Семантика баз данных
12.2 Эмулирование моделей данных
Давно известно, что в реальных информационных системах трудно обойтись единственной моделью данных. В однослойной конструкции одна из моделей выбирается в качестве базисной. Именно она определяет структуры хранения данных. Остальные модели эмулируются, то есть реализуются через базисную модель. Мы уже представляли в реляционной модели древесные данные.
Понятно, что эмулированная структура может обладать многими недостатками. Однако известная идея о том, что все необходимые модели должны быть нативными, то есть реализованными независимо в рамках одной СУБД, вряд ли когда-нибудь будет поддержана вендорами. Посмотрим, что может дать эмуляция моделей в базисной табличной и иерархической моделях.
Мы попробуем бороться с почти очевидными недостатками, такими как неоптимальность хранения, сложность манипулирования данными и невысокое быстродействие. Будут отмечены возможные области применения и особенности эмулированных систем, которых нет в базисной модели данных. Это возможности работы с постоянно изменяемыми структурами данных, возможность реализации полуструктурированных, табличных, объектных, объектно-реляционных моделей, различных сетей и деревьев, возможность работы с базами, содержащими очень большое число таблиц, содержащих немногоданных.
12.2.1 Модели, эмулированные в табличной модели данных. Универсальная модель данных
Структуры данных во время работы базы изменяются довольно редко. Однако существует два типа систем, в которых схема базы перестраивается постоянно:
- базы, в которых схема изменяется во время работы приложения или не может быть определена заранее во всех деталях;
- средства разработки корпоративных информационных систем, обладающие возможностью полноценного моделирования действующих прототипов базы и обеспечивающие возможность версионинга за счет фиксации версий и возможности отката команд DDL виртуальной схемы, которые в УМД заменяются наборами команд DML в реальных таблицах схемы УМД.
Подобные системы можно реализовать с помощью виртуальных баз данных со следующими свойствами:
- Виртуальные структуры данных, включая словарь и сами данные, хранятся в фиксированном наборе структур вмещающей базы и могут изменяться в процессе работы. Допускаются откаты команд языка определения данных (DDL), чего нет в обычных базах данных.
- Словарь вмещающей базы не содержит данных словаря виртуальной базы.
- Возможен экспорт и импорт из виртуальной базы во вмещающую базу или базу с другой моделью данных.
Впрочем, последнее свойство не обязательное.
Базы с описанными свойствами принято называть универсальными (УБД), говорят и об универсальной модели данных (УМД).
Реализация УМД может быть выполнена в трех основных вариантах:
- с использованием инвариантных структур в обычной базе, например, реляционного типа;
- на основе XML-баз или XML-опций баз данных во втором слое базы;
- на основе иерархических моделей.
Выбор предпочтительного варианта зависит от того, насколько удается использовать возможность включающей СУБД. Например, для реализации УМД на основе XML необходимо, чтобы данные хранились в уже разобранном виде, а не цельным текстом. Кроме того, необходима поддержка языков для работы с XML: XPath, XQuery и т.п. Желательно, чтобы СУБД предоставляла средства для вставки и изменения в середине документа. Не все современные СУБД располагают перечисленными возможностями.
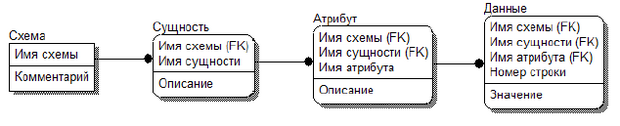
УМД на основе табличной модели состоит из фиксированного набора таблиц. Она может хранить в себе и данные, и метаданные нескольких виртуальных схем базы. В простейшем варианте УМД представляет собой набор из четырех таблиц изображенный на рисунке 12.1
Если некоторые сущности и/или связи в схеме базы могут изменяться в процессе работы, то представление ее в обычной СУБД становится невозможным. Необходимо перестроить базу, а затем продолжить работу в новой схеме.
Известные приемы борьбы с этим явлением сводятся к изменениям схемы, при которых часть метаданных переносится в саму базу и потому команды DDL могут заменятся несколькими командами DML. Естественно, при этом необходимо интерпретировать эти метаданные нужным образом.
Оказывается, изменяющуюся реляционную схему данных и сами данные можно разместить в так называемой универсальной модели данных (УМД), состоящей из фиксированного набора таблиц. Этот набор таблиц один и тот же для любой представляемой виртуальной схемы. Отличие УМД в том, что она хранит в себе и данные и метаданные.
