Лекция 1: Элементы оптимизации прикладных программ для Intel Xeon Phi: Intel MKL, Intel VTune Amplifier XE
Профилировка приложений на Intel Xeon Phi
Intel VTune Amplifier XE позволяет выполнять профилировку приложений непосредственно на сопроцессоре. На текущий момент пользователю доступны следующие готовые типы анализа:
- Lightweight Hotspots. Позволяет определить функции и участки кода, на выполнение которых тратится больше всего времени. Аналогичен hotspots, но статистика собирается с использованием специальных регистров процессора для мониторинга производительности [1.10].
- General Exploration. Позволяет выявить микроархитектурные особенности, отрицательно влияющие на производительность. Это могут быть, например, частые промахи L1 или L2 кэша, промахи TLB кэша или степень векторизации кода.
- Bandwidth. Предназначен для анализа пропускной способности памяти.
На текущий момент поддерживается только одна технология сбора данных о работе приложения – Event-Based Sampling. Эта технология опирается на использование специальных аппаратных регистров (Performance Monitoring Units), предназначенных для учета различных низкоуровневых событий, происходящих во время работы программы. В текущих сопроцессорах Intel Xeon Phi на ядро приходится 2 регистра, накапливающих информацию о событиях, специфичных для потока или ядра. Присутствуют также 4 регистра за пределами ядра, не обладающих информацией о потоках и ядрах.
Соответственно за один запуск можно получить информацию максимум о 2 событиях ядра и 4 внешних событиях. Если нужно больше информации, то Intel VTune Amplifier XE будет выполнять ваше приложение несколько раз.
В дополнение к существующим типам анализа пользователь может создавать свои типы для получения информации о других интересующих его событиях. Проще всего новый тип анализа создавать на основе существующего. Для этого необходимо скопировать наиболее подходящий тип анализа и добавить в него интересующие вас счетчики событий.
Подробнее о событиях сопроцессора Intel Xeon Phi можно почитать в документации PMU [1.10].
Далее рассмотрим процесс запуска профилировки приложения на Intel Xeon Phi. Предполагается, что все действия выполняются на машине с подключенным к ней сопроцессором.
Запуск процесса профилировки из GUI.
Рассмотрим процесс запуска приложения с помощью GUI компонента Intel VTune Amplifier XE. Во-первых, создаем новый проект, в рамках которого будем исследовать нужное нам приложение. В случае offload программы заполняем поля свойств проекта следующим образом (вкладка Target):
- Application: полный путь к исполняемому файлу;
- Application parameters: параметры приложения (если необходимо);
- Working directory: путь к рабочей директории, где будут храниться результаты профилировки (обычно не имеет значения).

На вкладке Search Directories нужно указать путь к исходным файлам приложения для возможности навигации по коду программы при просмотре результатов ( рис. 1.3).
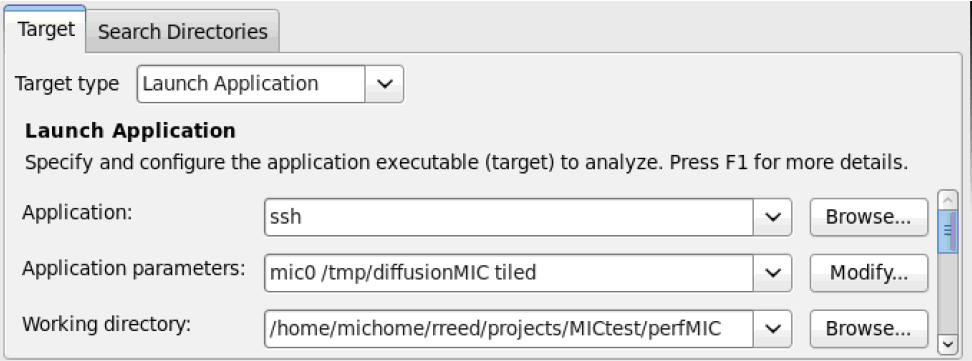
Если выполняется запуск программы в режиме работы только на сопроцессоре, то в качестве приложения для запуска указывается ssh, а само приложение указывается в качестве параметра в поле Application Parameters ( рис. 1.4).
