Самостоятельная работа 2: Оптимизация вычислительно трудоемкого программного модуля для архитектуры Intel Xeon Phi. Линейные сортировки
Параллельная поразрядная сортировка
Наиболее эффективными параллельными алгоритмами являются те, которые имеют внутренний параллелизм.
Алгоритм побайтовой сортировки заключается в последовательном применении сортировки подсчётом к каждому байту чисел, поэтому параллельно может выполняться только сортировка подсчётом для каждого байта. Сортировка подсчётом состоит из двух этапов: подсчёт количества элементов и их размещение. Первый этап может быть выполнен параллельно над частями массива и в последующем редуцирован. Второй этап может быть выполнен параллельно только в том случае, если при его выполнении будет сохраняться свойство устойчивости сортировки. Для этого достаточно пересчитать смещения для каждой порции массива.
Параллельный алгоритм сортировки подсчётом будет состоять из следующих шагов:
- Для каждого потока создаётся массив подсчётов и заполняется нулями.
- Каждый поток получает на обработку часть массива и выполняет подсчёт элементов в свой массив подсчётов.
- С помощью массивов подсчётов со всех потоков выполняется вычисление смещений, по которым будут располагаться элементы при втором проходе по массиву.
- Каждый поток получает на обработку ту же часть массива, что и ранее, и выполняет копирование элемента во вспомогательный массив по соответствующему индексу в массиве смещений.
Ниже представлен программный код указанного алгоритма с использованием TBB. Класс Counter выполняет подсчёт по указанному байту количества элементов.
class Counter:public task
{
double *mas;
int size;
int byteNum;
int *counter;
public:
Counter(double *_mas, int _size, int _byteNum,
int *_counter) : mas(_mas), size(_size),
byteNum(_byteNum), counter(_counter)
{}
task* execute()
{
unsigned char *masUC=(unsigned char *)mas;
memset(counter, 0, sizeof(int)*256);
for(int i=0; i<size; i++)
counter[masUC[8*i+byteNum]]++;
return NULL;
}
};
Класс Placer выполняет размещение элементов по указанным смещениям.
class Placer:public task
{
double *inp, *out;
int size;
int byteNum;
int *counter;
public:
Placer(double *_inp, double *_out, int _size,
int _byteNum, int *_counter) : inp(_inp),
out(_out), size(_size), byteNum(_byteNum),
counter(_counter)
{}
task* execute()
{
unsigned char *inpUC=(unsigned char *)inp;
for(int i=0; i<size; i++)
{
out[counter[inpUC[8*i+byteNum]]]=inp[i];
counter[inpUC[8*i+byteNum]]++;
}
return NULL;
}
};
Класс ParallelCounterSort реализует параллельную сортировку подсчётом.
class ParallelCounterSort:public task
{
private:
double *mas;
double *tmp;
int size;
int nThreads;
int *counters;
int byteNum;
public:
ParallelCounterSort(double *_mas, double *_tmp,
int _size, int _nThreads,
int *_counters, int _byteNum):
mas(_mas), tmp(_tmp), size(_size),
nThreads(_nThreads),
counters(_counters),
byteNum(_byteNum)
{}
task* execute()
{
Counter **ctr = new Counter*[nThreads-1];
Placer **pl = new Placer*[nThreads-1];
int s = size / nThreads;
for(int i=0; i<nThreads-1; i++)
ctr[i] = new (allocate_child()) Counter(mas + i*s, s,
byteNum, counters + 256 * i);
Counter &ctrLast = *new (allocate_child())
Counter(mas + s * (nThreads-1),
size - s * (nThreads-1) ,
byteNum,
counters + 256 * (nThreads-1));
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(ctr[i]));
spawn_and_wait_for_all(ctrLast);
int sm = 0;
for(int j=0; j<256; j++)
{
for(int i=0; i<nThreads; i++)
{
int b=counters[j + i * 256];
counters[j + i * 256]=sm;
sm+=b;
}
}
for(int i=0; i<nThreads-1; i++)
pl[i] = new (allocate_child()) Placer(mas + i*s, tmp,
s, byteNum,
counters + 256 * i);
Placer &plLast = *new (allocate_child())
Placer(mas + s * (nThreads-1), tmp,
size - s * (nThreads-1) , byteNum,
counters + 256 * (nThreads-1));
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(pl[i]));
spawn_and_wait_for_all(plLast);
delete[] pl;
delete[] ctr;
return NULL;
}
};
Класс ParallelCounterSort реализует побайтовую восходящую сортировку для типа double. Для этого в методе execute() 8 раз вызывается параллельная поразрядная сортировка.
class LSDParallelSorter:public task
{
private:
double *mas;
double *tmp;
int size;
int nThreads;
public:
LSDParallelSorter(double *_mas, double *_tmp, int _size,
int _nThreads): mas(_mas), tmp(_tmp),
size(_size), nThreads(_nThreads)
{}
task* execute()
{
int *counters = new int[256 * nThreads];
ParallelCounterSort *pcs = new (allocate_child())
ParallelCounterSort(mas, tmp, size, nThreads,
counters, 0);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(tmp, mas, size, nThreads,
counters, 1);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(mas, tmp, size, nThreads,
counters, 2);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(tmp, mas, size, nThreads,
counters, 3);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(mas, tmp, size, nThreads,
counters, 4);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(tmp, mas, size, nThreads,
counters, 5);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(mas, tmp, size, nThreads,
counters, 6);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
pcs = new (allocate_child())
ParallelCounterSort(tmp, mas, size, nThreads,
counters, 7);
set_ref_count(2);
spawn_and_wait_for_all(*pcs);
delete[] counters;
return NULL;
}
};
Создайте пустой файл main.cpp и скопируйте в него код из файла main_lsd4.cpp. Добавьте рассмотренный выше программный код в файл main.cpp с заменой реализации класса LSDParallelSorter на новую.