В простейшем варианте, УМД представляет собой набор из четырех таблиц изображенный на рисунке 12.1.
Все атрибуты в этой схеме предполагаются строчными. В реализациях, конечно, необходимо указывать типы атрибутов и обрабатывать содержащиеся в них данные в соответствии с типами.
Для включения сущности в виртуальную схему необходимо добавить одну строку в таблицу "Сущность", а для добавления атрибута добавить одну строку в таблицу "Атрибут". Количество строк в таблице "Данные", определяющих один экземпляр сущности равно числу атрибутов у этой сущности.
Например, для записи в УМД таблицы dept(deptno, dname, loc) из схемы scott, содержащей одну первую строку (10, 'ACCOUNTING', 'NEW-YORK') необходимо:
- в таблицу "Схема" записать одну строку ('SCOTT', ");
- в таблицу "Сущность" записать одну строку ('SCOTT', 'DEPT', ");
- в таблицу "Атрибут" записать три строки ('SCOTT', 'DEPT', 'DEPTNO', "), ('SCOTT', 'DEPT', 'DNAME', "), ('SCOTT', 'DEPT', 'LOC', ");
- в таблицу "Данные" записать по три строки для каждой строки виртуальной таблицы, то есть ('SCOTT', 'DEPT', 'DEPTNO', '1', '10'), ('SCOTT', 'DEPT', 'DNAME', '1', 'ACCOUNTING'), ('SCOTT', 'DEPT', 'LOC', '1', 'NEW-YORK').
Для упрощения изложения здесь предполагались пустые комментарии к схеме и отсутствие описаний таблиц и столбцов. Понятно, что, например, удаление таблицы dept с ее содержимым не требует выполнения инструкции DROP TABLE. Достаточно удалить перечисленные выше семь строк, содержащих метаданные таблицы и ее содержимое.
Всегда инструкция DDL виртуальной базы заменяется транзакцией с несколькими инструкциями DML в реально существующих таблицах УМД.
Одной команде манипулирования виртуальными данными всегда соответствует транзакция с набором из нескольких инструкций DML для реальных таблиц УМД.
Обратите внимание на то, что предложенная схема денормализована и сильно избыточна. Можно было бы создать суррогатные ключи и не повторять атрибуты (четыре раза атрибут "Имя схемы", три раза атрибут "Имя сущности" и два раза атрибут "Имя атрибута"). Из-за повторов атрибутов принятый подход несколько усложняет выполнение инструкций DDL для виртуальной схемы. Однако, при выполнении инструкций DML и запросов к виртуальным таблицам следует обращаться только к таблице "Данные", что сокращает количество соединений таблиц и существенно повышает быстродействие, которого в УМД сильно не хватает.
История УМД началась в 1980-х годах. По-видимому, впервые они появились в работах по медицинским базам данных. Было замечено, что из-за многообразия медицинских данных их необходимо размещать в большом количестве таблиц, причем состав опрашиваемых таблиц для каждого больного может быть свой, а при появлении новых видов анализов количество этих таблиц может увеличиваться. В УМД можно просмотреть все возможные виды данных по одному пациенту даже если число таблиц заранее не известно. Конечно, ускоряются только запросы, ориентированные на получение полной информации по пациенту.
Из-за недостаточной известности работ по УМД это направление несколько раз переоткрывалось повторно в 2000-х годах. Наиболее известны УМД, отображающие реляционную и объектную виртуальные модели на реляционную модель.
Иногда УМД предлагается как замена всей базы со словарем, а не только изменяющихся частей базы. По-видимому, этот подход мало перспективен, так как, решая основную задачу получения инвариантной структуры, в которой хранятся данные, УМД резко увеличивает сложность запросов, значительно (в разы) уменьшает скорость их исполнения и порождает целый ряд проблем, связанных с представлением ограничений целостности, индексов и других объектов.
Основные недостатки УМД:
- низкое быстродействие;
- сложные инструкции;
- отсутствие во многих реализациях ограничений целостности (декларативных и процедурных), индексов, пользователей, ролей и представлений.
Падение быстродействия и усложнение инструкций происходит в первую очередь из-за того, что для извлечения одной строки виртуальной таблицы, хранящейся в УМД, необходимо выполнить N — 1 соединений таблицы "Данные" с собой, где N — число столбцов виртуальной таблицы.
Недостатки УМД частично преодолены в программе представленной на сайте книги.
Проблема сложности запросов решается обычно созданием транслятора с языка виртуальной базы в язык работы с УМД. Пользователь работает только с виртуальной базой, может быть ничего не зная об УМД. Пример QBE запроса к виртуальным таблицам приведен в таблице 12.1.
