Объектные модели данных
Далее будет рассмотрено расширение модели данных за счёт включения в неё части метаданных. Это позволит работать со структурами данных, которые заранее не определены. Подобные модели принято называть универсальными. Обратим внимание на некоторые их особенности и способы реализации.
Универсальный язык моделирования UML, в основном диаграммы классов, будет кратко рассмотрен как обобщённая объектная модель. Использование UML имеет существенное преимущество потому, что весь проект информационной системы на уровне концептуальной модели, включая базы данных, интерфейсы пользователя и т.д., можно выполнить в одном графическом языке и в одном инструменте. Кроме того, UML позволяет получить схему объектной или объектно-реляционной базы.
К сожалению, доступные нам инструментальные средства позволяют получить скрипты только для изолированных классов базы данных. Поэтому примеров создания баз данных с помощью UML не будет.
Объёмистые второй и третий параграфы лекции представляют объектную модель ODMG на примере Cache и объектно-реляционную модель на примере Oracle. Замечательная особенность Cache в том, что связи между иерархической, реляционной и объектной моделями в ней встроены, и потому отслеживаются естественным образом, без каких-либо дополнительных средств.
10.1 Модели данных
Тип данных — фундаментальное понятие и программирования вообще, и теории баз данных, в частности. Можно считать, что тип определяет множество значений типа через набор операций, применимых к значениям типа. Иногда дополнительно задаётся способ хранения значений и выполнения операций. Любые данные, которыми оперируют программы, относятся к определённым типам. Но, как вы уже знаете, тип данных может не задаваться заранее, а значение, соответствующее типу, определяться в процессе чтения данных.
По крайней мере, некоторые данные должны обладать свойством перси-стентности — способностью сохраняться на диске.
Различия роли типов в программах и базах данных перечислены в таблице 10.1
| В программах | В базах данных |
|---|---|
| Часть программы | Часть базы данных |
| Используются в переменных и функциях | Используются в данных |
| Позволяют избежать неправильных вычислений | Обеспечивают целостность данных |
| Проверяются, как правило, статически (на стадии компиляции) | Проверяются и статически и динамически (во время исполнения) |
Задать тип данных — это значит определить:
- множество допустимых экземпляров типов;
- множество отношений;
- множество операций над экземплярами типов;
- множество ограничений на допустимость значений и применимость операций.
Проверка ограничений типов может выполняться во время компилирования (статическая типизация) или во время выполнения (динамическая типизация).
Следует учитывать, что понятие типа в математике обычно шире применяемого в программировании. Например, множество целых чисел в программировании обычно ограничено.
Кроме типов, могут использоваться домены, представляющие ограничения типов, имеющие некоторый смысл. Домены определяются на типах или других доменах, имеют уникальные в рамках базы имена и уточняются ограничениями на данные домена.
Для задания модели данных необходимо определить:
- перечень видов основных компонентов модели;
- правила комбинирования этих компонентов, задающие ограничения на возможные структуры данных;
- допустимые типы данных;
- допустимые операции над данными, которые могут быть представлены в рамках модели; в первую очередь это операции определения структур данных и манипулирования данными, среди которых выделяются запросы данных.
- применимые ограничения целостности данных и их структур; можно выделить внешние ограничения концептуальной модели и внутренние ограничений самой модели данных.
Заметим, что часть ограничений целостности может задаваться по умолчанию, а другие прописываются явно и могут распространяться на однотипные ситуации. В качестве внутренних ограничений модели данных могут использоваться, например, ограничения на ввод данных несовместимого типа и несоответствующей характеристики (по числу полей, по количеству записей и т.д.).
Бегло охарактеризуем с этой точки зрения модель "сущность-связь":
- основные компоненты: сущность, связь, атрибут;
- сущности бывают сильные и слабые,
- связи соединяют сущности; связи имеют кратности
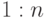 и
и  и бывают идентифицирующие и не идентифицирующие; не идентифицирующие связи делятся на обязательные и не обязательные;
и бывают идентифицирующие и не идентифицирующие; не идентифицирующие связи делятся на обязательные и не обязательные; - агрегаты сущностей и связей не предусматриваются;
- атрибуты входят в состав сущностей и связей; в связях можно выделить атрибуты привязки и эмерджентные атрибуты;
- обычно определяются типы данных число, строка, дата;
- допустимые операции над данными не уточняются, так как модель предназначена только для представления структур данных, но не манипулирования ими;
- допустимые ограничения целостности — первичный, уникальный и внешний ключи.
Иногда полезно поговорить о некоторой модели на языке описания другой модели. Например, описывая объектным языком реляционную модель данных, следовало бы указывать, что типы столбцов могут быть любыми, в том числе, векторными, но внутренняя структура данных всех типов в рамках реляционной модели не подлежит разбору. Таблицы представляют собой векторные типы. Конструкторы этих типов — команды CREATE TABLE и ALTER TABLE. Деструктор — команда DROP TABLE. Строки таблицы это экземпляры типов таблиц. Их конструкторы — команды INSERT, UPDATE, DELETE и TRUNCATE.
10.1.1 Схемы Джекобса
В 1982 г. Б. Джекобс ввел экспликацию понятия "схема", позволяющую однообразно описать хорошо известные к тому времени иерархическую, реляционную и сетевую модели баз данных.
На множестве имен  вводится понятие "R-правило", определенное как выражение вида:
вводится понятие "R-правило", определенное как выражение вида:

