Объектные модели данных
Триггеры в объектной модели
Поскольку триггеры в Cache это элементы класса, то кроме создания их в SQL, описанного в разделе 8.7, можно определить их прямым написанием текста в Cache Studio, либо воспользоваться мастером. Для вызова мастера создания триггера, необходимо выбрать пункт меню Класс > Добавить > Новый триггер SQL.
Вспомним, что тип триггера определяется событием, которое инициирует его выполнение (INSERT, UPDATE, DELETE), и моментом времени относительно этого события (BEFORE или AFTER). Ещё одно событие — UPDATE OF — возникает при изменении значений определенных столбцов. Но его можно использовать, только если код триггера написан на языке SQL.
Можно также задавать триггеры, срабатывающие сразу на несколько событий: INSERT/UPDATE, UPDATE/DELETE, INSERT/UPDATE/DELETE. Это означает, что триггер будет выполняться при возникновении любого из указанных событий.
Методы callback —это методы СУБД, которые определяют реакцию системы на некоторые события. В Cache существуют предопределённые callback-методы, и имеется возможность их переопределения. Это позволяет придерживаться принципа разделения системного и прикладного программного обеспечения, но одновременно дает возможность переопределения реакции системы.
Следует заметить, что при использовании некоторых вариантов задания событий, триггер становится эквивалентом одному из существующих callback-методов:
- BEFORE INSERT ~ %OnBeforeSave
- AFTER INSERT ~ %OnAfterSave
- BEFORE UPDATE — %OnBeforeSave
- AFTER UPDATE — %OnAfterSave
- BEFORE DELETE — %OnDelete
Однако это не значит, что, например, триггеры BEFORE INSERT и BEFORE UPDATE есть по сути одно и то же. Адекватный метод %OnBeforeSave выглядит следующим образом:
Method %OnBeforeSave(insert As %Boolean) As %Status [Private,ServerOnly=1]
{
if insert {
//код триггера на BEFORE INSERT
}
else {
//код триггера на BEFORE UPDATE
}
Quit $$$OK
}
Если возникает событие, ассоциированное с триггером, то вызывается выполнение кода этого триггера.
Рассмотрим подробнее создание триггера в Studio. Для примера создадим триггер на добавление строки в таблицу SQLUser.Person, который будет вставлять ID добавленного объекта в специальную таблицу LogTable, содержащую текстовый столбец TableName и числовой столбец IDValue.
При вызове мастера создания триггера появляется окно, как показано на рисунке 10.23.

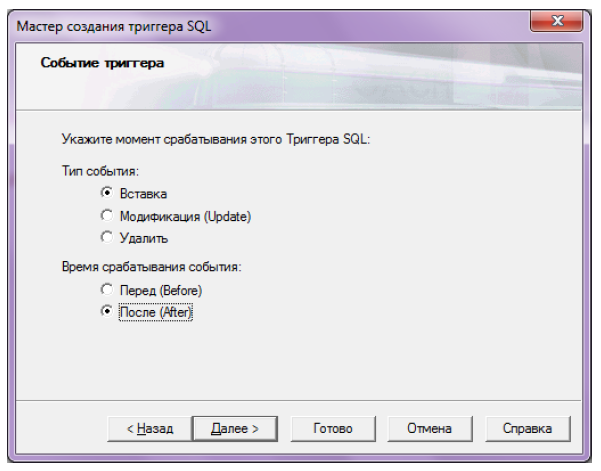
Введем название триггера "LogEvent" и нажав кнопку "Далее" перейдем к следующему окну. Здесь нужно указать событие и время срабатывания триггера. Выбрать можно только одно из событий INSERT, UPDATE, DELETE. Если необходимо указать несколько событий, придётся редактировать текст триггера вручную.
В определении класса событие задается с помощью параметра Event. Например:
Trigger NewTrigger1 [ Event = INSERT ]
Несколько событий можно указать через "/", например:
Trigger NewTrigger1 [ Event = INSERT/UPDATE ]
Выберем в мастере событие INSERT и время срабатывания AFTER (рисунок 10.24) и нажмем кнопку "Далее".
Последний шаг при создании триггера с помощью мастера — собственно написание кода.
