Семантика баз данных
12.5 Встроенные дедуктивные системы
Настало время вспомнить, что язык SQL основан на исчислении на кортежах и потому должен обладать дедуктивными возможностями, которые нами до сих пор не использовались.
В самом деле, что нам мешает рассуждать с помощью SQL? Как ни странно, ничего и не мешает. Просто раньше мы об этом не задумывались, так как слишком увлеклись выборками данных.
12.5.1 Продукции и их реализации в SQL
Продукции
Вспомним, что таблицы или сущности описываются предикатами. Поэтому таблица может пониматься как набор фактов, на которых определяющий ее предикат принимает значение "истинно".
Еще нам понадобится понятие продукции — средства описания продукционных знаний. Простейшая продукция это импликация

В ней условие (антецедент) А определяет некоторую ситуацию предметной области, некоторый факт или набор фактов. Заключение (консеквент) К это предикат, истинный, если подходящий факт в условии найден.
Следуя Поспелову Д.А. , будем использовать продукции общего вида:
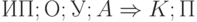
где  — идентификатор продукции,
— идентификатор продукции,  —область применимости,
—область применимости, 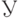 — условие применимости,
— условие применимости,  —последействие. Сама импликация называется ядром продукции.
—последействие. Сама импликация называется ядром продукции.
Выделение областей и условий применимости может быть полезными для уменьшения количества перебираемых в процессе вывода продукций. Конечно, воспользоваться этими параметрами в процессе вывода можно, если, по крайней мере, некоторые продукции оставляют в памяти какую-то информацию, влияющую на выбор продукции. Например, задают название области, к которой следует перейти, или меняют параметры используемые условием применимости.
Любую базу данных, в том числе табличного типа, можно воспринимать как известное количество наборов фактов соответствующих сущностям. Для создания продукционной системы над базой данных остается записать набор продукций, управляющих выводом, и научиться его использовать.
Запрос, реализующий ядро продукции
Ядра продукции могут быть детерминированными (продукция обязательно исполняется) и недетерминированными (продукция может быть исполнена). Детерминированные продукции могут быть однозначными (с единственным следствием) и альтернативными (с возможностью выбора следствия).
Рассмотрим простейший пример. Пусть задан единственный набор фактов в виде таблицы 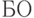 со схемой
со схемой  , описывающей отношение "быть отцом", (таблица 12.5) и существует единственная продукция, опред
еляющая отношение "быть дедом" как "отец отца есть дед":
, описывающей отношение "быть отцом", (таблица 12.5) и существует единственная продукция, опред
еляющая отношение "быть дедом" как "отец отца есть дед":
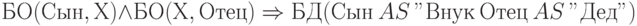
В ней в соответствии с традициями языка Пролог имена переменных начинаются с заглавной буквы.
Для тех, кто не изучал логического программирования и продукционных систем, опишем работу продукции. Подбираем два факта описываемых предикатом так, чтобы значение атрибута "Отец" из первого факта было равно значению атрибута "Сын" из второго факта. О необходимости такого действия говорит общая переменная X в первом и втором предикатах , стоящая, соответственно, на втором и первом местах. Следствием будет факт, описываемый предикатом БД (то есть, быть дедом), причем сын из первого предиката теперь играет роль внука, а отец из второго оказывается дедом. Для этого в консеквенте следует выполнить переименования, заменив "Сын" на "Внук", а "Отец" на "Дед".
На языке SQL рассмотренной продукции соответствует запрос, порождающий временное отношение "быть дедом":
SELECT Б01.Сын AS "Внук", Б02.0тец AS "Дед" FROM БО Б01, БО Б02 WHERE Б01.0тец = Б02.Сын
Если не нужны все деды, то дополним фразу WHERE условием, присоединенным через конъюнкцию и позволяющим, например, найти деда конкретного человека: Б01.0тец = Б02.Сын AND Б01.Сын = 'ИВАНОВ'.
Условие продукции может представлять собой конъюнктивную, а может быть и дизъюнктивную, форму. Очевидно, что если две или более частей условия соединены связкой "ИЛИ", то такую продукцию можно разбить на две или более продукций. Например, продукция
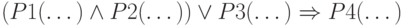
эквивалентна совокупности продукций:

Прямая скобка, как в школьной математике обозначает совокупность (а не систему) продукций. С ними следует работать независимо.
В итоге получаем, что можно ограничиться продукциями, у которых условие представляется конъюнкцией некоторых предикатов.
Заметим, что в первом примере все аргументы посылок использовались либо для соединения предикатов (у нас переменная X), либо передавались в результат (у нас "сын" в первом предикате и "отец" во втором). В общем случае могут существовать еще, так называемые, безразличные имена, не представленные в результате и не используемые в соединении. Будем обозначать их традиционным для логического программирования знаком подчеркивания "_".
