Самостоятельная работа 2: Оптимизация вычислительно трудоемкого программного модуля для архитектуры Intel Xeon Phi. Линейные сортировки
Модификация позволила ускорить однопоточную версию на хосте с 11. 3 с до 5.3 с, т.е. почти в 2 раза. Параллельная версия стала работать 0.66 с, против 1 с в исходной версии, а при запуске на одном процессоре – 0.72 с, против 1.22 с. Запуск экспериментов на одном процессоре читателю пред-лагается выполнить самостоятельно.
увеличить изображение
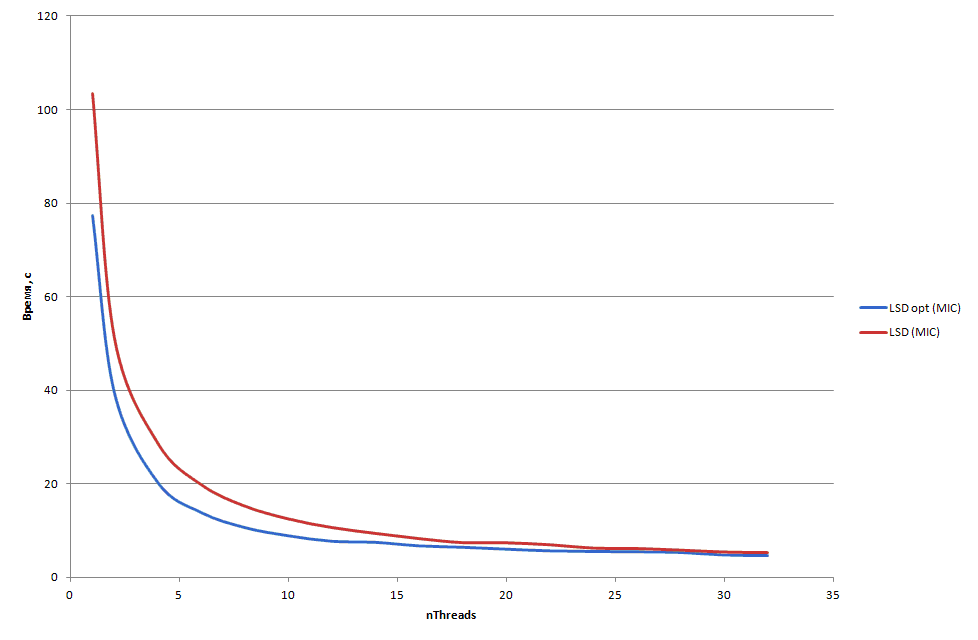
Рис. 4.26. Сравнение параллельных реализаций LSD на Intel Xeon Phi при сортировки 100 миллионов элементов (малое значение nThreads)
Однопоточная версия LSD на Intel Xeon Phi после модификация стала ра-ботать 77 с. Исходная версия работала 103 с.

увеличить изображение
Рис. 4.27. Сравнение параллельных реализаций LSD на Intel Xeon Phi при сортировки 100 миллионов элементов
При работе модифицированной версии LSD на большом количестве пото-ков наблюдается проигрыш исходной версии в связи с тем, что возрастает конкуренция потоков за кэш-память процессора, а реализованная упреж-дающая загрузка способствует ещё большей конкуренции за кэш-память.