ObjectScript-код триггера имеет некоторые особенности. Все локальные переменные в нем общедоступны. Поэтому, чтобы избежать побочных эффектов, необходимо явно объявлять их с помощью команды NEW.
Внутри кода можно ссылаться на значения полей таблицы с помощью синтаксиса {имя_поля}. Если для триггера указано событие UPDATE, появляется возможность использовать следующие конструкции:
- {имя_поля*О} — старое значение поля обновляемой строки;
- {имя_поля*N} — новое значение поля обновляемой строки;
- {имя^толя*C} —равно 1, если значение поля в обновляемой строке было изменено, иначе 0.
Добавим в текстовую область код, как показано на рисунке 10.25, и нажмем кнопку "Готово".
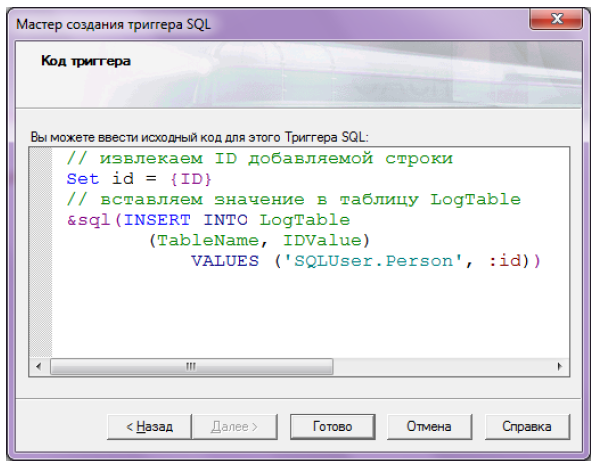
В определении класса появилось следующее понятное теперь описание:
Trigger LogEvent [ Event = INSERT, Time = AFTER ] {
// извлекаем ID добавляемой строки
Set id = {ID}
// вставляем значение в таблицу LogTable &sql(INSERT INTO LogTable (TableName, IDValue) VALUES ('SQLUser.Person', :id))
Его можно отредактировать вручную, если это необходимо. Например, можно указать не одно, а несколько событий срабатывания триггера, а также задать значение Order, которое позволяет управлять порядком выполнения триггеров одного типа.
Заметим, что код триггера может использовать методы класса, так как они не зависят от того, открыт ли какой-либо объект.
10.2.4 Класс %ResultSet
Класс %ResultSet позволяет использовать результаты запросов классов в программах, написанных на ObjectScript, Java или ActiveX. Есть два варианта обращения к %ResultSet. Первый способ состоит в создании экземпляра %ResultSet, методу %New() которого передаётся в качестве аргумента строка, содержащая разделённые двоеточием имя класса и имя запроса:
Set result=##class(%ResultSet).%New("Person:ByName")
Второй способ заключается в явном установлении свойств ClassName и QueryName
объекта %ResultSet. Set result=##class(%ResultSet).%New()
Set result.ClassName="Person" Set result.QueryName="ByName"
После того, как создан объект %ResultSet, необходимо выполнить запрос и затем проанализировать результат.
Объект %ResultSet располагает следующими основными методами:
- Execute() выполняет запрос, с которым связан объект %ResultSet;
- Next() осуществляет переход на следующую строку выборки;
- Close() закрывает %ResultSet после завершения его использования.
Для доступа к полям текущей записи класс %ResultSet предоставляет несколько способов:
- использование метода Get(), которому передаётся в качестве аргумента имя нужного столбца;
- использование свойства Data, которое также предоставляет доступ к значению столбца текущей записи по имени столбца; этот способ быстрее предыдущего;
- использование метода GetData(), которому передаётся в качестве аргумента номер столбца в запросе.
Ниже приведен пример использования класса %ResultSet с запросом ByName класса Person. Данный запрос возвращает данные о сотрудниках, упорядоченные по их именам в алфавитном порядке. В результате выводятся первые двадцать имен.
