Хранение данных и доступ к ним
11.3 Индексы
Индексами называют структуры, которые могут обеспечить быстрый доступ к данным. Всем известен пример библиотечного каталога, который представляет собой как минимум два индекса.
Первый, так называемый тематический каталог, по названию раздела и подраздела позволяет найти местоположение всех книг этого раздела. При этом система тем и подтем представляет некоторую иерархию. Идя по ней, приходим к разделу содержащему небольшое количество книг и в нем выбираем нужную.
Второй, авторский, позволяет выбрать книги по авторам.
По числу строк, индексируемых каждым значением ключа, выделяют уникальные и неуникальные индексы. Уникальность индекса означает, что в таблице не существует более одной строки с каждым значением индексируемого столбца. Неуникальные индексы допускают повтор таких строк.
Если индекс строится на нескольких столбцах, его называют сцеплен-ным или конкатенированным в отличие от простого индекса, базирующегося на одном столбце.
В базах данных местоположение строки определяется по уникальному идентификатору ROWID, обычно соответствующему физическому адресу всей строки во вторичной памяти. Для расщепленных строк ROWID определяет адрес начальной части строки. Длина ROWTD обычно не превышает 8-12 байт.
Таблица может иметь внутренний псевдостолбец с именем ROWTD. Он не виден при выполнении команды SELECT * FROM ... , но обычно может быть выбран запросом с явным указанием ROWTD как имени столбца, что-нибудь вроде SELECT ROWID, ename FROM emp.
Учтите, что в Cache SQL применяется оригинальный способ хранения, не предусмотренный стандартом SQL, и потому псевдостолбец ROWID не используется, а, значит, подобные запросы не исполняются.
В ROWID содержатся, например, поле, определяющее один из файлов данных, принадлежащих табличному пространству, поле блока данных и поле номера строки в блоке. Современные СУБД поддерживают, как минимум следующие типы индексов:
- Древесный индекс на основе B*-деревьев.
- Побитовые индексы — bitmap index.
Альтернатива индексированию — хеширование.
11.3.1 B*-индексы
Что такое B-дерево?
- B-дерево сбалансировано. Это означает, что все пути от корневой вершины до всех листовых вершин одинаковы.
- Ключевые значения, указанные в листьях, есть копии ключей записей базы данных. Ключи расположены слева направо в порядке возрастания значений.
- Листовые вершины могут иметь указатели, ссылающиеся на следующую листовую вершину. Возможен вариант двунаправленной ссылки.
B*-дерево отличается тем, что в нем каждый ключ сопровождается указателем на запись (или записи) с этим ключом.
Следует помнить, что в отличие от графов, изучаемых в математике, узлы B-дерева это блоки базы данных..
Индекс называется плотным, если он содержит ключи для каждой записи файла данных. Разреженные индексы ссылаются на часть строк файла данных (или на блок данных).
Могут существовать другие типы индексов и структур, связанных с ними, например, индексные таблицы (index-organized table). Это разновидность B*-индекса, в которой листовые блоки индекса содержат не значения ROWID, адресующие данные, а сами данные в виде строки, не разделяемой на поля.
Рассмотрим пример работы B*-индекса, построенного на столбце ename (рисунок 11.4). Из таблицы emp выбираем по индексу строку с именем BLAKE, удовлетворяющую условию ENAME='BLAKE'. Такой поиск называется поиском по точному совпадению.
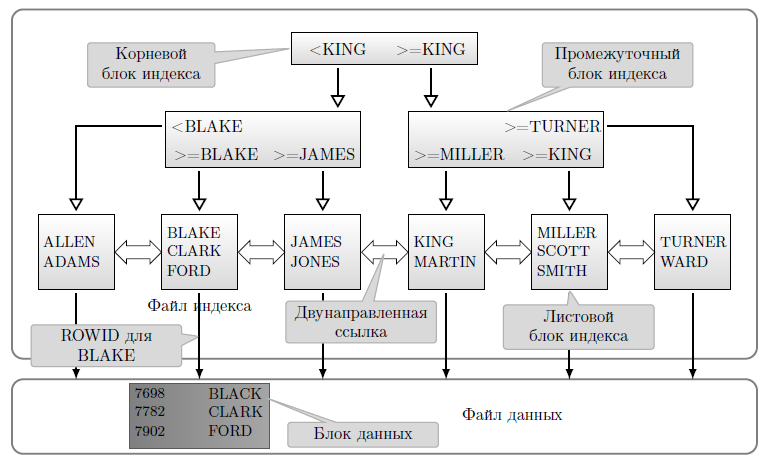
Как уже упоминалось, и корневой узел, и промежуточные, и листовые узлы индекса — это блоки данных. В них помещается информация, позволяющая организовать большое количество разветвлений, например 256. Так что глубина файла индекса для современных данных вряд ли превысит 5.
