загрузки XML объектов (файлов и строк) с помощью XML анализатора Microsoft.
xmlDoc=new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async="false";
xmlDoc.load("timetable.xml");В первой строке программы создается пустой объект XML документа Microsoft. Далее для предотвращения работы сценария до полной загрузки документа флаг асинхронности устанавливается в "false". В третьей строке содержится инструкция загрузить XML файл "timetable.xml".
В следующем примере происходит загрузка строки с XML кодом для последующего анализа.
xmlDoc=new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async="false";
xmlDoc.loadXML(txt);Следует обратить на разницу между методами load() и loadXML() по их назначению.
Замечание. Современные браузеры не допускают междоменные обращения к файлам из соображений безопасности, т.е. сама веб-страница (с программным кодом) и XML файл должны физически находиться на одном сервере. В противном случае браузер выдаст сообщение об ошибке доступа.
Ниже приведены также кроссплатформенные реализации загрузки XML файла и XML строки соответственно.
<html>
<body>
<script type="text/javascript">
try //Internet Explorer
{
xmlDoc=new ActiveXObject("Microsoft.XMLDOM");
}
catch(e)
{
try //Firefox, Mozilla, Opera, etc.
{
xmlDoc=document.implementation.createDocument("","",null);
}
catch(e) {alert(e.message)}
}
try
{
xmlDoc.async=false;
xmlDoc.load("timetable.xml");
document.write("xmlDoc is loaded, ready for use");
}
catch(e) {alert(e.message)}
</script>
</body>
</html><html>
<body>
<script type="text/javascript">
text="<timetable>";
text=text+"<lesson>";
text=text+"<timeFrom>08.00</timeFrom>";
text=text+"<subject>Deutsch</subject>";
text=text+"<teacher>Borisova</teacher>";
text=text+"</lesson>";
text=text+"/<timetable>";
try //Internet Explorer
{
xmlDoc=new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async="false";
xmlDoc.loadXML(text);}
catch(e)
{
try //Firefox, Mozilla, Opera, etc.
{
parser=new DOMParser();
xmlDoc=parser.parseFromString(text,"text/xml");
}
catch(e) {alert(e.message)}
}
document.write("xmlDoc is loaded, ready for use");
</script>
</body>
</html>Программный интерфейс XML DOM
В рамках DOM модели XML можно рассматривать как множество узловых объектов. Доступ к ним осуществляется с помощью JavaScript или других языков программирования. Программный интерфейс DOM включает в себя набор стандартных свойств и методов.
Свойства представляют некоторые сущности (например, <day> ), а методы - действия над ними (например, добавить <lesson> ).
В XML DOM используются практически те же свойства и методы, что и в HTML DOM.
Например, результатом выполнения следующего ниже JavaScript кода будет текстовое содержимое элемента <subject> в файле timetable.xml.
txt = xmlDoc.getElementsByTagName("subject")[0].childNodes[0].nodeValue;Результат: "Deutsch".
В рамках DOM XML возможны 3 способа доступа к узлам:
- С помощью метода getElementsByTagName(name) . При этом возвращаются все узлы с указанным именем тэга (в виде индексированного списка). Первый элемент в списке имеет нулевой индекс.
- Путем обхода узлов дерева с использованием циклических конструкций.
- Путем перемещения по дереву с использованием отношений между узлами.
Для определения длины списка узлов используется свойство length.
Перемещение между узлами дерева
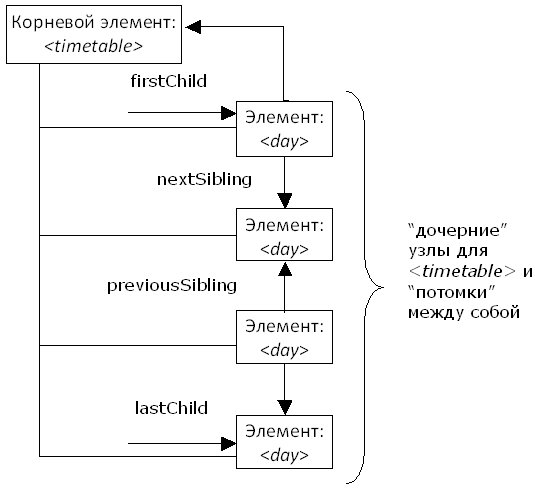
В XML DOM отношения между узлами определены в виде следующих свойств узлов:
Характер отношений между узлами представлен на следующем рисунке:
Игнорирование пустых текстовых узлов
Firefox и некоторые другие браузеры воспринимают неотображаемые символы как текстовые узлы (в отличие от Internet Explorer ). Такая ситуация приводит к проблемам при использовании свойств firstChild, lastChild, nextSibling, previousSibling. Для того, чтобы игнорировать такие пустые текстовые узлы можно использовать следующий прием:
function get_nextSibling(n)
{
y = n.nextSibling;
while (y.nodeType!=1)
{
y = y.nextSibling;
}
return y;
}Поскольку узлы элементов имеют тип 1, то в том случае, когда узел-потомок не является узлом элемента, будет происходить перемещение к следующему узлу до тех пор, пока не будет найден узел элемента.
Изменение значения атрибута
Узлы атрибутов могут принимать текстовые значения. Изменение этого значения реализуется либо через метод setAttribute(), либо через свойство узла атрибута node Value
Метод setAttribute() изменяет значение существующего атрибута или создает новый атрибут.
Например:
xmlDoc = loadXMLDoc("timetable.xml");
x = xmlDoc.getElementsByTagName('lesson');
x[0].setAttribute("type","lab");Свойство nodeValue можно использовать для изменения значения атрибута узла:
xmlDoc = loadXMLDoc("timetable.xml");
x = xmlDoc.getElementsByTagName("lesson")[0];
y = x.getAttributeNode("type");
y.nodeValue = "lab";Удаление узла из дерева реализуется с помощью метода removeChild():
xmlDoc=loadXMLDoc("timetable.xml ");
y = xmlDoc.getElementsByTagName("lesson")[0];
xmlDoc.documentElement.removeChild(y);