где  — имена из
— имена из  .
.
Имя 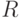 в левой части правила имеет высший порядок, имена
в левой части правила имеет высший порядок, имена  попарно различны, причём одно из них может совпадать с
попарно различны, причём одно из них может совпадать с 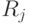 . Нулевой порядок могут иметь имена стоящие только в правых частях правил.
. Нулевой порядок могут иметь имена стоящие только в правых частях правил.
Схема базы данных (или просто схема) это конечный набор

R-правил обладающих свойствами:
левые части попарно различны;
множества имен нулевого порядка и высших порядков не пересекаются;
имена в правой части каждого правила уникальны.
Некоторые имена нулевого порядка могут быть именами связей между -правилами. Имена в левых частях правил, которые имеют ненулевой порядок и в схеме базы встречаются только один раз, называются внешними.
Пример схемы:
Sch={
Вуз = (Факультет),
Факультет = (Кафедра, Связь1),
Кафедра = (Название, Сотрудник),
Сотрудник = (ФИО, Должность, Связь2),
Связь1 = (Кафедра),
Связь2 = (Сотрудник),
Имена "Название", "ФИО", "Должность" имеют нулевой порядок. Имя "Вуз" внешнее. Учтите, что схемы Джекобса отображаются сложными таблицами, но не эквивалентны диаграммам сущность-связь и реляционным схемам.
С каждой схемой  можно связать контекстно-свободную грамматику, в которой имена нулевого порядка есть терминальные символы, а имена высших порядков являются нетерминальными и начальным символом.
можно связать контекстно-свободную грамматику, в которой имена нулевого порядка есть терминальные символы, а имена высших порядков являются нетерминальными и начальным символом.
Правило схемы определяет правило подстановки  ..
..
Выпишем свойства, определяющие реляционную, иерархическую и сетевую модели данных.
Характеристическое свойство реляционной модели
Определение (1). Схема будет реляционной, если в правых частях всех её -правил стоят только имена нулевого порядка.
Установим взаимно однозначное соответствие между -правилом и предикатом

Тогда определение реляционности схемы можно перефразировать так:
Определение (2). В реляционной схеме имена отношений не могут совпадать с именами атрибутов.
Характеристическое свойство иерархической модели
Определение (1). Схема будет иерархической, если любое имя может встречаться в правой части Д-правила только один раз и в грамматике, определённой схемой, не существует последовательности выводов такой, что 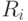 выводимо из .
выводимо из .
Определение (2). В иерархической модели имена отношений не могут повторяться и имя отношения не может быть связано с самим собой (как непосредственно, так и через несколько связей).
Характеристическое свойство сетевой модели
Определение (1). Схема будет сетевой, если нет правила, в котором имя высшего порядка встречается одновременно и в правой и в левой части.
Определение (2). В сетевой модели имена отношений не могут совпадать с именами атрибутов в рамках одного предиката.
Таким образом, с формальной точки зрения, перечисленные три модели отличаются лишь ограничениями на структуры данных, описанные выше как характеристические свойства. Заметим, что ограничения целостности не учитываются.
Дальнейшее рассмотрение схем Джекобса связано с введением формализма многосортной логики, который оказывается связанным с тремя перечисленными моделями данных. Но поскольку требуемый уровень изложения существенно выше принятого в книге, которую вы читаете, мы ограничимся указанием на то, что соответствующая теория была построена и отсылаем Вас к первоисточникам или к изложению этого вопроса в книге М.Ш. Цаленко [см. раздел "Что читать?"].
Для нас важно было осознать, что иерархическая, сетевая и реляционная модели могут быть выражены единым формализмом и, следовательно, имеют некоторое внутреннее родство.