Введение. Структура веб-технологий
Предметом данного курса являются технологии глобальной сети World Wide Web (сокращенно WWW или просто Web ). На русском языке распространенным вариантом является название "Веб".
В частности, в рамках курса будут рассмотрены такие вопросы как: базовые стандарты и протоколы сети Веб, языки разметки и программирования веб-страниц, инструменты разработки и управления веб-контента и приложений для Веб, средства интеграции веб-контента и приложений в Веб.
Сеть Веб представляет собой глобальное информационное пространство, основанное на физической инфраструктуре Интернета и протоколе передачи данных HTTP. Зачастую, говоря об Интернете, подразумевают именно сеть Веб.
Клиент-серверные технологии Веб
Базовым протоколом сети гипертекстовых ресурсов Веб является протокол HTTP. В его основу положено взаимодействие " клиент-сервер ", то есть предполагается, что:
- Потребитель- клиент инициировав соединение с поставщиком-сервером посылает ему запрос;
- Поставщик- сервер, получив запрос, производит необходимые действия и возвращает обратно клиенту ответ с результатом.
При этом возможны два способа организации работы компьютера-клиента:
- Тонкий клиент - это компьютер-клиент, который переносит все задачи по обработке информации на сервер. Примером тонкого клиента может служить компьютер с браузером, использующийся для работы с веб-приложениями.
- Толстый клиент, напротив, производит обработку информации независимо от сервера, использует последний в основном лишь для хранения данных.
Прежде чем перейти к конкретным клиент-серверным веб-технологиям, рассмотрим основные принципы и структуру базового протокола HTTP.
Протокол HTTP
HTTP ( HyperText Transfer Protocol - RFC 1945, RFC 2616 ) - протокол прикладного уровня для передачи гипертекста.
Центральным объектом в HTTP является ресурс, на который указывает URI в запросе клиента. Обычно такими ресурсами являются хранящиеся на сервере файлы. Особенностью протокола HTTP является возможность указать в запросе и ответе способ представления одного и того же ресурса по различным параметрам: формату, кодировке, языку и т. д. Именно благодаря возможности указания способа кодирования сообщения клиент и сервер могут обмениваться двоичными данными, хотя изначально данный протокол предназначен для передачи символьной информации. На первый взгляд это может показаться излишней тратой ресурсов. Действительно, данные в символьном виде занимают больше памяти, сообщения создают дополнительную нагрузку на каналы связи, однако подобный формат имеет много преимуществ. Сообщения, передаваемые по сети, удобочитаемы, и, проанализировав полученные данные, системный администратор может легко найти ошибку и устранить ее. При необходимости роль одного из взаимодействующих приложений может выполнять человек, вручную вводя сообщения в требуемом формате.
В отличие от многих других протоколов, HTTP является протоколом без памяти. Это означает, что протокол не хранит информацию о предыдущих запросах клиентов и ответах сервера. Компоненты, использующие HTTP, могут самостоятельно осуществлять сохранение информации о состоянии, связанной с последними запросами и ответами. Например, клиентское веб-приложение, посылающее запросы, может отслеживать задержки ответов, а веб-сервер может хранить IP -адреса и заголовки запросов последних клиентов.
Все программное обеспечение для работы с протоколом HTTP разделяется на три основные категории:
- Серверы - поставщики услуг хранения и обработки информации (обработка запросов).
- Клиенты - конечные потребители услуг сервера (отправка запросов).
- Прокси-серверы для поддержки работы транспортных служб.
"Классическая" схема HTTP-сеанса выглядит так.
- Установление TCP -соединения.
- Запрос клиента.
- Ответ сервера.
- Разрыв TCP -соединения.
Таким образом, клиент посылает серверу запрос, получает от него ответ, после чего взаимодействие прекращается. Обычно запрос клиента представляет собой требование передать HTML-документ или какой-нибудь другой ресурс, а ответ сервера содержит код этого ресурса.
В состав HTTP-запроса, передаваемого клиентом серверу, входят следующие компоненты.