Сначала просматривается корневой блок, и по условиям <KJNG и >=KJNG определяется, на который из двух дочерних блоков перейти. Идем по левой ветви. В блоке первого уровня проверяются условия <BLAKE, >=BLAKE и >=JAMES и выбирается второе. Затем из листового блока второго уровня, содержащего три значения ROWID, выбираем идентификатор для BLAKE и, используя его как адрес, выбираем значение из файла данных.
Заметим, что для поиска нужного значения пришлось просмотреть три блока индекса и один блок данных. Если бы индекс не работал, пришлось бы организовать полное сканирование таблицы, просматривая все ее блоки. Теперь понятно, что для таблицы, занимающей всего один блок, применение индекса, скорее всего, не ускорит запрос.
В общем, индекс может повысить скорость выполнения запросов, но не обязательно это сделает. А вот скорость добавления и обновления записей в таблице он точно понизит. Дело в том, что при изменении данных индекс должен каждый раз перестраиваться.
При поиске по диапазону значений ключа проходят по дереву индекса от корня через блоки ветвей до крайнего левого листового блока, отвечающего условию поиска. Дальнейшее движение может происходить вправо по цепочке ссылок между листьями, пока не выберутся все значения ссылок, удовлетворяющих условию.
Вставка нового значения ключа производится в соответствующий листовой блок. Значения ключа обновляются путем удаления старой и вставки новой записей индекса. Переполняющийся блок индекса дробится. При этом добавляется пустой блок и значения ключей поровну распределяются между старым и новым блоками, за исключением случая, когда дробится самый правый листовой блок. Процесс дробления листовых блоков может рекурсивно перейти на промежуточные узлы.
Заметим, что блокирование на уровне строк удобно реализуется при описанной структуре индекса, задающего адреса именно строк.
Если строки индекса постоянно удаляются и добавляются, то через какое-то время индекс может "разредиться" или фрагментироваться. Обычно индекс расширяется вправо, и разрежается слева. Дело в том, что "брошенные" записи не заменяются новыми. Со временем объем индекса может существенно превысить объем данных. Дерево индекса может при этом стать глубже, чем должно быть для такого числа значений. Это уменьшает скорость индексного доступа. Поскольку типовой механизм организации B*-индекса не поддерживает динамического уплотнения и перебалансирования дерева, то лучшее решение в этом случае — пересоздание индекса. Например, при односменной работе вечером копируем таблицу, сортируя данные. Старую таблицу и индекс уничтожаем. Затем восстанавливаем таблицу по сортированной копии и создаем новый индекс. Дальше все зависит от того, насколько таблица изменится за следующий день.
11.3.2 Когда B*-индекс ускоряет запрос?
В литературе 80-х-90-х годов можно было найти "золотое правило", в соответствии с которым неуникальным индекс ускоряет работу, если запрос возвращает меньше, чем 10-15% строк таблицы. Попозже эти цифры заменили на 3-5% и правило перестали называть золотым.
Покажем, что при некоторых условиях индекс может быть неэффективен при любом числе возвращаемых строк.
Рассмотрим два крайних случая. Пусть таблица содержит 100 000 строк по 100 строк в каждом из 1000 блоков. Ключевой столбец содержит числовые значения от 0 до 99. Строки случайно распределены по блокам, так что в любом блоке с большой вероятностью содержатся строки с любым ключевым значением. При выполнении запроса по одному значению ключа, скорее всего, будут прочитаны все блоки, хотя нужно выбрать всего один процент строк. Кроме того, будут прочитаны еще и все блоки индекса, причем некоторые многократно. Это увеличит время выполнения запроса. Если индекс не используется, то также выбираются все 1000 блоков таблицы. В рассмотренной ситуации индекс не эффективен.
Теперь отсортируем строки таблицы по ключу. При использовании индекса будет выбран всего один блок данных и несколько блоков индекса. Без индекса пришлось бы выбирать все 1000 блоков таблицы. Теперь индекс ускоряет запрос.
Забегая вперед, отметим, что при правильной организации кэша буферов базы, все узлы индекса скорее всего через некоторое время с момента первого обращения будут находиться в оперативной памяти, так что затраты времени на работу с индексом станут минимальными.
Использование индекса ускоряет выполнение запроса за счет того, что позволяет считывать только блоки, содержащие нужные строки.