Соберите получившуюся реализацию и проведите тест для 10 миллионов элементов при разном числе потоков. Результаты, полученные авторами на тестовой инфраструктуре, представлены на рис. 4.13.
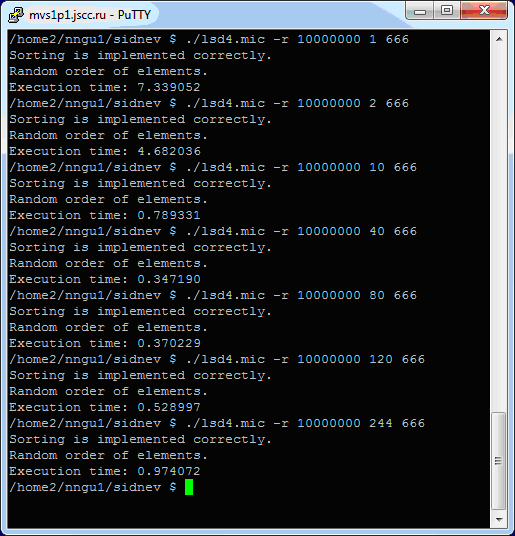
Здесь мы запускали только вариант со случайным заполнением, но с разным числом потоков. Для наглядности приведём графики времени сортировки 100 миллионов ( рис. 4.14) элементов с помощью параллельного алгоритма LSD на сопроцессоре.
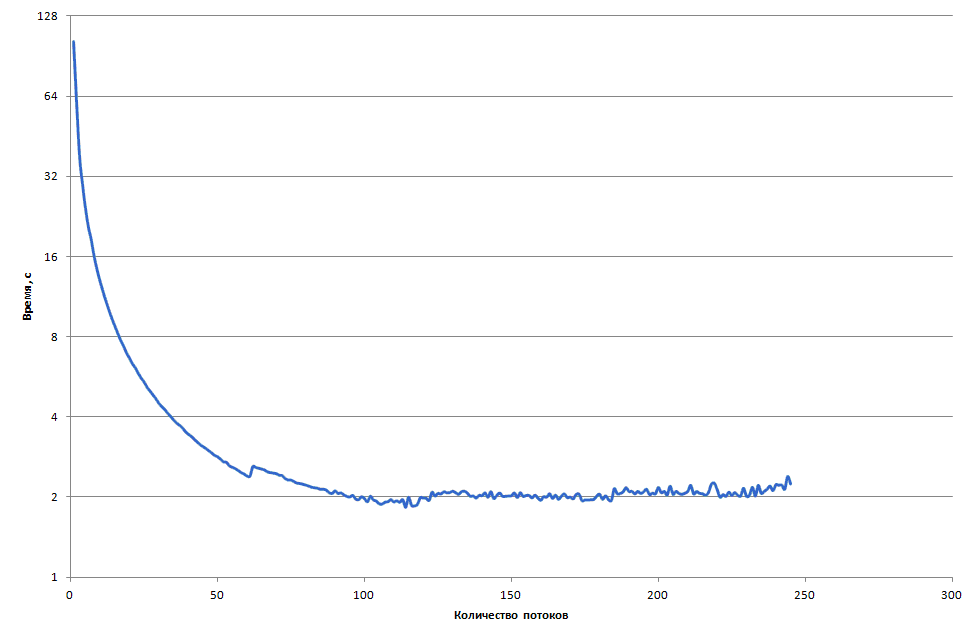
увеличить изображение
Рис. 4.14. Время сортировки 100 миллионов элементов с помощью параллельного алгоритма LSD на Intel Xeon Phi
Максимальное ускорение, равное 56,2, достигает при использовании 115 потоков. Таким образом, алгоритм внутреннего распараллеливания обладает наилучшей масштабируемостью из рассмотренных. Далее разберём этот алгоритм подробнее.
Заключение
Мы рассмотрели 3 алгоритма внешнего распараллеливания сортировки за счёт слияния отсортированных частей. Трудоёмкость слияния является линейной и, при использование сортировок со сложностью  , подобные алгоритмы дают существенный выигрыш. Определяющим тут является асимптотическая трудоёмкость сортировки и алгоритма слияния. При использовании линейных сортировок асимптотический выигрыш пропадает и использование алгоритмов слияния становится неэффективным. При сортировке 100 миллионов элементов удалось достигнуть ускорения всего в 19 раз (всего доступно 61 ядро).
, подобные алгоритмы дают существенный выигрыш. Определяющим тут является асимптотическая трудоёмкость сортировки и алгоритма слияния. При использовании линейных сортировок асимптотический выигрыш пропадает и использование алгоритмов слияния становится неэффективным. При сортировке 100 миллионов элементов удалось достигнуть ускорения всего в 19 раз (всего доступно 61 ядро).
Внутренняя реализация параллельного алгоритма LSD показала себя с лучшей стороны. Максимальное ускорение составило 56 раз по сравнению с последовательной версией.