- Строка состояния (иногда для ее обозначения используют также термины строка-статус, или строка запроса).
- Поля заголовка.
- Пустая строка.
- Тело запроса.
Строку состояния вместе с полями заголовка иногда называют также заголовком запроса.
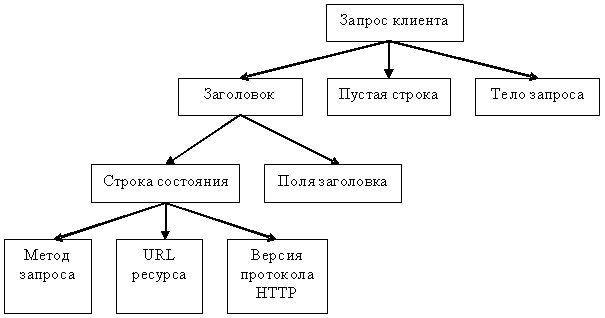
Строка состояния имеет следующий формат:
метод_запроса URL_pecypca версия_протокола_НТТР
Рассмотрим компоненты строки состояния, при этом особое внимание уделим методам запроса.
Метод, указанный в строке состояния, определяет способ воздействия на ресурс, URL которого задан в той же строке. Метод может принимать значения GET, POST, HEAD, PUT, DELETE и т.д. Несмотря на обилие методов, для веб-программиста по-настоящему важны лишь два из них: GET и POST.
- GET. Согласно формальному определению, метод GET предназначается для получения ресурса с указанным URL. Получив запрос GET, сервер должен прочитать указанный ресурс и включить код ресурса в состав ответа клиенту. Ресурс, URL которого передается в составе запроса, не обязательно должен представлять собой HTML-страницу, файл с изображением или другие данные. URL ресурса может указывать на исполняемый код программы, который, при соблюдении определенных условий, должен быть запущен на сервере. В этом случае клиенту возвращается не код программы, а данные, сгенерированные в процессе ее выполнения. Несмотря на то что, по определению, метод GET предназначен для получения информации, он может применяться и в других целях. Метод GET вполне подходит для передачи небольших фрагментов данных на сервер.
- POST. Согласно тому же формальному определению, основное назначение метода POST - передача данных на сервер. Однако, подобно методу GET, метод POST может применяться по-разному и нередко используется для получения информации с сервера. Как и в случае с методом GET, URL, заданный в строке состояния, указывает на конкретный ресурс. Метод POST также может использоваться для запуска процесса.
- Методы HEAD и PUT являются модификациями методов GET и POST.
Версия протокола http, как правило, задается в следующем формате:
HTTP/версия.модификация
Поля заголовка, следующие за строкой состояния, позволяют уточнять запрос, т.е. передавать серверу дополнительную информацию. Поле заголовка имеет следующий формат:
Имя_поля: Значение
Назначение поля определяется его именем, которое отделяется от значения двоеточием.
Имена некоторых наиболее часто встречающихся в запросе клиента полей заголовка и их назначение приведены в таблице 1.1.
Во многих случаях при работе в Веб тело запроса отсутствует. При запуске CGI -сценариев данные, передаваемые для них в запросе, могут размещаться в теле запроса.
Ниже представлен пример HTML-запроса, сгенерированного браузером
GET http://oak.oakland.edu/ HTTP/1.0 Connection: Keep-Alive User-Agent: Mozilla/4.04 [en] (Win95; I) Host: oak.oakland.edu Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/png, */* Accept-Language: en Accept-Charset: iso-8859-l,*,utf-8
Получив от клиента запрос, сервер должен ответить ему. Знание структуры ответа сервера необходимо разработчику веб-приложений, так как программы, которые выполняются на сервере, должны самостоятельно формировать ответ клиенту.
Подобно запросу клиента, ответ сервера также состоит из четырех перечисленных ниже компонентов.
- Строка состояния.
- Поля заголовка.
- Пустая строка.
- Тело ответа.