Следующий шаг – выполнение профилировки приложения. Для этого необходимо выбрать пункт меню "New Analysis…", выбрать нужный тип анализа в дереве типов из папки "Knights Corner Platform Analysis" и начать профилировку ( рис. 1.5).
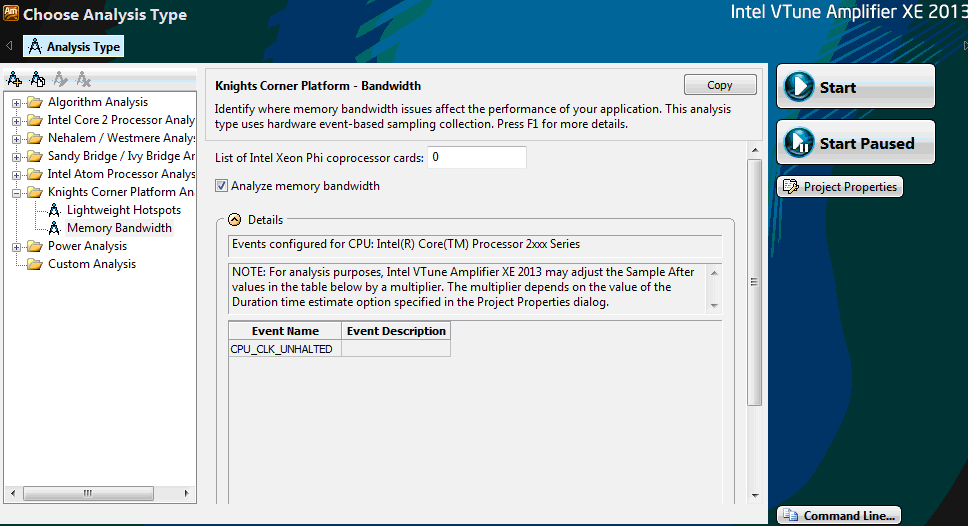
Для создания собственного типа анализа на основе существующего достаточно нажать на кнопку "Copy" и в открывшемся окне добавить нужные счетчики. Также обратите внимание, что нажав на кнопку "Command Line…" вы получите командную строку для текущего типа анализа, с помощью которой можно запустить профилировку из консоли.
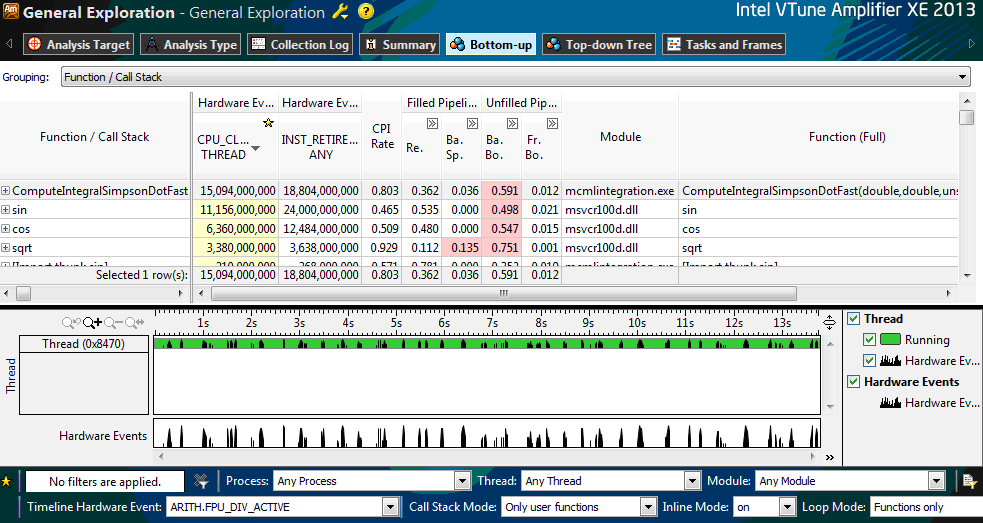
По завершении профилировки результаты будут отражены на экране ( рис. 1.6).
Запуск процесса профилировки из командной строки.
