Лекция 1: Элементы оптимизации прикладных программ для Intel Xeon Phi: Intel MKL, Intel VTune Amplifier XE
Использование библиотеки Intel MKL при программировании на сопроцессоре Intel Xeon Phi
Презентацию к лекции Вы можете скачать здесь.
В данном разделе рассматриваются модели использования библиотеки Intel Math Kernel Library при программировании на Intel Xeon Phi. Дается обзор способов вызова функций библиотеки, а также рекомендации по повышению производительности приложений.
Intel Math Kernel Library (Intel MKL) [1.7] является одной из самых производительных библиотек математических функции для работы на аппаратном обеспечении компании Intel. Библиотека включает в себя основные функции, используемые при разработке сложных высокопроизводительных программных комплексов.
Библиотека содержит функционал из следующих областей:
- Линейная алгебра (BLAS, LAPACK, работа с разреженными данными);
- Быстрое преобразование Фурье;
- Векторные функции (тригонометрические, гиперболические, экспоненциальные и логарифмические, возведение в степень и взятие корня, округление);
- Векторные генераторы случайных чисел и функции математической статистики;
- Интерполяция данных.
На текущий момент Intel MKL поддерживает параллельное выполнение как на системах с общей памятью (в частности, на сопроцессорах Intel MIC), так и на кластерах ( рис. 1.1). Поддержка сопроцессора Intel Xeon Phi появилась в библиотеке с версии 11.0.

Поддержка сопроцессора включает в себя возможность исполнения кода библиотеки Intel MKL одновременно на центральном процессоре и сопроцессоре, позволяя получать все преимущества от использования гетерогенного режима вычислений. Код библиотеки был оптимизирован для работы с 512-битными SIMD инструкциями.
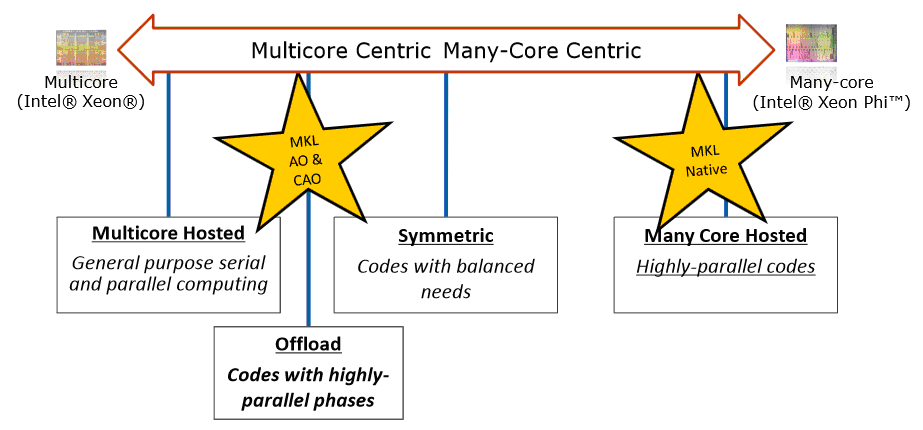
Для работы с библиотекой программисту доступны три модели ( рис. 1.2):
- Автоматический offload (Automatic Offload, AO) – прозрачная модель гетерогенных вычислений;
- Offload с помощью компилятора (Compiler Assisted Offload, CAO) – предоставляет возможности контроля offload’а.
- Выполнение только на сопроцессоре (Native Execution) – использование сопроцессоров в качестве независимых узлов.
Automatic Offload (AO)
Модель автоматического offload’а является наиболее простым способом, позволяющим эффективно использовать возможности библиотеки Intel MKL на системах с одним или несколькими сопроцессорами.
Данная модель практически не требует изменения существующего кода, написанного для центрального процессора. Использование сопроцессора библиотекой Intel MKL происходит автоматически при вызове функций библиотеки. Это означает, что все обмены данными и передача управления ускорителю происходят внутри вызова функции без участия программиста.