Ответ сервера клиенту начинается со строки состояния, которая имеет следующий формат:
Версия_протокола Код_ответа Пояснительное_сообщение
- Версия_протокола задается в том же формате, что и в запросе клиента, и имеет тот же смысл.
- Код_ответа - это трехзначное десятичное число, представляющее в закодированном виде результат обслуживания запроса сервером.
- Пояснительное_сообщение дублирует код ответа в символьном виде. Это строка символов, которая не обрабатывается клиентом. Она предназначена для системного администратора или оператора, занимающегося обслуживанием системы, и является расшифровкой кода ответа.
Из трех цифр, составляющих код ответа, первая (старшая) определяет класс ответа, остальные две представляют собой номер ответа внутри класса. Так, например, если запрос был обработан успешно, клиент получает следующее сообщение:
HТТР/1.0 200 ОК
Как видно, за версией протокола HTTP 1.0 следует код 200. В этом коде символ 2 означает успешную обработку запроса клиента, а остальные две цифры (00) - номер данного сообщения.
В используемых в настоящее время реализациях протокола HTTP первая цифра не может быть больше 5 и определяет следующие классы ответов.
- 1 - специальный класс сообщений, называемых информационными. Код ответа, начинающийся с 1, означает, что сервер продолжает обработку запроса. При обмене данными между HTTP-клиентом и HTTP-сервером сообщения этого класса используются достаточно редко.
- 2 - успешная обработка запроса клиента.
- 3 - перенаправление запроса. Чтобы запрос был обслужен, необходимо предпринять дополнительные действия.
- 4 - ошибка клиента. Как правило, код ответа, начинающийся с цифры 4, возвращается в том случае, если в запросе клиента встретилась синтаксическая ошибка.
- 5 - ошибка сервера. По тем или иным причинам сервер не в состоянии выполнить запрос.
Примеры кодов ответов, которые клиент может получить от сервера, и поясняющие сообщения приведены в таблице 1.2.
В ответе используется такая же структура полей заголовка, как и в запросе клиента. Поля заголовка предназначены для того, чтобы уточнить ответ сервера клиенту. Описание некоторых из полей, которые можно встретить в заголовке ответа сервера, приведено в таблице 1.3.
| Имя поля | Описание содержимого |
|---|---|
| Server | Имя и номер версии сервера |
| Age | Время в секундах, прошедшее с момента создания ресурса |
| Allow | Список методов, допустимых для данного ресурса |
| Content-Language | Языки, которые должен поддерживать клиент для того, чтобы корректно отобразить передаваемый ресурс |
| Content-Type | MIME -тип данных, содержащихся в теле ответа сервера |
| Content-Length | Число символов, содержащихся в теле ответа сервера |
| Last-Modified | Дата и время последнего изменения ресурса |
| Date | Дата и время, определяющие момент генерации ответа |
| Expires | Дата и время, определяющие момент, после которого информация, переданная клиенту, считается устаревшей |
| Location | В этом поле указывается реальное расположение ресурса. Оно используется для перенаправления запроса |
| Cache-Control | Директивы управления кэшированием. Например, no-cache означает, что данные не должны кэшироваться |
В теле ответа содержится код ресурса, передаваемого клиенту в ответ на запрос. Это не обязательно должен быть HTML-текст веб-страницы. В составе ответа могут передаваться изображение, аудио-файл, фрагмент видеоинформации, а также любой другой тип данных, поддерживаемых клиентом. О том, как следует обрабатывать полученный ресурс, клиенту сообщает содержимое поля заголовка Content-type.
Ниже представлен пример ответа сервера на запрос, приведенный в предыдущем разделе. В теле ответа содержится исходный текст HTML-документа.