Например, если таблица БО станет такой как в таблице 12.6, то продукция перепишется так:
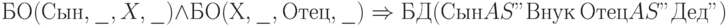
а соответствующий запрос SQL не изменится.
Отметим, что в реализации ядер продукции семантика исходных данных базы, как и следовало ожидать, не менялась, но семантика задачи внесла свою лепту в интерпретацию результата. В частности, потребовались переименования столбцов и подбор термина для описания результата. В действительности выполнение запросов всегда внедряет семантику задачи в семантику результата. Просто зачастую этот вклад настолько тривиален, что семантический аспект не стоит выделять. Например, "проигнорировать сведения из столбцов А,В,С" или "учитывать только строки, удовлетворяющие условию X".
Система продукций
Если результат продукции представляет набор фактов, которые будут использоваться другими продукциями, то последействие должно создать новый предикат, может быть временный. В SQL это обычно создание временной таблицы с результатом, полученным в запросе, или добавление в уже существующую таблицу строк с пометками "временная" или, может быть, "получено продукцией N...", "вывод М...".
Если данные заносятся в существующие таблицы, необходим механизм их очистки по завершении вывода.
Отметим, что уже здесь проявляется конфликт между процедурностью продукций общего вида и декларативностью SQL. Именно поэтому в схеме продукции мы используем последействие, расшифровываемое в процедурном смысле.
Для того, чтобы создать продукционную систему в рамках SQL-базы данных осталось научиться хранить и исполнять в ней продукции.
Таблица, хранящая произвольную систему продукций, может иметь спецификацию изображенную в таблице 12.7.
| ИП | О | У | А | К | Транзакция SQL | П |
Все семь столбцов имеют разные сорта, могут иметь сложную структуру и снабжаться системой смыслов обеспечивающей их расшифровку. Продукции могут быть заранее транслированы в транзакции SQL, которые при необходимости будут исполнены.
Прямой вывод в системе продукций это движение от посылок к заключениям. Пусть имеется несколько простейших продукций (например, 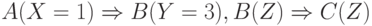 ) и имеется некоторый исходный факт "Х=1 в таблице А". Машина вывода будет просматривать продукции в порядке записи. В первой продукции условие
) и имеется некоторый исходный факт "Х=1 в таблице А". Машина вывода будет просматривать продукции в порядке записи. В первой продукции условие 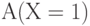 согласуется с исходным фактом. Значит истинно заключение
согласуется с исходным фактом. Значит истинно заключение 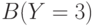 . Его используем как очередной текущий факт. Проверяя продукции, начиная с первой, видим, что предикат В имеется в условии второй продукции.
. Его используем как очередной текущий факт. Проверяя продукции, начиная с первой, видим, что предикат В имеется в условии второй продукции. 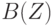 согласуется с при
согласуется с при 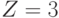 . Поэтому в предикате
. Поэтому в предикате 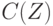 переменная .
переменная .
Обратный вывод предполагает движение в обратном направлении от цели (заключения) к условиям. Он используется в языке Пролог.
Такие важнейшие для продукционных систем знаний вопросы, как устранение противоречий и управление фронтом одиночных продукций мы не рассматриваем потому, что собираемся сосредоточиться на таблицах принятия решений. Это еще один подход к построению продукционных систем.
12.5.2 Таблицы принятия решений
Известно, что в продукционных системах с большим числом продукций (порядка 1000) очень трудно обнаружить противоречия, избавиться от избыточных продукций, которые никогда не работают, добиться правильного порядка исполнения продукций. Таблицы принятия решений, или сокращенно, таблицы решений облегчают структурирование больших продукционных систем, уменьшают количество продукций, задействованных на каждом этапе вывода.
В представлении предназначенном для восприятия человеком, в таблице решений существуют четыре основные области — условия, действия, варианты выполнения условий и необходимость действия (таблица 12.8).
| Условия | Варианты выполнения условий |
| Действия | Необходимость действий |
Выделяют три типа таблиц:
- комплексные таблицы; содержит и метаданные, и данные таблицы;
- таблицы с ограниченными входами; входы принимают значения "да", "нет" и "безразлично"; проверка ведется по равенству;
- таблицы с расширенными входами; входы принимают интервалы и наборы интервалов значений.
Для того, чтобы быстро сориентироваться в сути вопроса рассмотрим простейший пример таблицы, заимствованной из Википедии (таблица 12.9).
| Свет в соседней комнате горит | Да | Нет | Нет |
| Свет у соседей горит | — | Да | Нет |
| Поменять лампочку | + | ||
| Проверить пробки | + | ||
| Позвонить электрику | + | + | |
| Позвонить диспетчеру | + |
Для работы с таблицей решений в табличной базе данных транспонируем представляющую матрицу, меняя столбцы и строки местами (таблица 12.10).