Для работы с Intel VTune Amplifier XE из командной строки прежде всего необходимо создать все нужные переменные окружения. Это можно сделать вызовом специального скрипта из папки с установленным инструментом:
source /opt/intel/vtune_amplifier_xe/amplxe-vars.sh
После этого можно запускать процесс профилировки.
Для offload приложения это делается командой:
amplxe-cl –collect knc-lightweight-hotspots –knob target-cards=0,1 –result-dir ./offload_cmd -- ./offload.out
Рассмотрим подробнее ключи запуска профилировщика.
Ключ "–collect knc-lightweight-hotspots" говорит о том, что будет проводиться один из предварительно настроенных типов анализа. В данном примере используется Lightweight Hotspots. Остальные типы имеют имена "knc-general-exploration" и "knc-bandwidth" соответственно.
Следующий ключ "–knob target-cards=0,1" говорит о том, на каких сопроцессорах запускать анализ приложения. Имеет смысл только для offload приложений.
Ключ "–result-dir ./offload_cmd" указывает на директорию, куда будут записаны результаты анализа.
И, наконец, параметр "-- ./offload.out" говорит о том, какое приложение (в нашем случае это "./offload.out" ) и с какими аргументами должно быть запущено.
Для приложений в режиме исполнения только на сопроцессоре командная строка будет такой:
amplxe-cl –collect knc-lightweight-hotspots –reslut-dir ./native-cmd -- ssh mic0 "export LD_LIBRARY_PATH=~/; export OMP_NUM_THREADS=244; export KMP_AFFINITY=balanced; ./native.out"
Обратите внимание, что в качестве приложения для запуска используется команда ssh, после которой следует имя узла сопроцессора, и далее команды для выполнения на этом сопроцессоре.
Приведем пример того, как из командной строки запустить свой собственный тип анализа:
amplxe-cl –collect-with runsa-knc –knob event-config=CPU_CLK_UNHALTED,L2_DATA_READ_MISS_MEM_FILL:sa=1000, L2_DATA_WRITE_MISS_MEM_FILL,L2_VICTIM_REQ_WITH_DATA,SNP_HINT_L2,HWP_L2MISS –knob target-cards=0,1 –result-dir ./custom-cmd -- ./offload.out
Для указания того, что будет использоваться пользовательский тип анализа на ускорителе, используется ключ "–collect-with runsa-knc". Конкретные события, результаты по которым вы хотите получить, описаны в качестве параметров ключа "–knob event-config=…". Используемые здесь имена событий описаны по ссылке [1.10].
Напомним, что нужный вам тип анализа можно настроить через GUI приложение, после чего там же получить командную строку для его запуска. Описание дополнительных аргументов приложения ample-cl можно узнать из его справки:
amplxe-cl –help
Просмотр результатов анализа, полученных после запуска профилировщика из командной строки, может быть осуществлен двумя методами.
Первый метод предполагает использование GUI приложения. Вам нужно скопировать результаты анализа с удаленной на локальную машину с GUI, после чего открыть файл *.amplxe с помощью GUI приложения Intel VTune Amplifier XE. Отметим, что это предпочтительный метод работы с результатами, так как он является наиболее удобным и наглядным.
Второй метод использует исключительно возможности командной строки.
Для просмотра общей статистики по конкретному запуску необходимо выполнить команду:
amplxe-cl –report summary –r ./offload_cmd/
Здесь "./offload_cmd/" это директория с результатами анализа. Ключ "-report" указывает на тип выводимой информации. Например, если мы хотим получить список наиболее медленных функций, тогда нужно запросить вывод данных о "горячих точках":
amplxe-cl –report hotspots –r ./offload_cmd/
Еще один вариант – получение информации об аппаратных событиях, произошедших за время работы приложения:
amplxe-cl –report hw-events –r ./offload_cmd/
Результаты выдачи можно фильтровать по имени процесса или модуля:
amplxe-cl –report hotspots –filter process=offload_main –filter module=offload.out –r ./offload_cmd/
Можно записывать выдачу в файл:
amplxe-cl –report hotspots –report-output ./vtune-output.txt –r ./offload_cmd/