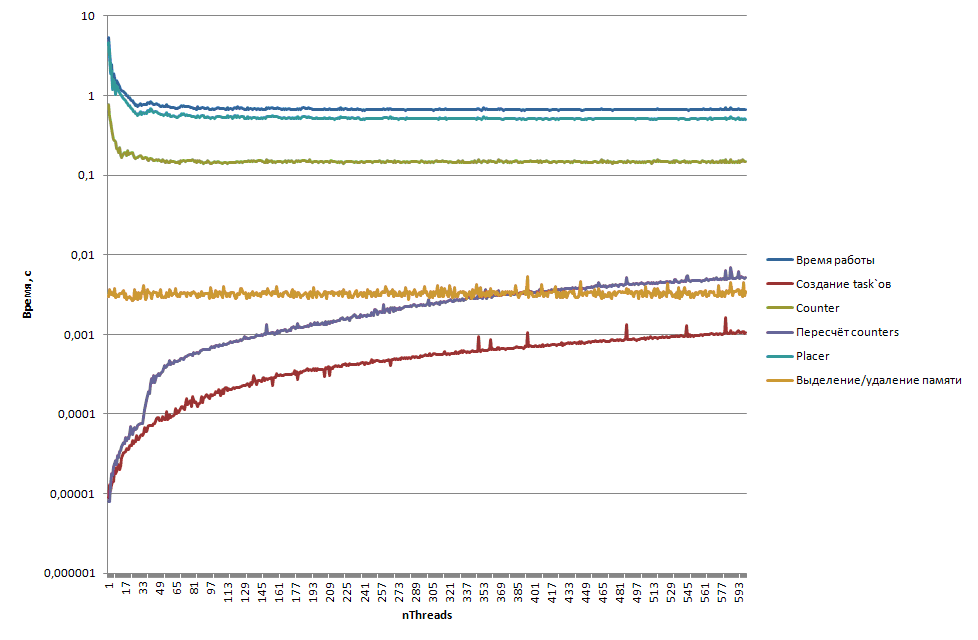
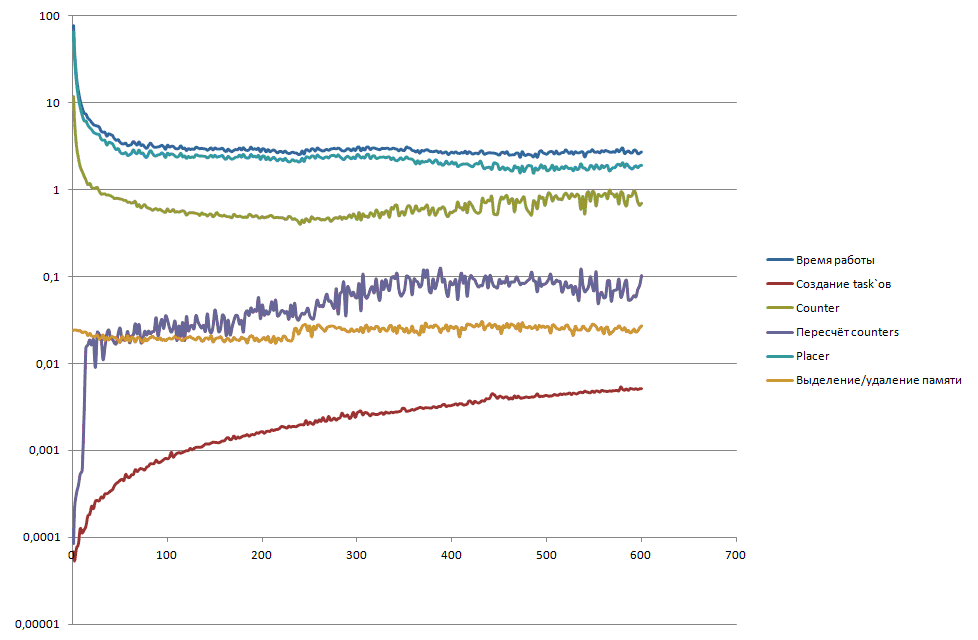
Для полноты картины приведём профиль модифицированной версии LSD на сортировке 100 миллионов элементов на хосте ( рис. 4.28) и сопроцессоре ( рис. 4.29).
увеличить изображение
Рис. 4.28. Профиль модифицированной параллельной сортировки LSD на хосте при сортировки 100 миллионов элементов
увеличить изображение
Рис. 4.29. Профиль модифицированной параллельной сортировки LSD на сопроцессоре при сортировки 100 миллионов элементов
Заключение
Пиковая теоретическая производительность сопроцессора Intel Xeon Phi 7110X составляет 1.2661 ядро * 1.238 ГГц * 16 чисел двойной точности за такт = 1208 гигафлопс терафлопс. Пиковая теоретическая производитель-ность двух процессоров Intel Xeon E5-2690 составляет 371716 ядер * 2.9 ГГц * 8 чисел двойной точности за такт = 371 гигафлопс гигафлопс.