//создание экземпляра %ResultSet
Set result=##class(%ResultSet).%New("Person:ByName") //выполнение запроса Set sc=result.Execute() //обработка результатов в цикле For i=1:1:20 {
If result.Next(.sc) {
Write result.Data("Name"),! } Else { Quit
}
}
Класс %ResultSet может исполнять динамические SQL-запросы. В этом случае объект %ResultSet создается с указанием "%DynamicQue-ry:SQL":
S result=##class(%ResultSet).%New("%DynamicQuery:SQL")
Затем с помощью метода Prepare необходимо подготовить запрос, например:
S q="SELECT ID,Name,Salary FROM Employee WHERE Salary>90000" S sc=result.Prepare(q)
Созданный объект можно использовать так же, как в предыдущем случае.
Класс %ResultSet позволяет производить только последовательный обход записей в прямом порядке, от первой к последней. Чтобы вернуться назад и просмотреть предыдущие строки результата, нужно заново исполнять запрос (методом Execute()) и некоторое количество раз вызывать метод Next(), чтобы добраться до нужной записи.
Более удобный доступ к результатам исполнения запроса обеспечивает класс %ScrollableResultSet. Он позволяет обходить строки результата как в прямом порядке, используя метод Next() , так и в обратном, используя метод Previous(). Кроме того, у него имеется свойство CurrRow, в котором хранится номер текущей строки. Путем установления CurrRow в нужное значение, можно получать доступ к любой строке выборки по ее номеру (имеется в виду последовательный номер в выборке, но не ID).
При использовании %ScrollableResultSet запрос исполняется в момент первого обращения, а результат исполнения запроса сохраняется в глобальной переменной.
Приведём пример использования %ScrollableResultSet с тем же запросом ByName класса Person:
Set q="Person:ByName" //создание экземпляра
Set result=##class(%ScrollableResultSet).%New(q)
//выполнение
Set sc=result.Execute()
//просмотр первой записи
Do result.Next(.sc)
Write "1-я запись: ",result.Data("Name"),! //просмотр 10-й записи Set result.CurrRow=10
Write "10-я запись: ",result.Data("Name"),! //просмотр записей с 9-й по 2-ю в обратном порядке
Write "Записи с 9-й по 2-ю в обратном порядке:",! For i=9:-1:2 {
If result.Previous(.sc) {
Write result.Data("Name"),! } Else { Quit
}
}
В результате выполнения данного фрагмента кода появятся первая, затем десятая записи и записи с девятой по вторую, размещённые в обратном порядке. Важнейшей особенностью класса %ScrollableResultSet является то, что его экземпляры можно сохранять и использовать потом вновь в других приложениях.
10.2.5 Способы хранения класса
Используем созданные ранее классы Address и Person, имеющие следующую структуру:
Class User.Address Extends %SerialObject
{
Property City As %String; Property State As %String;
}
Class User.Person Extends %Persistent
{
Property Name As %String; Property YearOB As %Integer; Property Home As Address;
}
Как известно, по умолчанию объект класса Person сохраняется в глобале ^Temp.PersonD следующим образом:
^User.PersonD(2)=$lb("","Nick",1984,$lb("NewYork","NY"))
Чтобы изменить привычный способ хранения экземпляров класса Person, необходимо создать новый способ хранения (Storage). Это можно сделать при помощи кнопки на панели инструментов "Новый способ хранения". Появится мастер создания способа хранения (рисунок 10.26).
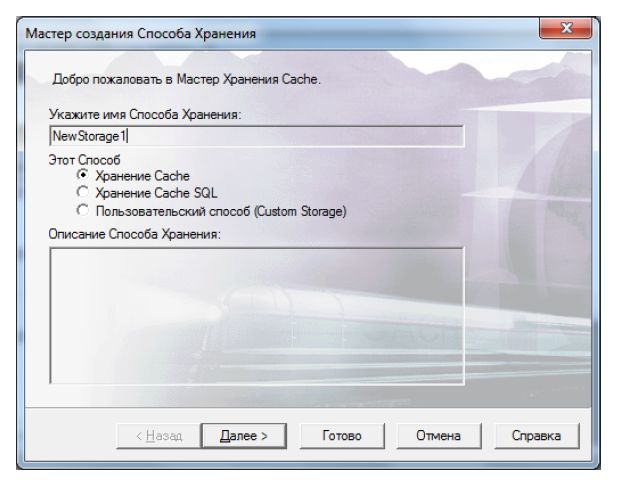
Выбираем способ хранения типа "Хранение Cache". Если нажмем "Далее", появится форма для ввода названий глобалов, в которых будет храниться информация об объектах вместо используемых по умолчанию ^User.PersonD и ^User.PersonI, однако мы их изменять не будем, поэтому просто нажимаем на кнопку "Готово".