Получилась реляционная таблица с шестью столбцами и тремя строками.
Каждой строке этой таблицы соответствует продукция. Например, для первой строки:
Свет_в_соседней_комнате_горит(Да) 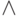 Свет_у_соседей_горит(Безразлично)
Свет_у_соседей_горит(Безразлично)  Поменять_лампочку(Да)
Поменять_лампочку(Да)
| Свет в соседней комнате горит | Свет у соседей горит | Поменять лампочку | Проверить пробки | Позвонить электрику | Позвонить диспетчеру |
|---|---|---|---|---|---|
| Да | — | + | |||
| Нет | Да | + | + | ||
| Нет | Нет | + | + |
Теперь для решения задачи прямого вывода достаточно написать простой запрос для поиска строки, соответствующей заданным условиям. Обратный доступ реализуется столь же простым запросом, выбирающим строки в зависимости от заданных действий.
Что касается семантики данных в таблицах решений, то тут возникает целый ряд проблем. Прежде всего, можно предположить, что в обычных базах данных проектировщики определяют спецификации данных гораздо точнее, чем это делают специалисты предметных областей в таблицах решений. Появляется необходимость отслеживать четкость, совместимость условий, возможность их пересечений и вложений. Семантика действий, представляющих, вообще говоря, наименования сценариев, требует не менее пристального внимания и не совсем обычна для баз данных.
Но мы не будем заниматься, ни оптимизацией структур систем принятия решений, ни оптимизацией самих таблиц, предоставив любознательному читателю самому во всем разобраться.
На сайте книги представлен реализованный вариант интеллектуального расширения СУБД Cache, полученного за счет подключения инструментального средства для создания и эксплуатации систем таблиц решений. Для хранения произвольных наборов таких таблиц в нем использован упрощенный вариант универсальной модели данных. Таким образом, и система искусственного интеллекта у вас теперь имеется, и, надеюсь, работу ее вы почти поняли.
12.6 Замечание об использованных моделях
Давайте, не вдаваясь в подробности, взглянем на модели, которые были использованы в книге.
Нетрудно заметить, что в литературе по базам данных давно под словом "модель" понимается некоторое семейство, а не четко определенная математическая конструкция. В самом деле, не считать же версию SQL с функцией DUMP() каким-то другим языком.
Мы достаточно подробно для вводного курса изучили несколько используемых в практике или в теоретических построениях моделей данных. Это иерархическая модель в Cache, реляционная алгебра, исчисления на кортежах и доменах, модель "сущность-связь", то, что мы называли табличной моделью данных, объектная и объектно-реляционная модели. Освоение всего этого зоопарка позволило получить базисный уровень знаний для работы с любыми данными.
Везде, где это представлялось возможным, рассматривались отображения моделей. Это позволило понять, что модели данных не живут каждая в отдельности, а связаны между собой и отражают свои аспекты моделируемого бизнеса. Было показано, что язык SQL вырастает из исчисления на кортежах, но в современном своем состоянии представляет нечто существенно большее, чем язык реляционной модели. Пример конструкции MODEL позволил понять, что изменение взгляда на данные позволяет строить в языке SQL множество принципиально различных моделей.
Объектная и объектно-реляционная модели данных это примеры существенного расширения моделей языков объектного программирования и SQL, соответственно. Изучение Cache дало уникальную возможность подробно просмотреть последствия реализации табличной и объектной моделей на общих структурах хранения.
Мы расширили понятие модели данных за счет допущения многосортно-сти атрибутов. Изучение активности в базах данных позволило существенно пополнить семантику данных, за счет введения смыслов, представляемых активными данными.
Наконец, возврат к истокам, то есть воспоминание о том, что SQL произошел от исчисления на кортежах, позволил встроить в СУБД дедуктивную модель данных продукционного типа или модель, основанную на таблицах принятия решений.
Все это позволяет существенно расширить семантику данных и создает предпосылки для более активного использования онтологий.
Что же касается самого понятия модели, то мы достаточно далеко ушли от моделей в математическом смысле. Это естественно, так как основная задача в области баз данных — обеспечить моделирование некоторого бизнеса, хранение и обработку его данных, а не получение конструкций, "правильных" с некоторой теоретической точки зрения.
В качестве полезного упражнения предлагается самостоятельно разобраться с направлением NoSQL, которое трактуется либо как No SQL, либо как Not Only SQL. При этом в обсуждении вопроса о сложности SQL используйте пару терминов "сложность" и "адекватность задаче" а в качестве побудительной причины к изменениям рассматривайте, естественно, возросшие потоки данных, снизившуюся сложность обработки данных в новых задачах и необходимость обеспечить горизонтальное масштабирование аппаратной платформы.