Разница в пиковой теоретической производительности между сопроцессо-ром и хостом составляет больше 3 раз, но параллельная реализация LSD работает в 3 раза быстрее на хосте, чем на сопроцессоре. Этому есть не-сколько причин:
- Задача сортировки не является вычислительно сложной, поэтому пока-затель количества операций с плавающей запятой в секунду не столь важен. Основная нагрузка ложиться на подсистему памяти и опреде-ляющим является эффективность работы с ней. Intel Xeon Phi имеет большое количество ядер и сложную организацию подсистемы памяти с кэшами на кольцевой шине. Для решения задачи когерентности дан-ных в сопроцессоре используется распределённый словарь. Всё это не-гативно сказывается на скорости работы параллельных программ, об-ладающих низкой степенью локальности данных.
- Подходы к оптимизации, которые работали в параллельных системах с процессорами общего назначения, могут не работать на нестандартной архитектуре Intel Xeon Phi.
Всё вышесказанное справедливо и для сортировки из библиотеки TBB.
Обратим внимание на масштабируемость полученной параллельной реализации. На хосте время работы на одном процессоре (8 ядер) составило 1.22 с, а на двух (16 ядер) – 1 с. Увеличение количества процессоров в два раза даёт крайне малый выигрыш во времени работы. А общее ускорение от использования 16 ядер составило 11 (68.75% от линейного ускорения). На сопроцессоре (61 ядро) удалось достигнуть ощутимо лучшего результата – ускорение более 56 раз, 91.8% от линейного ускорения (стоит, конечно, отметить, что ядра на сопроцессоре проще и однопоточная версия простаивает каждый второй такт). Несмотря на большую разницу в полученном ускорении, времена работы на хосте и сопроцессоре получились сопоставимы (1.22 с на хосте против 1.83 с Xeon Phi). В первую очередь это связано с медленной работой однопоточной версии на сопроцессоре. Таким образом, если оптимизировать программный код под архитектурные особенности Xeon Phi, то на сопроцессоре могут быть получены ощутимо лучшие результаты.
Итак, даже в достаточно сложных для решения на Intel Xeon Phi задачах (а сортировка – именно такая задача в связи с малым запасом внутреннего параллелизма, неудачным соотношением количества вычислительных операций и операций с памятью, сомнительным потенциалом использования векторных вычислений) путем умелой организации вычислений можно добиться приемлемой производительности, что и продемонстрировано в данной работе.
Дополнительные задания
Дополнительные задания имеют разный уровень сложности. Некоторые из них являются достаточно трудоемкими и требуют изучения дополнитель-ной литературы.
Все задания предполагают выполнение реализаций для систем с общей памятью.
- Реализуйте более эффективную генерацию массивов для сортировки (эффективность повысится, если функция viRngUniformBits( будет генерировать большие последовательности бит). Оценить эффективность реализации.
- Реализуйте побайтовую восходящую сортировку для типа double в общем случае (числа могут быть как положительные, так и отрицательные). Оценить эффективность реализации для разных типов сгенерированных последовательностей чисел.
- Реализуйте побайтовую восходящую сортировку для типов int, unsigned int, float. Оценить эффективность реализации.
- Реализуйте побитовую восходящую сортировку для типов int, unsigned int, float, double. Оценить эффективность реализации.
- Реализуйте побайтовую восходящую сортировку для типа double в общем случае (числа могут быть как положительные, так и отрицательные) на Intel Xeon Phi. Оценить эффективность реализации для разных типов сгенерированных последовательностей чисел.
- Реализуйте побайтовую восходящую сортировку для типов int, unsigned int, float на Intel Xeon Phi. Оценить эффективность реализации.
- Реализуйте побитовую восходящую сортировку для типов int, unsigned int, float, double на Intel Xeon Phi. Оценить эффективность реализации.