В традиционной базе реляционного типа этот запрос соответствовал бы следующему запросу на SQL:
SELECT emp.ename, emp.job, emp.sal, emp.deptno, dept.dname FROM emp,dept WHERE emp.deptno=dept.deptno AND emp.sal > 10000;
| emp | empno | ename | job | mgr | hiredate | sal | comm | deptno |
|---|---|---|---|---|---|---|---|---|
| P. | P. | P.>10000 | P._D_ | |||||
| dept | deptno | dname | loc | |||||
| _D_ | P. | |||||||
Существует два способа трансляции запроса к виртуальной базе. Оба они реализованы в созданной системе. Первый — наиболее распространенный метод работы с УМД — использование соединений JOIN в запросе к реальным таблицам УМД. Предыдущему запросу к виртуальной базе соответствует следующий сложный запрос к реальной базе, в которой таблица "Данные" для краткости переименована в "tc":
SELECT t1.val,t2.val,t3.val,t4.val,t5.val FROM tc tl, tc t2, tc t3, tc t4, tc t5, tc t6, tc t7, tc t8 WHERE t1.column_name='ENAME' AND t1.table_name='EMP' AND t1.scheme_name='TEST' AND t2.column_name='JOB' AND t2.table_name='EMP' AND t2.scheme_name='TEST' AND t3.column_name='SAL' AND t3.table_name='EMP' AND t3.scheme_name='TEST' AND t4.column_name='DEPTNO' AND t4.table_name='EMP' AND t4.scheme_name='TEST' AND t5.column_name='DNAME' AND t5.table_name='DEPT' AND t5.scheme_name='TEST' AND t6.column_name='DEPTNO' AND t6.table_name='EMP' AND t6.scheme_name='TEST' AND t7.column_name='DEPTNO' AND t7.table_name='DEPT' AND t7.scheme_name='TEST' AND t8.column_name='SAL' AND t8.table_name='EMP' AND t8.scheme_name='TEST' AND t1.string_number=t2.string_number AND t1.string_number=t3.string_number AND t1.string_number=t4.string_number AND t1.string_number=t6.string_number AND t1.string_number=t8.string_number AND t2.string_number=t3.string_number AND t2.string_number=t4.string_number AND t2.string_number=t6.string_number AND t2.string_number=t8.string_number AND t3.string_number=t4.string_number AND t3.string_number=t6.string_number AND t3.string_number=t8.string_number AND t4.string_number=t6.string_number AND t4.string_number=t8.string_number AND t5.string_number=t7.string_number AND t6.string_number=t8.string_number AND (t6.val=t7.val AND to_number(t8.val)>10000);
Конечно, такого рода запросы выполняются гораздо медленнее традиционных. Заметим, что писать вручную запросы такого вида было бы крайне неудобно, но еще труднее выполнять их проверку.
Второй способ, более быстрый, основан на использовании метода Т. Кайта для транспонирования строк в столбцы с помощью функции DECODE (см. раздел 8.5.2).
УМД используемые в инструментальных средствах для разработки информационных систем должны иметь как возможность трансформации виртуальной схемы с данными в обычную базу данных, так и обратного преобразования.
Рассмотренный выше запрос к виртуальным таблицам emp и dept, после трансляции в запрос к реальным таблицам УМД будет иметь следующий вид:
SELECT t1.ename,t1.job,t1.sal,t1.deptno,t2.dname FROM (SELECT string_number, min(decode(column_name,'ENAME',val)) ename, min(decode(column_name,'JOB',val)) job, min(decode(column_name,'SAL',val)) sal, min(decode(column_name,'DEPTNO',val)) deptno FROM tc WHERE table_name='EMP' AND scheme_name='TEST' GROUP BY string_number) t1, (SELECT string_number, min(decode(column_name,'DNAME',val)) dname, min(decode(column_name,'DEPTNO',val)) deptno FROM tc WHERE table_name='DEPT' AND scheme_name='TEST' GROUP BY string_number) t2 WHERE t1.deptno=t2.deptno AND t1.sal>10000;
Такой запрос в СУБД Oracle выполняется гораздо быстрее, чем составленный по первому методу. Кроме того, можно повысить быстродействие путем добавления индексов на таблицу данных. Конечно, это частичное решение проблемы быстродействия, и рекомендация по использованию УБД остается прежней: только инструментальные средства и часть базы с постоянно меняющимися структурами данных.