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.1
X-Powered-By: ASP.NET
Date: Mon, 20 OCT 2008 11:25:56 GMT
Content-Type: text/html
Accept-Ranges: bytes
Last-Modified: Sat, 18 Oct 2008 15:05:44 GMT
ETag: "b66a667f948c92:8a5"
Content-Length: 426
<html>
<body>
<form action='http://localhost/Scripts/test.pl'>
<p>Operand1: <input type='text' name='A'></p>
<p>Operand2: <input type='text' name='B'></p>
<p>Operation:<br>
<select name='op'>
<option value='+'>+</option>
<option value='-'>-</option>
<option value='*'>*</option>
<option value='/'>/</option>
<select></p>
<input type='submit' value='Calculate!'>
</from>
</body>
</html>Поля заголовка и тело сообщения могут отсутствовать, но строка состояния является обязательным элементом, так как указывает на тип запроса/ответа.
Поле с именем Content-type может встречаться как в запросе клиента, так и в ответе сервера. В качестве значения этого поля указывается MIME -тип содержимого запроса или ответа. MIME -тип также передается в поле заголовка Accept, присутствующего в запросе.
Спецификация MIME ( Multipurpose Internet Mail Extension - многоцелевое почтовое расширение Internet ) первоначально была разработана для того, чтобы обеспечить передачу различных форматов данных в составе электронных писем. Однако применение MIME не исчерпывается электронной почтой. Средства MIME успешно используются в WWW и, по сути, стали неотъемлемой частью этой системы.
Стандарт MIME разработан как расширяемая спецификация, в которой подразумевается, что число типов данных будет расти по мере развития форм представления данных. Каждый новый тип в обязательном порядке должен быть зарегистрирован в IANA ( Internet Assigned Numbers Authority ).
До появления MIME компьютеры, взаимодействующие по протоколу HTTP, обменивались исключительно текстовой информацией. Для передачи изображений, как и для передачи любых других двоичных файлов, приходилось пользоваться протоколом FTP.
В соответствии со спецификацией MIME, для описания формата данных используются тип и подтип. Тип определяет, к какому классу относится формат содержимого HTTP-запроса или HTTP-ответа. Подтип уточняет формат. Тип и подтип отделяются друг от друга косой чертой:
тип/подтип
Поскольку в подавляющем большинстве случаев в ответ на запрос клиента сервер возвращает исходный текст HTML-документа, то в поле Content-type ответа обычно содержится значение text/html. Здесь идентификатор text описывает тип, сообщая, что клиенту передается символьная информация, а идентификатор html описывает подтип, т.е. указывает на то, что последовательность символов, содержащаяся в теле ответа, представляет собой описание документа на языке HTML.
Перечень типов и подтипов MIME достаточно велик. В таблице 1.4 приведены примеры MIME -типов, наиболее часто встречающиеся в заголовках HTML-запросов и ответов.
Для однозначной идентификации ресурсов в сети Веб используются уникальные идентификаторы URL.
Единообразный идентификатор ресурса URI (Uniform Resource Identifier) представляет собой короткую последовательность символов, идентифицирующую абстрактный или физический ресурс. URI не указывает на то, как получить ресурс, а только идентифицирует его. Это дает возможность описывать с помощью RDF (Resource Description Framework) ресурсы, которые не могут быть получены через Интернет (имена, названия и т.п.). Самые известные примеры URI - это URL и URN.
- URL (Uniform Resource Locator) - это URI, который, помимо идентификации ресурса, предоставляет еще и информацию о местонахождении этого ресурса.
- URN (Uniform Resource Name) - это URI, который идентифицирует ресурс в определенном пространстве имен, но, в отличие от URL, URN не указывает на местонахождение этого ресурса.
URL имеет следующую структуру:
<схема>://<логин>:<пароль>@<хост>:<порт>/<URL?путь>
где:
- схема - схема обращения к ресурсу (обычно сетевой протокол);
- логин - имя пользователя, используемое для доступа к ресурсу;
- пароль - пароль, ассоциированный с указанным именем пользователя;
- хост - полностью прописанное доменное имя хоста в системе DNS или IP -адрес хоста;
- порт - порт хоста для подключения;
- URL-путь - уточняющая информация о месте нахождения ресурса.