Новый способ хранения создан. Обратимся к инспектору класса. В левом выпадающем списке выберем "Storage" и увидим имеющиеся в классе способы хранения (рисунок 10.27).
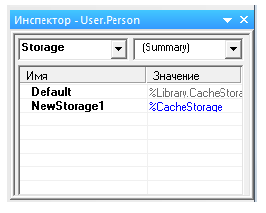
Дважды кликнув на "NewStorage1", перейдем в инспекторе к описанию данного способа хранения.
Изменим хранение свойств таким образом, чтобы домашний адрес человека располагался не в узле глобала ^User.PersonD(i) как вложенный список, а в отдельном узле под индексом ^User.PersonD(i, "Home").
Это можно проделать с помощью специального мастера. Чтобы его вызвать, нужно в инспекторе класса перейти на поле DataNodes способа хранения NewStorage1 и кликнуть на кнопку с многоточием (рисунок 10.28).
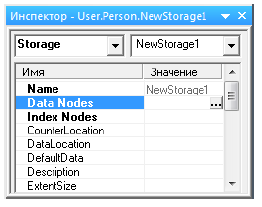
Появится следующий мастер, с помощью которого можно создавать узлы данных, определяющие способ хранения свойств экземпляров класса в глобале данных (рисунок 10.29).
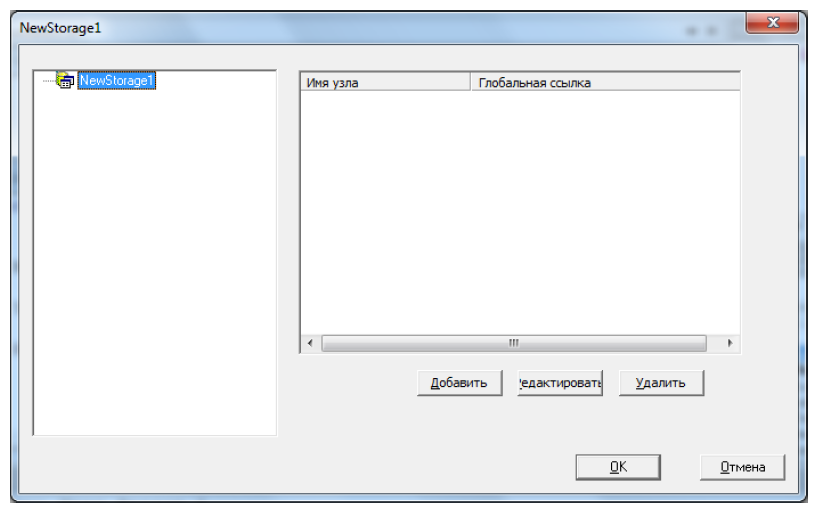
Мы должны создать два узла:
- В первом узле в виде списка будут храниться все свойства объекта, кроме домашнего адреса.
- Во втором под индексом "Home" будет храниться значение домашнего адреса.
Для создания первого узла нажмем кнопку "Добавить" и заполним появившуюся форму так, как показано на рисунке 10.30.
