Хранение данных и доступ к ним
До сих пор мы изучали модели и языки, используемые в базах данных, и почти не интересовались ни тем, как устроено сложное инженерное сооружение под названием СУБД, ни тем, как оно работает. Разве что в "Введение в базы данных" обратили внимание на проблемы, возникающие из-за отсутствия быстрой первичной памяти, сохраняющей информацию при перерывах питания.
В этой лекции будут рассмотрены структуры хранения данных, их фрагментация, доступ к данным, их буферирование, индексы, представления таблиц в базах данных реляционного типа и оптимизация запросов SQL. Это позволит сделать общие выводы о некоторых особенностях архитектуры СУБД, получить первые представления о настройке приложения и немного приблизиться к пониманию того, что принято называть администрированием баз данных.
Из-за обширности изучаемого предмета и недостатка места, изложение будет отрывочным. Кроме того, мы вынужденно отойдем от одного из главных принципов, на которых построена книга. Возможности проверить все своими руками у вас, уважаемый читатель, почти не будет. Но, если учесть, что вводные курсы баз данных подобного материала обычно не содержат совсем, то, следует признать, — все не так уж плохо.
11.1 Структуры хранения
Известно, что эффективные структуры хранения должны иметь иерархическую организацию. Это позволяет выстроить дерево областей памяти, обладающее следующими свойствами:
- Области нижнего уровня образуют область верхнего уровня.
- Области каждого уровня имеют специфические особенности, предназначенные для решения проблем, с которыми не удается справиться на других уровнях.
- На каждом уровне области, как правило, имеют несколько параметров, позволяющих оптимизировать их работу в зависимости от назначения.
Заметим, что терминология, применяемая в различных базах данных, различается существенно. Наша терминосистема ближе всего к применяемой в СУБД Oracle.
11.1.1 Табличные пространства, сегменты, экстенты, блоки
В типичном случае (рисунок 11.1) база данных состоит из одного или нескольких табличных пространств. Каждое такое пространство строится на одном или нескольких файлах данных.
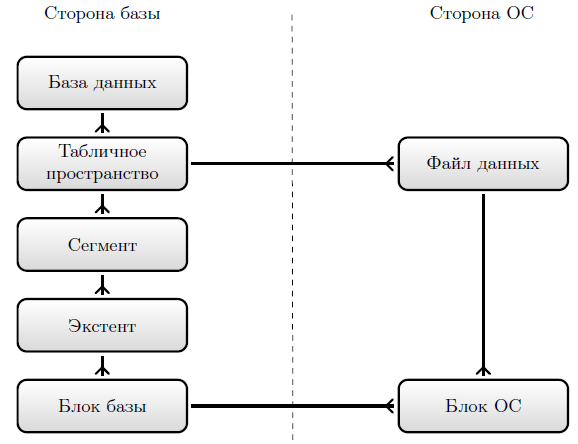
В одно табличное пространство стараются помещать объекты с одинаковым поведением. Например, для словаря базы можно выделить отдельное табличное пространство, обычно называемое системным. Пользовательские данные желательно помещать отдельно от словаря. Это уменьшит вероятность сбоя. Для индексов следует иметь свои табличные пространства. В некоторых СУБД можно отключать отдельные табличные пространства или делать их доступными только по чтению. Типичный пример — табличные пространства для хранения больших объемов очень редко меняющейся справочной информации. Для больших сортировок можно создавать временные табличные пространства, в которых объем данных может резко увеличиваться в размере и так же быстро уменьшаться.
Администратор должен выбрать состав, размеры табличных пространств и определить могут ли они расширяться, и какими порциями им будет предоставляться свободное пространство дисковой памяти.
Табличные пространства состоят из сегментов, содержащих хранимые объекты базы, например, таблицы, индексы, кольцевые буферы отката. Каждому такому объекту положено иметь свой сегмент, куда нет доступа данным других хранимых объектов.
Сегменты состоят из экстентов, представляющих наборы блоков данных базы, расположенных на диске непрерывно. Это ускоряет операции с бло ками данных, входящими в состав экстента. Можно, например, при работе с любым элементом данных, читать сразу весь экстент, в надежде, что эти данные скоро понадобятся. Нетрудно догадаться, что сегмент увеличивается или уменьшается на целое число экстентов.