По умолчанию, MKL заботится и о балансировке нагрузки на систему. Библиотека сама решает, нужно ли в данном случае использовать сопроцессор, и как распределить нагрузку между процессором и сопроцессором. Основной критерий использования ускорителя для выполнения той или иной функции – эффективность. Т.е. если данная функция при данных входных параметрах будет работать лучше на CPU, то ускоритель использоваться не будет. В случае если в момент вызова функции сопроцессор занят другой задачей, для вычисления этой функции будет использован центральный процессор.
Распределение нагрузки также может быть выполнено автоматически. При этом используются все доступные в системе сопроцессоры и CPU, количество ускорителей и процент нагрузки на них выбирается библиотекой исходя из достижения лучшей производительности в каждом конкретном случае. Это позволяет автоматически эффективно использовать все доступные вычислительные ресурсы системы. Следует отметить, что программист может задавать желаемое распределение нагрузки самостоятельно.
Для того чтобы начать работать с AO, достаточно включить этот режим. Из программы это делается вызовом функции:
mkl_mic_enable();
Возможно также использование переменной окружения:
MKL_MIC_ENABLE=1
Отметим, что если в системе не установлено ни одного сопроцессора, функции Intel MKL будут работать на CPU без дополнительных накладных расходов.
Еще раз заметим, что исполняться на сопроцессоре будут только те функции, для которых существует эффективная реализация. В версии Intel MKL 11.0 на сопроцессоре будут выполняться только функции BLAS 3-го уровня *GEMM, *TRSM и *TRMM. В следующих версиях библиотеки планируется расширить поддержку сопроцессора.
Для указанных выше функций выполнение на сопроцессоре зависит и от входных размеров матрицы:
- Функции *GEMM выполняются на ускорителе, если M, N > 2048;
- Функции *TRSM/*TRMM выполняются на ускорителе, если M, N > 3072.
Для квадратных матриц вычисления на сопроцессоре происходят быстрее.
Для того чтобы задать желаемое распределение нагрузки между процессором и сопроцессорами можно воспользоваться функцией:
mkl_mic_set_Workdivision(MKL_TARGET_MIC, 0, 0.5);
В данном примере указывается, что на нулевой сопроцессор должно приходиться 50% общей нагрузки.
Такого же эффекта можно добиться с помощью переменной окружения:
MKL_MIC_0_WORKDIVISION=0.5
Обратим внимание, что данные команды являются лишь советами среде выполнения Intel MKL и реально могут не исполняться либо исполняться не точно.
Для того чтобы отключить режим AO после того, как он был задействован, необходимо либо вызвать функцию:
mkl_mic_disable();
либо перенести всю вычислительную нагрузку на центральный процессор вызовом функции:
mkl_mic_set_workdivision(MIC_TARGET_HOST, 0, 1.0);
либо воспользоваться переменной окружения:
MKL_HOST_WORKDIVISION=100
Для более эффективной работы режима автоматического offload’а рекомендуется избегать использования ядра операционной системы ускорителя для вычислений, т.к. это ядро обычно используется для выполнения передач данных и очистки памяти.
Приведем пример настройки соответствующей переменной окружения для случая сопроцессора с 60 ядрами и 4 потоками на ядро:
MIC_KMP_AFFINITY=explicit,granularity=fine,proclist=[1-236:1]
В данном примере для вычислений резервируются первые 59 ядер, т.е. первые 236 потоков.
Дополнительно следует явно привязать потоки хоста к ядрам, чтобы избежать миграции потоков:
KMP_AFFINITY=granularity=fine,compact,1,0
Обратите внимание на различие имен переменных окружения для хоста и сопроцессора. В случае Intel MIC, к имени переменной добавляется приставка MIC_ (OMP_NUM_THREADS/MIC_OMP_NUM_THREADS и т.п.).
Подробнее об этих переменных окружения для Intel компилятора и описанных выше параметрах можно почитать здесь [1.9].