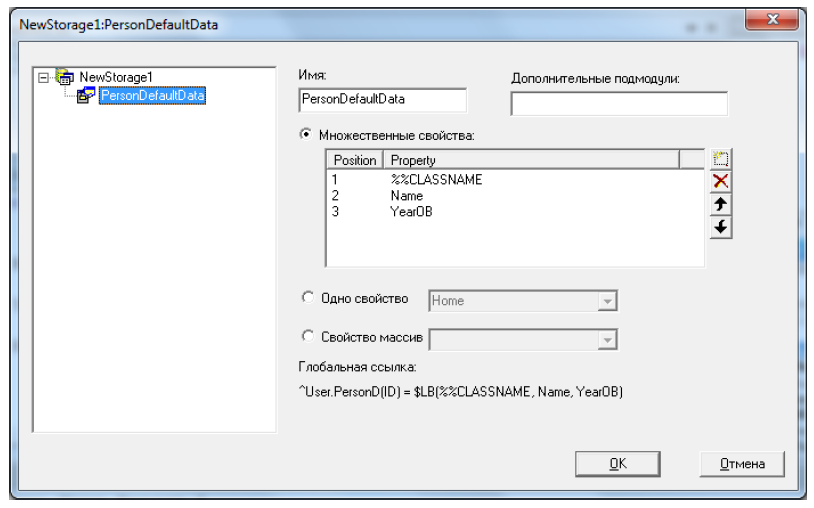
Поле Имя содержит имя узла данных внутри способа хранения. Узел PersonDefaultData содержится в способе хранения, создаваемом в классе по умолчанию. Мы создаем узел с таким же именем, в котором также в виде списка будут храниться значения всех свойств, кроме свойства Home.
Следует заметить, в выпадающем списке для выбора свойства, значение которого будет храниться в узле, нет доступа напрямую к %%CLASSNAME, поэтому его имя вводим вручную, набирая с клавиатуры %%CLASSNAME.
Все свойства, имеющиеся в классе должны быть отражены в способе хранения, включая %%CLASSNAME. Если какие-то из них пропущены, то при компиляции автоматически создается узел с именем PersonDefaultData, значением которого является список значений этих свойств. Если узел PersonDefaultData уже существует, то создается узел PersonDefaultData1, который хранит пропущенные данные в виде списка значений в узле глобала вида ^User.PersonD(i, 1).
Поле "Дополнительные подмодули" содержит список индексов глобала, определяющих путь к узлу глобала, в котором будут расположены указываемые данные. В данном поле можно указывать несколько индексов, а результат можно контролировать, следя за значением глобальной ссылки внизу окна.
Далее расположены 3 радио-кнопки с выбором:
- Множественные свойства. Выбор данного пункта означает, что в узле будет храниться список, содержащий указанные свойства в указанном порядке
- Одно свойство. Выбор данного пункта означает, что в узле будет храниться значение единственного указанного свойства.
- Свойство массив. Выбор данного пункта позволяет задать хранение свойств типа Список или Массив.
В нижней части формы показано, какой вид будет иметь глобальная ссылка для этого узла. В данном случае под индексом со значением ID будет храниться список вида $LB(%% CLASSNAME, Name, YearOB).
Теперь вновь перейдем на NewStorage1 и добавим еще второй узел, заполнив поля формы следующим образом (рисунок 10.31).
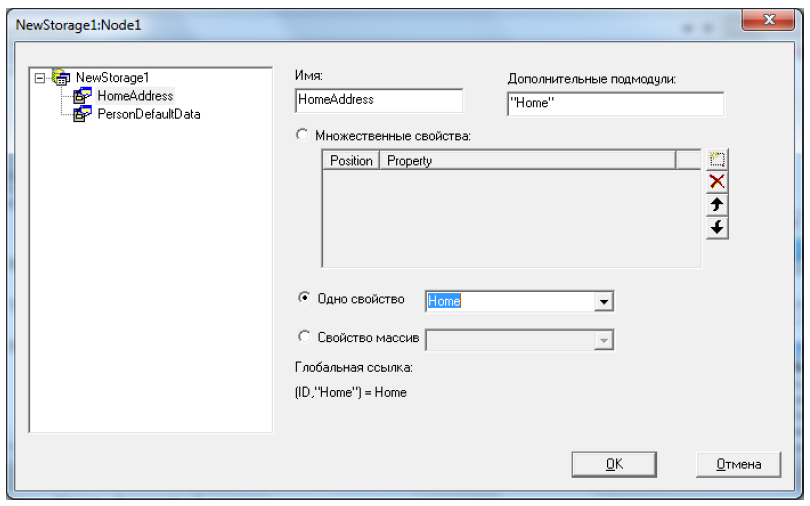
Нажмем "ОК" и откомпилируем класс.