Блок базы, в другой терминологии — страница, — это минимальная единица хранения, которой база данных обменивается с диском. Блок базы образуется из нескольких блоков операционной системы.
Можно задаться вопросом — а почему не использовать блоки операционной системы в качестве блоков данных базы? Дело в том, что современные операционные системы стараются оптимизировать под целый ряд программ, для которых достаточно небольших блоков. Так что добавление больших блоков базы размером до 64 Кбайт, оптимальных для баз данных, неизбежно.
Можно выделить два режима работы базы данных. В первом режиме OLTP (Online Transaction Processing) информационная система использует большой поток транзакций, работающих с небольшими объемами данных.
Обычно это ввод первичных данных, их сохранение и не слишком сложная обработка информации.
Режим OLAP (Online Analytical Processing) используется аналитиками для подготовки сложных отчетов, для анализа информации. Связан с небольшим количеством транзакций, перерабатывающих большие объемы данных.
Установлено, что для работы в режиме OLTP, когда исполняется много сравнительно коротких транзакций, предпочтительнее небольшие блоки размером в 4-12 Кбайт. В режиме OLAP, когда исполняется сравнительно небольшое число длящихся долго транзакций, предпочтительнее блоки больших размеров.
11.1.2 Блоки базы
Для того, чтобы представить, как можно управлять пространством внутри блока, рассмотрим упрощенный вариант блока СУБД Oracle. В нем выделяются заголовок и область для размещения данных. Для блоков большинства сегментов определены два параметра — PCTFREE и PCTUSED (рисунок 11.2), определяемые в процентах от объема блока без заголовка. Область заголовка может изменяться во время обращения и манипуляций с данными за счет того, что каждая транзакция, обратившаяся к блоку, записывает в его заголовок свой номер SCN и другую информацию.
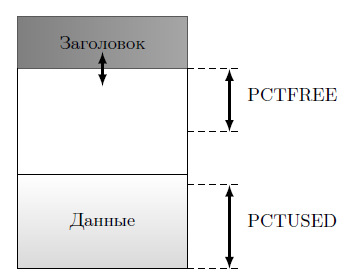
Параметр PCTFREE определяет тот объем незанятого пространства блока, который необходимо оставить для того, чтобы с увеличением длины записей при выполнении инструкций UPDATE они поместились в своем блоке, а не мигрировали в другие блоки. Естественно, возникает вопрос: а как вычислить это значение? Ответ, наверное, не совсем ожидаемый: никак! Просто администратор может экспериментально подобрать некоторое, хорошее для текущего режима работы базы, значение.
В сегменте, выделенном для хранения таблицы, блоки, у которых свободного места меньше, чем PCTFREE, для записи не пригодны. Очевидно, СУБД необходим список блоков, пригодных для записи. Желательно, чтобы этот список был не один, так как транзакции будут конкурировать за доступ к нему при обращении к данным. Конечно, записи во всех таких списках должны быть одинаковыми.
Теперь можно разобраться с назначением второго параметра — PCTUSED, задающего момент включения блока данных в список блоков, пригодных для записи в своем сегменте.
Пусть объем данных в блоке увеличивается от 0 до величины, превышающей PCTUSED, но свободное пространство при этом не меньше PCTFREE. Блок остается в списках блоков, пригодных для записи. Как только свободное пространство станет меньше PCTFREE, блок удалится из всех списков блоков, пригодных для записи. После этого, при увеличении свободного пространства блока до величины большей, чем PCTFREE, он будет оставаться вне списков. И только когда занятое место станет меньше чем PCTUSED, блок вернется в списки блоков пригодных для записи.
Если бы не было параметра PCTUSED, то освобождающиеся блоки очень часто преждевременно возвращались бы в списки блоков пригодных для записи и так же часто из них удалялись. Вот такой, или примерно такой, алгоритм должна реализовать СУБД для решения одной частной задачи — организации манипулирования данными.