Чтобы посмотреть, как изменилась структура хранения экземпляров класса Person, необходимо добавить в базу новый объект, так как изменение способа хранения для класса не перестраивает узлы, соответствующие ранее созданным объектам. Для этого выполним в терминале следующие команды:
USER>S p=##class(User.Person).%New() USER>S p.Name="Alex", p.YearOB=1989 USER>S p.Home.State="USA",p.Home.City="Washington" USER>D p.%Save()
С помощью портала управления системой увидим, что в глобале ^User.Person появилась ветка для этого объекта, имеющая следующий вид:
^User.PersonD(5)= $lb("","Alex",1989) ^User.PersonD(5,"Home")= $lb("Washington","USA")
Посмотрим, как влияет изменение способа хранения на SQL-проекцию класса Person. Выполним в портале запрос SELECT * FROM Person (таблица 10.9).
| # | ID | Name | YearOB | HomeCity | HomeState |
|---|---|---|---|---|---|
| 1 | 1 | Nick | 1 | ||
| 2 | 2 | Nick | |||
| 3 | 3 | Alex | 1989 | Washington | USA |
| Завершено | |||||
Мы видим, что SQL-проекция опирается на действующий в момент исполнения запроса способ хранения. Однако это не означает, что информация о хранении ранее созданных объектов утеряна. В классе сохраняется как новый, так и старый способ хранения. Действующий способ хранения указывается с помощью параметра класса StorageStrategy:
Class User.Person Extends %Persistent [ StorageStrategy = NewStorage1 ]
Сменив стратегию хранения, получим нормальный доступ через SQL к объектам, сохраненным ранее в соответствии с ней.
Однако, если на основании определенного способа хранения в базе были созданы некоторые объекты, а затем описание этого способа хранения было изменено, то информация об этих объектах будет полностью утеряна.
Поскольку структуру хранения можно прописать только у персистентно-го класса, то расположение узлов-свойств объекта типа Address в глобале ^User.PersonD придется описывать в классе Person, используя для указания необходимого свойства точечный синтаксис, например Home.City.
Изменение способа хранения может использоваться для повышения быстродействия.
10.2.6 Что мы узнали о реализации объектной модели в Cache, о связях моделей данных и какие ещё отображения могут быть интересны
Как и следовало ожидать, в Cache реализованы все основные особенности объектной модели данных. Оригинальные черты объектов в Cache определены двумя особенностями этой СУБД. Это:
- единая архитектура Cache, позволяющая "взглянуть" на одни и те же данные с точки зрения трёх моделей —иерархической, реляционной и объектной;
- возможность управлять способом хранения данных.
Единая архитектура определяет отображения между помянутыми тремя моделями данных, с которыми вы уже познакомились. Таблица представляется как класс без методов, а иерархии используются для хранения экземпляров классов, они же кортежи отношений или строки таблиц. Наследование оказывается возможным и в расширенном варианте реляционной модели.
С другой стороны, от реляционной модели в классы Cache перешли запросы, индексы и триггеры. В результате, запросы могут использоваться как фильтры набора объектов. Индексы, как и в таблицах, могут ускорить доступ к данным. Триггеры в объектной модели, использующей по умолчанию способ хранения %CacheStorage, не работают. Однако, при выборе другой модели хранения %CacheSQLStorage методы %Save() и %Delete() могут вызывать триггеры, если события для которых триггеры созданы наступили.
Для организации активности в объектной модели Cache пользуются методами обратной связи (Callback Methods), позволяющими создать свою обработку событий. Например, метод обратной связи %OnOpen() вызываемый методом %Open() , позволяет для хранимых и сериализуемых классов написать свои обработчики события открытия объекта.
Мы совсем не рассматривали те зарегистрированные классы, которые не являются ни хранимыми, ни сериализуемыми. Это аналоги классов языков общего назначения, таких как C++, Java и др.
Уже упоминалось (в разделе 10.1.4), что для интерфейсов пользователя, выполняющихся обычно на объектно-ориентированных языках, в том числе на специфичных для Cache технологиях CSP и Zen, выполняются отображения данных из базы в интерфейс и обратно. Мы их рассматривать не можем, однако, обратим внимание на интереснейшую возможность отображения классов Cache в классы Java.